SQL优化经验
在项目压测阶段(多张业务主表数量达亿级),很多人都会碰到平时明明秒级响应的请求,现在却经常得到的响应是504 gateway timeout…这是因为在大数据的前提下,暴露了很多慢SQL,现在我就项目中遇到的一些情况以及对应的优化方案进行简要分享。
首先定位到查询语句,可以通过工具,如pinpoint可以很方便找到慢sql,也可以自己凭业务逻辑定位到查询sql,然后用 EXPLAIN 你的 SELECT 查询。
使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。
EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。
type列,连接类型。一个好的SQL语句至少要达到range级别。杜绝出现all级别。
key列,使用到的索引名。如果没有选择索引,值是NULL。可以采取强制索引方式。key_len列,索引长度。
rows列,扫描行数。该值是个预估值。
extra列,详细说明。注意,常见的不太友好的值,如下:Using filesort,Using temporary。
举个栗子

如果发现type类型为all的,或者扫描的行数很大的情况,就需要注意一下了。所谓sql优化就是尽可能减少扫描的行数,行数少了,自然就快了。
进入正题之前,先对比熟悉几个常用关键字
exists和in
select * from A
where id in(select id from B)
以上查询使用了in语句,in()只执行一次,它查出B表中的所有id字段并缓存起来.之后,检查A表的id是否与B表中的id相等,如果相等则将A表的记录加入结果集中,直到遍历完A表的所有记录.
它的查询过程类似于以下过程
List resultSet=[];
Array A=(select * from A);
Array B=(select id from B);
for(int i=0;i可以看出,当B表数据较大时不适合使用in(),因为它会B表数据全部遍历一次.
如:A表有10000条记录,B表有1000000条记录,那么最多有可能遍历100001000000次,效率很差.
再如:A表有10000条记录,B表有100条记录,那么最多有可能遍历10000100次,遍历次数大大减少,效率大大提升.
select a.* from A a
where exists(select 1 from B b where a.id=b.id)
以上查询使用了exists语句,exists()会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是结果集中是否有记录,如果有则返回true,没有则返回false.
它的查询过程类似于以下过程
List resultSet=[];
Array A=(select * from A)
for(int i=0;i当B表比A表数据大时适合使用exists(),因为它没有那么遍历操作,只需要再执行一次查询就行.
如:A表有10000条记录,B表有1000000条记录,那么exists()会执行10000次去判断A表中的id是否与B表中的id相等.
如:A表有10000条记录,B表有100000000条记录,那么exists()还是执行10000次,因为它只执行A.length次,可见B表数据越多,越适合exists()发挥效果.
再如:A表有10000条记录,B表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历比较,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快.
结论:
in()适合B表比A表数据小的情况
exists()适合B表比A表数据大的情况
当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用.
left join 和join
left join为什么会比 inner join 慢?
1、关于逻辑运算量
关于left join的概念,大家是都知道的(返回左边全部记录,右表不满足匹配条件的记录对应行返回null),那么单纯的对比逻辑运算量的话,inner join 是只需要返回两个表的交集部分,left join多返回了一部分左表没有返回的数据。
2、关于mysql连接的算法 Nest Loop Join(嵌套联接循环)
这个算法是mysql默认的连接算法,
(foreach a as v){
(foreach b as v1){
(foreach c as v2){
}
}
}
从算法上来看,根据mysql文档,inner join在连接的时候,mysql会自动选择较小的表来作为驱动表,从而达到减少循环次数的目的。我们在使用left join表的时候,默认是使用左表作为驱动表,那么此时左表的大小是我们来控制的,如果控制不当,左表比较大,那么自然循环次数也会变多,效率会下降。
接下来,介绍几个具体的对sql优化的实例
如何在NOT EXISTS和LEFT JOIN中选择
SELECT
xxxx
FROM
hscs_ar_receipt_headers harrh
WHERE EXISTS (
SELECT
1
FROM
hscs_ar_receipt_lines harrl
WHERE
harrl.RECEIPT_HEADER_ID = harrh.RECEIPT_HEADER_ID
AND harrl.RECEIPT_LINE_TYPE = 'RECEIVEBILL'
AND harrl.RECEIPT_DOCUMENT_ID = - 115001
);
这个sql耗时5 min 19.60 sec,显然太慢了。。
先看一下头行表的总数量
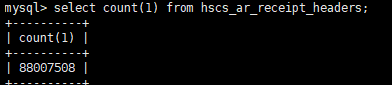

hscs_ar_receipt_headers 表(后面我们称此表为A表):88007508
hscs_ar_receipt_lines表(后面我们称此表为B表):70014998
再看一下执行计划

