卷积神经网络 + 机器视觉: L6_初始化_激励函数_BN_梯度下降 (斯坦福CS231n)
完整的视频课堂链接如下:
- https://www.youtube.com/watch?v=wEoyxE0GP2M&index=6&list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
完整的视频课堂投影片连接:
- http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture6.pdf
前一課堂筆記連結:
- 卷积神经网络 + 机器视觉: L5_卷积层_Pooling Mechanism (斯坦福课堂)
Menu this round:
- activation function
- data processing
- weight initialization
- batch normalization
- babysitting the learning process
- hyperparameter optimization
第六节主要讨论的是如何让神经网络自动的去学习权重值 weight 该沿着怎么样的梯度下降去得到最优解。Gradient Descent (我自己简称 GD)通过微分取最小值的方式处理方程式,是目前最有效的找解方案,而这个找解的过程也有叫做 optimization。
而 GD 在这里操作的整个过程全名又叫做 Mini-Batch sarcastic gradient descent (SGD),叫做 mini-batch 的原因是因为每次都只找 “一小撮” 数据作为参考去预测更优的值,虽然这样不全面,但是可以很大的减小电脑计算资源和负担,还是利大于弊的。方法步骤如下:
1. 拿出一小撮数据作为 sample
2. 把这些数据逐一代入 Loss Function 模型中,得到 loss 值
3. 反向传播 Backpropagate 去算出梯度 gradient
4. 沿着梯度 有效的更新参数
Activation Function

它就像一个自然界中的神经元原理,从外部接受了一个外界刺激,经过内部的激励反应运作,最后从右边得出一个输出信号。
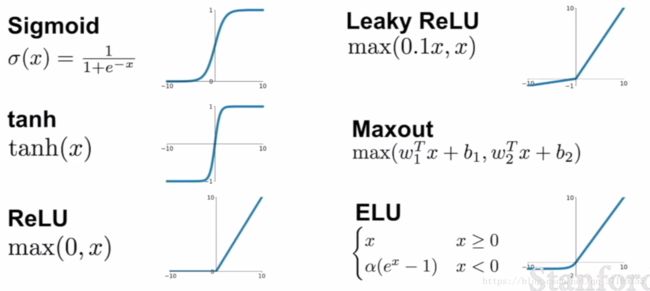
上图是我们常用的激励函数总览,不同的情况适用不同的激励方法取实践,但是各个激励函数也有彼此的优劣地方,以下介绍。
Sigmoid
从发展史来看,这个方法受欢迎的时间很久,可以很简单的用一个 function 去描述一个 0 与 1 的开关,但是随着运算的发展,它的问题也逐渐暴露:
- 一旦输入值过大或是过小进入了图中躺平的线段,它就扼杀了原本数据中应该呈现出来的梯度(或是可以说它抹平了数据本该有的差异),数据最珍贵的就是他们的差异啦,被这样一抹还得了,要是多做几次神经传递,那大家都一样了,容易失真。
- 它不是一个 “zero-centered” 的函数类型,白话文就是,不论 x 值大于或是小于 0 ,输出值都是正的,这件事情本身不是个问题,问题会在传递到下一个神经层的时候浮现,这一轮的 output 会作为下一层的 input 被输入,如果所有的 input 都是正的,那么她们在做 GD 计算 Backprop 的时候肯定得出来的值要不全都是正的或是都是负的,造成权重值在更新的时候只能沿着一个维度做锯齿状步进,是个很没效率的方式。
- 说到计算本身,实际应用中计算资源宝贵,Sigmoid 出现了 exp() 意味着它将占据大量的资源和效率,当应用在庞大的深度学习的时候,差距就看出来了。
tanh
这个 function 跟 Sigmoid 类似,不过少了第二项的缺点,并且没有 exp() 的运算,但是他仍然有抹平梯度的问题,需要很小心的做初始化 initialization 才能让所有的 data 不陷入梯度消失的区域(initialization 后面提及)。
