kettle支持kerberos认证的hive集群
Kettle对接指南
1.1 环境准备
1.1.1 Linux平台
安装操作系统
步骤 1 安装CentOS6.5 Desktop。
步骤 1 禁用防火墙,SELinux。
步骤 2 添加本地主机名解析,使用vi /etc/hosts添加本地主机名解析。
162.1.115.89 kettle
----结束
步骤 1 下载完整客户端,安装至目录“/opt/hadoopclient”。
步骤 3 使用vi /etc/profile编辑以下内容插入到文件末尾。
source /opt/hadoopclient/bigdata_env
步骤 4 将krb5.conf放在“/etc”目录下。
cp /opt/hadoopclient/KrbClient/kerberos/var/krb5kdc/krb5.conf /etc/
----结束
1.1.1 Windows平台
步骤 1 安装JDK1.8。
步骤 1 配置系统环境变量。
JAVA_HOME= C:\\Program Files\\Java\\jdk1.8.0_112
步骤 2 在PATH环境变量添加 %JAVA_HOME%\bin;%JAVA_HOME%\jre\bin。
右键点击桌面计算机,选择“属性”,点击选择“高级系统设置 > 高级选项卡”,点击“环境变量”,在下方“系统变量”中查找“Path”,双击“Path”将 %JAVA_HOME%\bin;%JAVA_HOME%\jre\bin添加到最左边并添加分号,确定。
步骤 3 获取Kerberos配置文件。
步骤 5 解压后得到Kerberos配置文件krb5.conf和用户密钥文件user.keytab。
步骤 6 将krb5.conf文件复制“C:\Windows”目录下,重命名为krb5.ini。
步骤 7 添加系统环境变量KRB5_CONFIG(可选步骤)。
KRB5_CONFIG=C:\Windows
----结束
1.1 配置并启动Kettle
步骤 1 从以下地址https://sourceforge.net/projects/pentaho/files/Data%20Integration/下载Kettle6.1版本。
只支持kettle 6.1.0.1-196版本。
步骤 1 解压得到“data-integration”目录。
步骤 2 替换pentaho-big-data-plugin下的配置文件。
l 下载FusionInsightHD客户端并解压。
l 用解压目录下Hive/jdbc-examples/conf/core-site.xml文件。
l 替换data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations/hdp23目录下的core-site.xml文件。
步骤 3 替换Hive相关jar包。
将data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations/hdp23/lib下的hive相关的jar包。
替换成Hive客户端下“jdbc-examples/lib”目录下的以下jar包
步骤 4 获取用户keytab文件。
在FI管理界面下载用户的keytab文件到本地。
步骤 5 Kerberos认证(可选步骤)。
在对接Hive时,可以使用本地缓存的认证票据,或者在jdbc URL中指定principal和keytab文件进行认证(对接HDFS时,只能使用本地缓存的票据)。
如果使用本地缓存的票据,需要在启动kettle前先完成认证。
