机器学习项目实战——集成预测政治献金
政治献金预测
- 数据预处理
- 定义绘制决策树的方法
- 绘制决策树
- 使用多个模型集成
- 绘制roc曲线
- 实现集成
- 交叉验证训练基学习器
- 多线程
# 导入相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import os
os.environ['PATH'] += ';...\\Graphviz2.38\\bin' # Graphviz 临时环境变量
数据预处理
### 导入数据
# 设置随机种子
SEED = 222
np.random.seed(SEED)
df = pd.read_csv(r'...\data\federal_giving.csv', low_memory=False)
# 去除整列值相同的列
df = df.loc[:, (df != df.iloc[0]).any()]
feature_columns = ['entity_tp', 'classification', 'rpt_tp', 'cycle',
'transaction_amt', 'state', 'transaction_tp']
### 训练集和测试集
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
def get_train_test(test_size=0.95): # 速度快方便学习
"""划分训练集测试集"""
y = 1 * (df['cand_pty_affiliation'] == "REP") # 映射 REP:1, 非REP:0
X = df[feature_columns].copy()
# 填充空值 mode()众数
for col in ['cycle', 'entity_tp', 'state']:
X[col].fillna(X[col].mode()[0], inplace=True)
X = pd.get_dummies(X, sparse=True) # 独热编码,内存要求高
return train_test_split(X, y, test_size=test_size, random_state=SEED)
xtrain, xtest, ytrain, ytest = get_train_test()
特征值说明
- entity_tp: 个人还是组织
- classification: 领域
- rpt_tp: 贡献的大小
- cycle: 捐赠年份
- transaction_amt: 捐赠金额
- state: 州
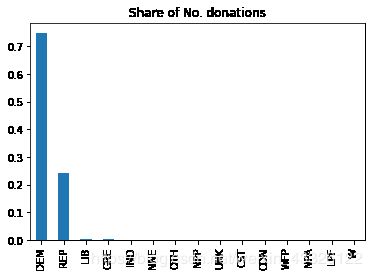
查看目标值的种类和数量
df['cand_pty_affiliation'].value_counts(normalize=True).plot(
kind="bar", title="Share of No. donations")
plt.show()
定义绘制决策树的方法
import pydotplus
from IPython.display import Image
from sklearn.metrics import roc_auc_score
from sklearn.tree import DecisionTreeClassifier, export_graphviz
def print_graph(dtr, feature_names):
"""绘制决策树"""
graph = export_graphviz(dtr, label="root", proportion=True, impurity=False,
out_file=None, feature_names=feature_names, class_names={0: "D", 1: "R"},
filled=True, rounded=True)
graph = pydotplus.graph_from_dot_data(graph)
return Image(graph.create_png())
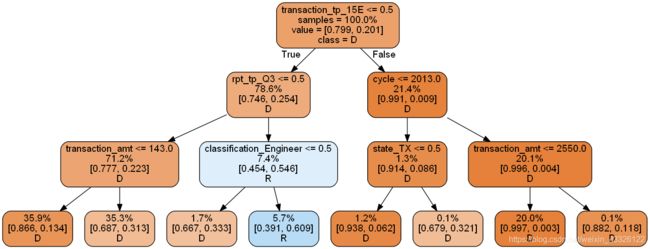
绘制决策树
# 创建最大深度3的决策树对象
dtr1 = DecisionTreeClassifier(max_depth=3, random_state=SEED)
dtr1.fit(xtrain, ytrain)
# 预测概率值
p1 = dtr1.predict_proba(xtest)[:, 1]
# 决策树的 ROC-AUC 得分
print("Decision tree ROC-AUC score: %.3f" % roc_auc_score(ytest, p1))
# 绘制决策树
print_graph(dtr1, xtrain.columns)
Decision tree ROC-AUC score: 0.747
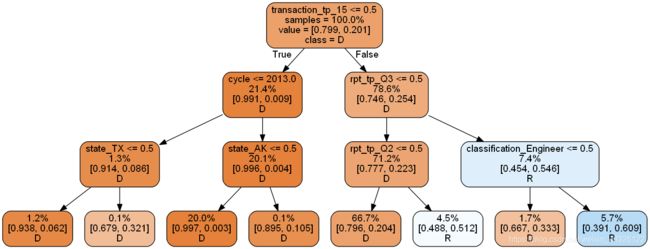
去掉影响最大的因素再绘制一次决策树
xtrain_slim = xtrain.drop('transaction_amt', 1)
xtest_slim = xtest.drop('transaction_amt', 1)
# 创建决策树对象
dtr2 = DecisionTreeClassifier(max_depth=3, random_state=SEED)
dtr2.fit(xtrain_slim, ytrain)
# 预测概率值
p2 = dtr2.predict_proba(xtest_slim)[:, 1]