ReLU
前面几堂课中使用的方法就是此法,它结合了几种优点于一身,是一个目前我们最常用的激励函数,原因如下:
- 它在 “第一象限” 中是不会出现梯度被磨平的情况的,保留数据之间最珍贵的差异化。
- 它计算的时候没有 exp() 项,意味着不占用资源,实际角度看它的速度是 sigmoid/tanh 的六倍快。
- 从仿生的生物角度来看,它也比 sigmoid 更有说服力
但是它还是有 Sigmoid 第二项缺点,这也意味着如果初始参数没有妥善的被设定,或是学习效率调的太高了,那么 ReLU 就会因为这个缺点,慢慢的跳出数据分布的地方,并且永远无法随着梯度更新回来,因此 Leaky ReLU 被发明出来,一劳永逸。
Leaky ReLU
结合了上面的所有优点,并且屏蔽了所有的缺点,好处我重新列一遍:
- 它不抹平数据差异
- 计算起来非常高效迅速
- 它不会像 ReLU 那样需要妥当的初始化,不然会直接死掉
Exopnential Linear Units (ELU)
这个方法介于 ReLU 与 Leaky ReLU 之间,用上了 exp() 拖慢了速度,并且虽然它也是 zero-centered 的特征,但负得太离谱的情况差异还是被抹平了,因此主要还是看实际应用情况而选择方法。
Maxout
从公式看上去,它结合了两种方法,经过两种方法得出来的值比较后,取其中最大的值作为结果输出,虽然这样也有效的结合了各种方法的优点,但是对于一个数据来说,算两遍意味着 “吃资源” 不是我们鼓励的做法,速度也是直接砍一半。
经验总结
1. 一般适用 ReLU,但是小心调整学习效率 learning rate 的参数。
2. 搭配着可以试试看 Leaky ReLU / ELU / Maxout 看哪一个方法在当下模型表现最好
3. 可以试试看 tanh 但是别期待什么好结果,而 sigmoid 就别用了哈
Data Preprocessing
当我们面对一些数据要用到 machine learning 的方法处理时,我们一般会先让数据整体分布对齐坐标轴中心,再 normalize 这些数据(把原本离散的数据点,浓缩到 0 与 1)的范围。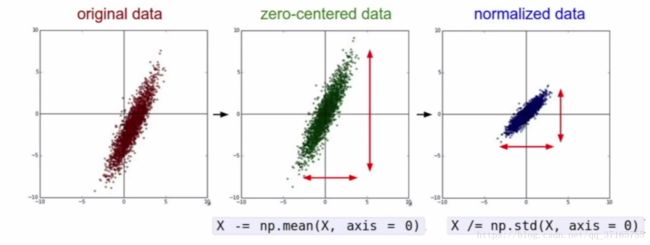
对于图片 pixel 的数据而言,虽然我们也做 zero-centered 的处理,但是一般不做太复杂的事前处理,包含了 normalization,因为对于图片处理,我们使用的是 Convolution 的方式,并得出 local 的空间结构与特征。
再者,不做过于复杂的预处理原因是我们不希望让 pixel value 被投射到一个低维度的空间去,损失特征对图像识别来说不是什么好事。因此,对于图片的 normalization 我们只做到让不同权重之间的影响因子大小一样,如图: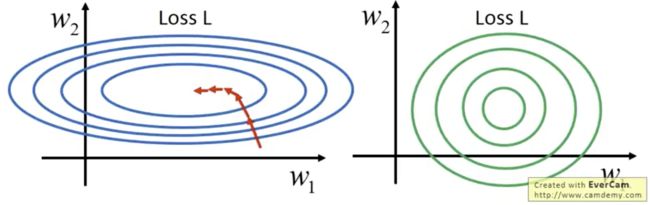
可以想象成 normalization 这个动作就是从集权走向共和的过程,不要让其中一个人的权利过于凸显,导致它做一个小的改变就足以撼动世界,中庸之道的绿色同心圆将会是个更好的训练模型。做法如下: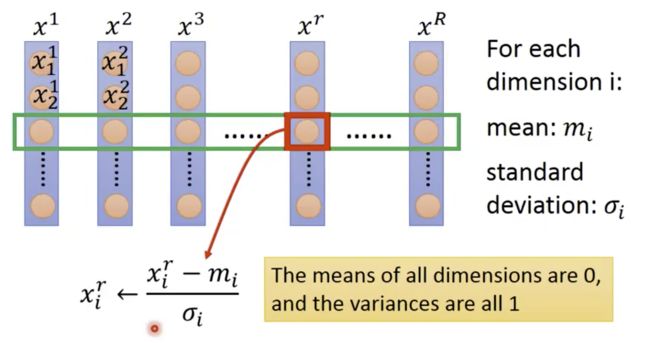
不过训练数据与测试数据的时候,毋庸置疑的都会用上 zero-centered 的方法,并且提取 mean image 到下一个层去处理。做了 zero-center 后,可以让参数对于数据不那么敏感,因为 f(x)=Wx+b,数据越接近中间,作为斜率的 W 变化的时候,相对于不在中间的情况,影响就会小很多。
Weight Initialization
训练总要有个起点,那么这个起点设置的位置就成为了一个重要的探讨话题,总不可能把 W=0 作为起点,让全部的 neuron 做一样的事情,那有做等于没做,一个无法创造差异的做法总是最坏的做法。