走的是索引,但是却扫描了85806552行
外层为大表,里层为小表的情况,显然用exists是不合适的,无论是否有索引,扫描的行数太多,就会直接导致耗时过长。
将上面sql改为
SELECT
xxxx
FROM
hscs_ar_receipt_headers harrh
LEFT JOIN hscs_ar_receipt_lines harrl ON harrh.RECEIPT_HEADER_ID = harrl.RECEIPT_HEADER_ID
WHERE
harrl.RECEIPT_LINE_TYPE = 'RECEIVEBILL'
AND harrl.RECEIPT_DOCUMENT_ID = - 115001
耗时0.00 sec,比前面exists的方式性能提示n倍
同样的,我们看一下执行计划

从执行计划来看,两个表都使用了索引,区别在于 EXISTS使用“DEPENDENT SUBQUERY”方式,而LEFT JOIN使用普通表关联的方式
1、当外层数据较少时,子查询循环次数较少,使用NOT EXISTS并不会导致严重的性能问题,推荐使用NOT EXISTS方式。
2、当外层数据较大时,子查询消耗随外层数据量递增,查询性能较差,推荐使用LEFT JOIN方式
按照存在即合理是客观唯心主义的理论,NOT EXISTS以更直观地方式实现业务需求,在SQL复杂度上要远低于LEFT JOIN,且在生产执行计划时,NOT EXISTS方式相对更稳定些,LEFT JOIN可能会随统计信息变化而生产不同的执行计划。
关于索引
提升查询速度的方向一是提升硬件(内存、cpu、硬盘),二是在软件上优化(加索引、优化sql;优化sql不在本文阐述范围之内)。
能在软件上解决的,就不在硬件上解决,毕竟硬件提升代码昂贵,性价比太低。代价小且行之有效的解决方法就是合理的加索引。
索引使用得当,能使查询速度提升上万倍,效果惊人。
单列索引和组合索引
单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引;
组合索引,即一个索包含多个列。
能用组合索引就不要使用多个单列索引,首先单列索引会增加索引文件所占空间,其次多个单列索引的效率远低于组合索引,虽然看似有了多个单列索引,但MySQL只能用到其中的那个它认为似乎是最有效率的单列索引。
何时建索引
到这里我们已经学会了建立索引,那么我们需要在什么情况下建立索引呢?
最简单的方法就是为搜索字段建索引 。
一般来说,在WHERE和JOIN中出现的列需要建立索引,但也不完全如此,因为MySQL只对<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE才会使用索引。例如: SELECT t.name FROM mytable t LEFT JOIN mytable m ON t.name=m.username WHERE m.age=20 AND m.city=‘郑州’ 此时就需要对city和age建立索引,由于mytable表的 userame也出现在了JOIN子句中,也有对它建立索引的必要。 刚才提到只有某些时候的LIKE才需建立索引。因为在以通配符%和_开头作查询时,MySQL不会使用索引。例如下句会使用索引: SELECT * FROM mytable WHERE username like’admin%’ 而下句就不会使用: SELECT * FROM mytable WHEREt Name like’%admin’ 因此,在使用LIKE时应注意以上的区别。
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。会提高很多的性能。
另外,你应该也需要知道什么样的搜索是不能使用正常的索引的。例如,当你需要在一篇大的文章中搜索一个词时,如: “WHERE post_content LIKE ‘%apple%’”,索引可能是没有意义的。你可能需要使用MySQL全文索引 或是自己做一个索引(比如说:搜索关键词或是Tag什么的)
需要注意的是,索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
合理使用索引
在实际业务中,还可以通过一些手段进行控制,比如将某个别明显能将数据分类的查询字段设置为必输,然后在这个字段上建立索引,这样设计的话,就算后续数据量上去,也能减少出现504的可能性。(当然了,这种方式需要用户同意才行,毕竟这是以增加用户使用繁琐度来换取性能的。。)
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。
而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)
综上归纳:
a、不要过度索引。索引本质上是以空间换时间,索引越多,占用空间越大,反而性能变慢;
b.只对WHERE子句中频繁使用的建立索引;
c.尽可能使用唯一索引,重复值越少,索引效果越强;
d.使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
e.充分利用左前缀,这是针对复合索引,因为WHERE语句如果有AND并列,只能识别一个索引(获取记录最少的那个),索引需要使用复合索引,那么应该将WHERE最频繁的放置在左边。
f.不建议使用%前缀模糊查询
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引
g.索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有 NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
g.索引存在,如果没有满足使用原则,也会导致索引无效:
给个例子
加索引之前
![]()
在查询字段上加上索引之后

很明显的性能提升。
合理使用分页
一般的业务需求中,都是可以通过分页来实现的,使用分页的话,可以大大提高效率。
同理,当你查询表的有些时候,如果你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
但是使用select id,name from product limit 866613, 20 SQL语句做分页的时候,可能有人会发现,随着表数据量的增加,直接使用limit分页查询会越来越慢。
优化的方法如下:可以取前一页的最大行数的id,然后根据这个最大的id来限制下一页的起点。比如此列中,上一页最大的id是866612。SQL可以采用如下的写法:
select id,name from a where id> 866612 limit 20