# 决策树的 ROC-AUC 得分
print("Decision tree ROC-AUC score: %.3f" % roc_auc_score(ytest, p2))
# 绘制决策树
print_graph(dtr2, xtrain_slim.columns)
Decision tree ROC-AUC score: 0.708
将上面两个决策树平均求得分
p = np.mean([p1, p2], axis=0)
print("Average of decision tree ROC-AUC score: %.3f" % roc_auc_score(ytest, p))
Average of decision tree ROC-AUC score: 0.763
多选几组就是随机森林
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=10, max_features=3, random_state=SEED)
rf.fit(xtrain, ytrain)
p = rf.predict_proba(xtest)[:, 1]
print("Random forest ROC-AUC score: %.3f" % roc_auc_score(ytest, p))
Random forest ROC-AUC score: 0.830
使用多个模型集成
from sklearn.svm import SVC, LinearSVC
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.kernel_approximation import Nystroem
from sklearn.kernel_approximation import RBFSampler
from sklearn.pipeline import make_pipeline
def get_models():
nb = GaussianNB() # 朴素贝叶斯
svc = SVC(C=100, probability=True) # 支持向量机
knn = KNeighborsClassifier(n_neighbors=3) # k近邻
lr = LogisticRegression(C=100, random_state=SEED) # 逻辑回归
nn = MLPClassifier((80, 10), early_stopping=False, random_state=SEED) # 神经网络
gb = GradientBoostingClassifier(n_estimators=100, random_state=SEED) # 梯度提升
rf = RandomForestClassifier(n_estimators=10, max_features=3, random_state=SEED) # 随机森林
models = {
'svm': svc,
'knn': knn,
'naive bayes': nb,
'mlp-nn': nn,
'random forest': rf,
'gbm': gb,
'logistic': lr,
}
return models
def train_predict(model_list):
"""遍历模型 完成fit, predict_proba"""
# 不同模型的预测概率值的容器
P = pd.DataFrame(np.zeros((ytest.shape[0], len(model_list))))
cols = []
for i, (name, model) in enumerate(models.items()):
# i 序号, name 模型名称, m 模型实例
print("%s..." % name, end=" ")
model.fit(xtrain, ytrain)
P.iloc[:, i] = model.predict_proba(xtest)[:, 1]
cols.append(name)
# 参考用时,svm: 15m33s, knn: 1m49s, nb: 2s, mlp-nn=12s, rf: 3s, gbm: 7s, lr: 2s
print("done")
P.columns = cols
return P
def score_models(P, y):
"""计算模型分数"""
for name in P.columns:
score = roc_auc_score(y, P.loc[:, name])
print("%-26s: %.3f" % (name, score))
models = get_models()
P = train_predict(models)
score_models(P, ytest)
# 集成的简单平均分数
print("Ensemble ROC-AUC score : %.3f" % roc_auc_score(ytest, P.mean(axis=1)))
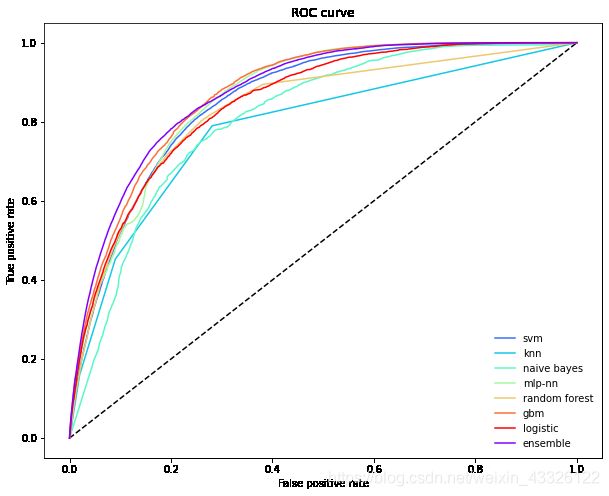
svm : 0.854
knn : 0.785
naive bayes : 0.810
mlp-nn : 0.862
random forest : 0.830
gbm : 0.872
logistic : 0.847
Ensemble ROC-AUC score : 0.875
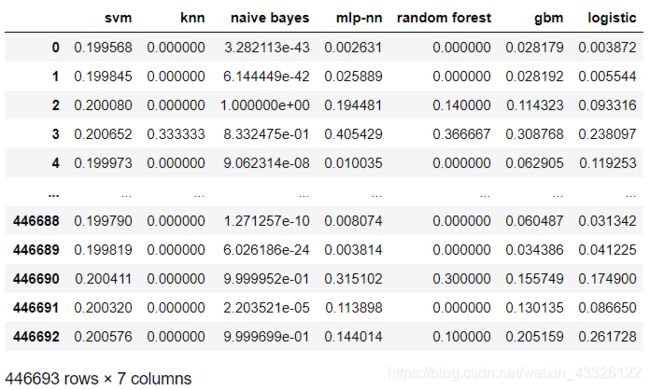
P
绘制roc曲线
from sklearn.metrics import roc_curve