方法 1 :小的随机数
>>> W = 0.01 * np.random.randn(Rows, Columns)
# this formula generates the random number based on normal distribution
# the number of the rows and columns for the generated array should be set in these parameters
更多的 numpy 补充可以参考:
o https://blog.csdn.net/zenghaitao0128/article/details/78556535
但是问题来了,如果这个参数过于小,经过多层的神经网络传递后,梯度就消失了,因为所有 activation function 得出来的结果都贴近 0 ,加上常态分布下的小的随机数初始化无疑是个必须舍弃的方法。
方法 2 :大一些的随机数(-1~1 之间)
>>> W = np.random.randn(Rows, Columns) * 1.0然而,这个方法在多层神经网络传递后,所有 neuron 的数值也几乎都 saturate 了,原因是放入 activation function 里面后,大的数值都落入了方程式两极的位置,也是个不好的传递过程。
方法 3 :Xavier Initialization
为了解决上面两个方法经过多层神经网络传递产生的 saturated 问题,这个方案诞生了。
附赠两篇解释原理的论文链接:
o http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
o https://arxiv.org/pdf/1607.02488.pdf
>>> W = np.random.randn(rows, columns) / np.sqrt(rows)当输出的数小了的话,那就也除以一个小的数去挽回持续缩小的局面,但是这个方法遇到了 nonlinear function 像是 ReLU 的话也会出问题,因为 ReLU 把接近一半的数据变化抹平了,导致经过不断的传递后,还是会出现 saturation 的情况(详情见论文)。
教学投影片里尚有一页论文集推荐选读,可自行查找。
Batch Normalization
推荐论文读物(HW 之一):
o http://proceedings.mlr.press/v37/ioffe15.pdf
台湾大学 NTU 视频讲解:
o https://www.youtube.com/watch?v=BZh1ltr5Rkg
主要是为了解决 internal covariate shift 产生的问题,问题产生的原因如下描述:
我们都知道一个原始数据作为 input 在 neural network 里面传递,经过 activation function 得到的输出结果会再作为下一层 network 的 input 继续传下去,那为了更好的使 data 传递到最后还保有特征不 saturate,每次每个 neuron 传递前都会做前面介绍的 data preprocessing,让数据更好的被传递。但是问题来了!每次传递过程的同时,我们也不断依据 Loss function 的反向传播回来的结果修正原本传递下去的数据,修正前的数据 normalized 的结果是当时的最优传递状态,但是我们却无法保证是不是修改过后,这个上次传递的结果还是现在的最优(基本已经不是最优),这种情况发生在每一层,因此我们永远也无法很有效率的让层跟层之间好好的嫁接。因此新的技术:Batch Normalization 因应而生。