使用本地缓存票据存在以下问题:kettle只在启动时读取一次票据,而不是连接时实时读取当前票据信息,所以当kettle启动时获取的票据过期以后,连接Hive会失败,必须重启kettle。
步骤 6 启动kettle。
l Linux平台
VNC登录CentOS桌面,打开Terminal。
cd /opt/data-integration/
./spoon.sh
l Windows平台
双击“data-integration”目录下的Spoon.bat。
----结束
1.2 对接Hive
1.1.1 创建Hive连接
步骤 1 选择 “文件 > 新建 > 转换” 。
步骤 1 单击“主对象树”页签,在页签中选择“转换 > DB连接”,右键选择 “新建”。
步骤 2 连接类型选择Hive 2,填写主机名、端口号、数据库名。
步骤 3 单击左侧选项,如果使用本地缓存票据,填写以下参数:
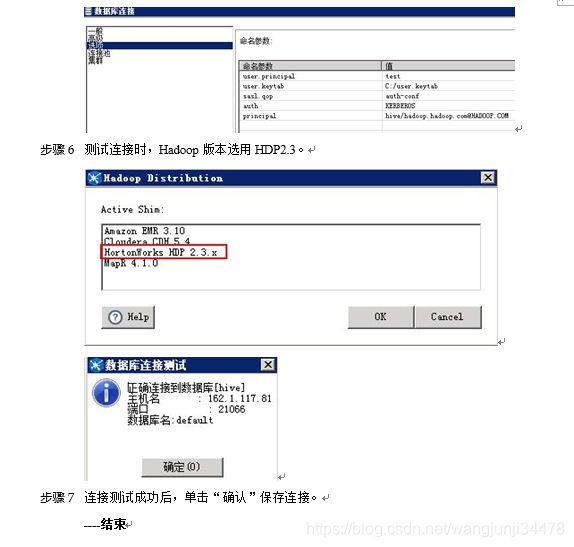
步骤 4 如果要在连接Hive时使用keytab文件认证,增加user.principal和user.keytab两个参数。
步骤 5 测试连接时,Hadoop版本选用HDP2.3。
步骤 6 连接测试成功后,单击“确认”保存连接。
----结束
1.2.1 读取Hive数据
以hive > postgresql为例
步骤 1 将6.3.1 创建Hive连接创建的转换保存为hive2postgres.ktr。
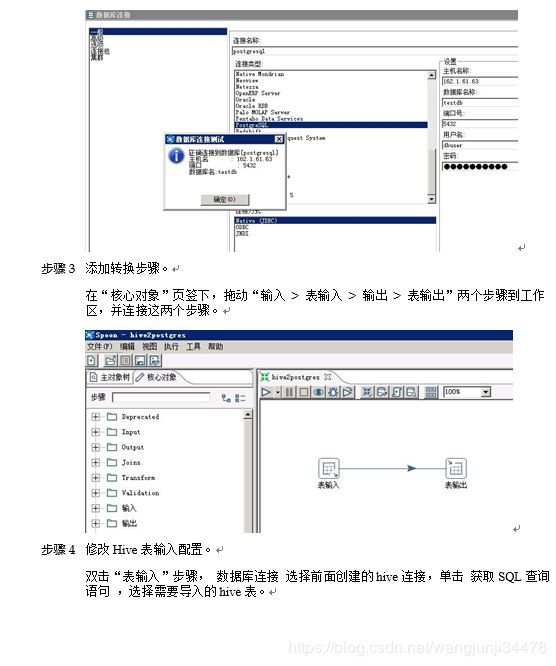
步骤 1 创建postgresql连接。
步骤 2 添加转换步骤。
在“核心对象”页签下,拖动“输入 > 表输入 > 输出 > 表输出”两个步骤到工作区,并连接这两个步骤。
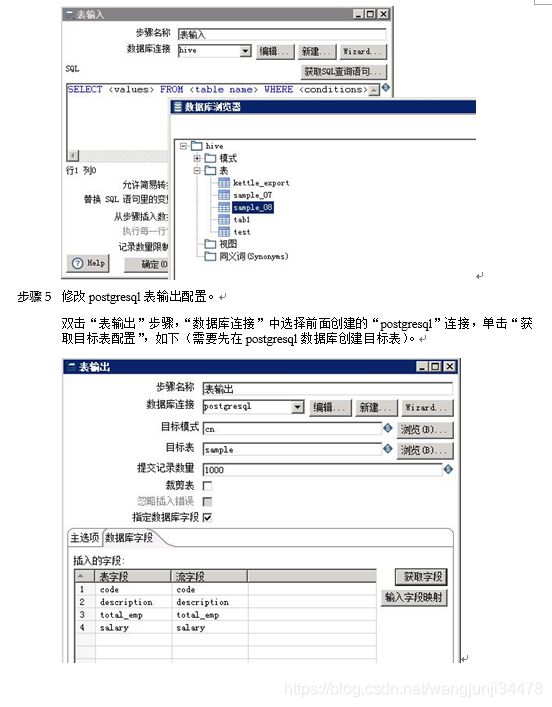
步骤 3 修改Hive表输入配置。
双击“表输入”步骤, 数据库连接 选择前面创建的hive连接,单击 获取SQL查询语句 ,选择需要导入的hive表。
步骤 4 修改postgresql表输出配置。
双击“表输出”步骤,“数据库连接”中选择前面创建的“postgresql”连接,单击“获取目标表配置”,如下(需要先在postgresql数据库创建目标表)。
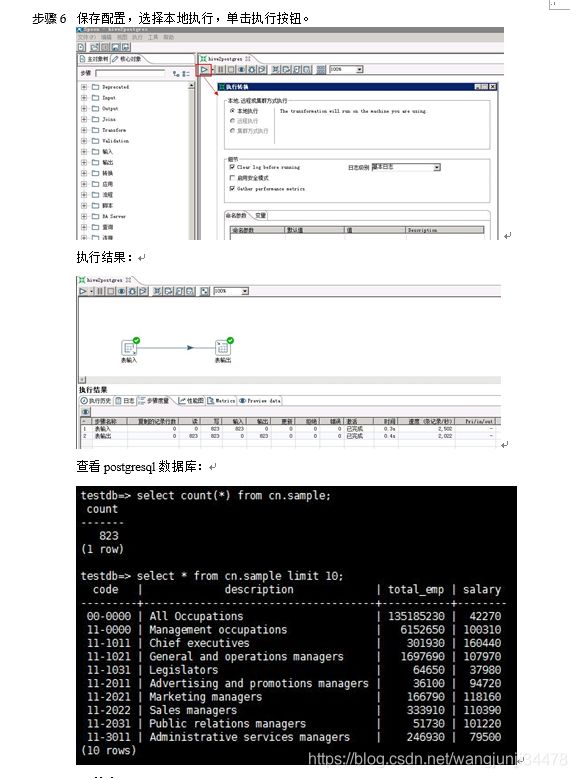
步骤 5 保存配置,选择本地执行,单击执行按钮。
执行结果:
查看postgresql数据库:
----结束
1.2.2 写入Hive数据
以oracle > hive为例
步骤 1 添加Oracle JDBC Driver。
步骤 1 从http://www.oracle.com/technetwork/database/features/jdbc/index-091264.html 下载对应版本的jdbc Driver,放到“data-integration/lib”目录下,重启kettle。
步骤 2 新建转换,保存为oracle2hive.ktr。
步骤 3 创建Oracle连接。
步骤 4 参考6.3.1 创建Hive连接章节创建待导入的Hive表。
CREATE TABLE IF NOT EXISTS kettle_export (
id int,
name string
);
步骤 5 添加转换步骤。
步骤 6 修改步骤配置 。
步骤 7 Oracle表输入配置。
步骤 8 Hive表输出配置
步骤 9 保存配置,选择本地执行,单击执行按钮。
执行结果:向Hive表写入13条数据,用时4min+。







查看Hive表数据:
向Hive表中写入数据,每插入一条数据会起一个MR任务,所以效率特别低,不推荐用这种方式,可以将数据写入HDFS文件。
----结束