def plot_roc_curve(ytest, P_base_learners, P_ensemble, labels, ens_label):
"""绘制基学习器和集成的roc曲线"""
plt.figure(figsize=(10, 8))
plt.plot([0, 1], [0, 1], 'k--')
cm = [plt.cm.rainbow(i)
for i in np.linspace(0, 1.0, P_base_learners.shape[1] + 1)]
for i in range(P_base_learners.shape[1]):
p = P_base_learners[:, i]
fpr, tpr, _ = roc_curve(ytest, p)
plt.plot(fpr, tpr, label=labels[i], c=cm[i + 1])
fpr, tpr, _ = roc_curve(ytest, P_ensemble)
plt.plot(fpr, tpr, label=ens_label, c=cm[0])
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve')
plt.legend(frameon=False)
plt.show()
plot_roc_curve(ytest, P.values, P.mean(axis=1), list(P.columns), "ensemble")
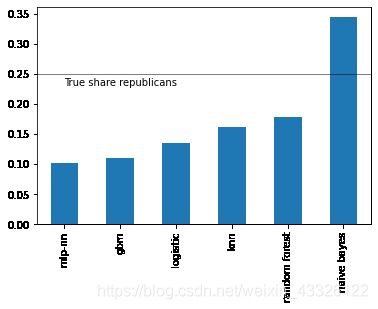
各学习器预测共和党捐款比例
p = P.apply(lambda x: 1*(x >= 0.5).value_counts(normalize=True))
p.index = ["DEM", "REP"]
p.loc["REP", :].sort_values().plot(kind="bar")
plt.axhline(0.25, color="k", linewidth=0.5)
plt.text(0., 0.23, "True share republicans")
plt.show()
实现集成
import time
# 将训练集分为基学习器的训练集和预测集
xtrain_base, xpred_base, ytrain_base, ypred_base = train_test_split(
xtrain, ytrain, test_size=0.5, random_state=SEED)
def train_base_learners(base_learners, xtrain, ytrain, verbose=True):
"""训练所有基学习器
base_learners: 基学习器集合
xtrain, ytrain: 训练集
verbost: 是否输出消息
"""
for i, (name, model) in enumerate(base_learners.items()):
if verbose: print("%s训练中..." % name, end=" ", flush=False)
start_time = time.time()
model.fit(xtrain, ytrain)
if verbose: print("耗时: %ds" % (time.time()-start_time))
def predict_base_learners(pred_base_learners, xtest, verbose=True):
"""生成预测概率
pred_base_learners: 基学习器集合
xtest: 预测用的测试集
"""
# 初始化预测结果的矩阵
P = np.zeros((xtest.shape[0], len(pred_base_learners)))
for i, (name, model) in enumerate(pred_base_learners.items()):
if verbose: print("%s预测中..." % name, end=" ", flush=False)
start_time = time.time()
P[:, i] = model.predict_proba(xtest)[:, 1]
if verbose: print("耗时: %ds" % (time.time()-start_time))
return P
def ensemble_predict(base_learners, meta_learner, inp, verbose=True):
"""集成预测"""
P_pred = predict_base_learners(base_learners, inp, verbose=verbose)
return P_pred, meta_learner.predict_proba(P_pred)[:, 1]
# 创建基学习器
base_learners = get_models()
# 训练基学习器
train_base_learners(base_learners, xtrain_base, ytrain_base)
# 创建元学习器
meta_learner = GradientBoostingClassifier(
n_estimators=1000,
loss="exponential",
max_features=4,
max_depth=3,
subsample=0.5,
learning_rate=0.005,
random_state=SEED
)