这个过程放在 activation function 前面后面都可以,不过比较建议放在前面,因为这样可以更加确定的让 data 不要落在会 saturate 的区域,降低初始值设定的困难度意味着整体的学习效率参数可以调得更高,也提升整体学习效率。

整体流程如上图,先求得小撮 data 的平均值(一小撮数据好掌控的同时计算资源也不会占用太多),在用求得的平均值计算标准差,接着进入 normalization 真正环节,最后给 normalize 好的结果套上一个属于 neural network 参数一部分的 gama 和 beta 值。在每次反向传播的时候,平均值与标准差是深受其影响的参数,可以有效扣住于变化中数据的关联,让不论怎么跑的数据最后面都可以正确被 normalized。
有了这个方法,多了很多好处:
- 它提升了梯度运算的有效性
- 它解放了更大的 learning rate 使用的可能性
- 它让 weight initialization 的重要性降低,降低门槛
- 它可以稍微减小 dropout 方法的需要性
- 最后一个阶段中,我们还可以控制 beta 和 gama 两个独立不受 dataset 影响的参数来更好的调整 saturation 程度,根据不同情况的需求可以非常客制化的给予响应。
因为 BN 只是重新按照一定的规则排布了神经网络的资料结构,并不会对数据本身造成任何的改动,所以是个没有情况限制的通用方法。
Babysitting the learning process
数据预处理 >>> 选择模型结构 >>> 初始化 network >>> 确保 loss 在合理范围
一般来说 learning rate 设定在 1e-3 ~ 1e-5 的范围内,太小的话会造成修正的速度很慢,就像蜗牛爬行那样,耗时耗力。其他代码的部分自行到投影片里面去理解咯~
Hyperparameter Optimization
Cross validation 是一个找出 Hyperparameter 的好方法,之前章节里面有介绍过(https://blog.csdn.net/qq_37165755/article/details/79874875),这个优化参数的过程过程需要时间去跑模型,是不可避免的过程。
When finding the hyperparameters, there are two ways to sample the values: random search and grid search. It turns out that the random one takes a better performance. For starter, the range to find out those proper hyperparameters must be wide in space. random space distribution can help us finding out which regions could perform better so that we can further narrow down the original wide range. By times of iteration, the region would be focused onto a precise location, and the hyperparameters would be found.
一般来说,在找寻 Hyperparameter 的过程中,需要无数次的人工调整过程,就像一个 DJ 调整各种音效控制一样寻找最完美的搭配输出,这个过程像是一门艺术,下面是调出来的结果比较图例: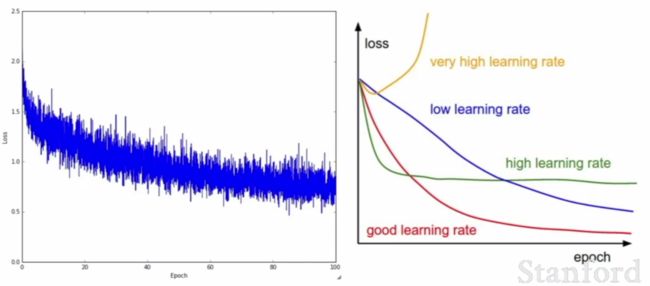
为了更好的可视化理解数据变化的过程,非常建议使用 matplotlib 里面的话图功能,实时监控当下动态。
下节链接:卷积神经网络 + 机器视觉:L7_进阶梯度下降_正则化_迁移学习 (斯坦福课堂)