# 训练元学习器
print("元学习器训练中...", end=" ", flush=False)
start_time = time.time()
meta_learner.fit(P_base, ypred_base)
print("耗时: %ds" % (time.time()-start_time))
# 生成集成的预测
P_pred, p = ensemble_predict(base_learners, meta_learner, xpred_base)
print("Ensemble ROC-AUC score: %.3f" % roc_auc_score(ypred_base, p))
Ensemble ROC-AUC score: 0.901
交叉验证训练基学习器
由于只对部分数据训练,造成大量信息丢失
使用交叉验证训练解决这问题
from sklearn.base import clone
from sklearn.model_selection import KFold
def stacking(base_learners, meta_learner, X, y, generator):
"""Simple training routine for stacking.
base_learners: 基学习器
meta_learner: 元学习器
X, y: 数据
generator: KFold对象
return 基学习器, 元学习器
"""
# Train final base learners for test time
# 训练全部数据
print("Fitting final base learners...", end="")
train_base_learners(base_learners, X, y, verbose=False)
print("done")
# Generate predictions for training meta learners
# Outer loop:
print("Generating cross-validated predictions...")
cv_preds, cv_y = [], []
for i, (train_idx, test_idx) in enumerate(generator.split(X)):
# 划分数据
fold_xtrain, fold_ytrain = X[train_idx, :], y[train_idx]
fold_xtest, fold_ytest = X[test_idx, :], y[test_idx]
# Inner loop: step 4 and 5
# 将训练了全部数据的模型复制,再交叉验证训练
fold_base_learners = {name: clone(model)
for name, model in base_learners.items()}
train_base_learners(
fold_base_learners, fold_xtrain, fold_ytrain, verbose=False)
fold_P_base = predict_base_learners(
fold_base_learners, fold_xtest, verbose=False)
cv_preds.append(fold_P_base)
cv_y.append(fold_ytest)
print("Fold %i done" % (i + 1))
print("CV-predictions done")
# 训练元学习器,需要基学习器的预测结果和测试集
print("Fitting meta learner...", end="")
meta_learner.fit(np.vstack(cv_preds), np.hstack(cv_y))
print("done")
return base_learners, meta_learner
# Train with stacking
cv_base_learners, cv_meta_learner = stacking(
get_models(), clone(meta_learner), xtrain.values, ytrain.values, KFold(3))
P_pred, p = ensemble_predict(cv_base_learners, cv_meta_learner, xtest, verbose=False)
print("\nEnsemble ROC-AUC score: %.3f" % roc_auc_score(ytest, p))
Ensemble ROC-AUC score: 0.904
多线程
使用mlens库的SuperLearner
from mlens.ensemble import SuperLearner
# 实例化SuperLearner
sl = SuperLearner(
folds=10,
random_state=SEED,
verbose=2,
backend="multiprocessing"
)
# 添加基学习器和元学习器
sl.add(list(base_learners.values()), proba=True)
sl.add_meta(meta_learner, proba=True)
# 训练集成
sl.fit(xtrain, ytrain)
# 概率预测
p_sl = sl.predict_proba(xtest)
print("\nSuper Learner ROC-AUC score: %.3f" % roc_auc_score(ytest, p_sl[:, 1]))