python按列按id把一个txt拆分成多个文本文件
1.测试数据,python按列按id把一个txt拆分成多个文本文件

#计算元素x在列表lst中出现的次数
def countX(lst, x):
return lst.count(x)
file_path = "C:\\Users\\admin\\Desktop\\623\\"
#读取整个原始txt文件
with open("C:\\Users\\admin\\Desktop\\623\\gang.txt", "r") as f:
data = [line.rstrip('\n') for line in f]
#print(data)
#获取所有id,并把他们放到同一个列表里
list_1 = []
for e in range(0,len(data)):
list_1.append(data[e][0])
print(list_1)
#相同id连续出现数据放同一文件中,视为该id出现一次,列表2用于id出现次数
list_2 = []
list_2.append(list_1[0])
file_name = file_path + list_1[0] + '_' + str(1) + '.txt'
file = open(file_name, 'w') # 创建一个txt文件,文件名为file_name
file.write(data[0])
file.write('\r\n')
for i in range(0,len(list_1)-1):
if list_1[i] == list_1[i+1]:
#遍历列表1,id与后一个相比,相同的该行数据写进同一txt文件中
file.write(data[i+1])
file.write('\r\n')
else:
#与后一个不同,则新建文件
list_2.append(list_1[i + 1])
num = countX(list_2, list_1[i + 1])
file_name = file_path + list_1[i+1] + '_' + str(num) + '.txt'
file = open(file_name, 'w')
file.write(data[i+1])
file.write('\r\n')
结果:
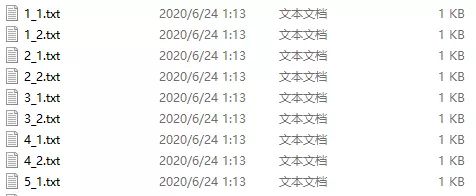

2.真实数据,按id把一个txt拆分成多个txt,并且命名规则有要求

#计算元素x在列表lst中出现的次数
def countX(lst, x):
return lst.count(x)
file_path = "F:\\gang\\gzhh\\"
#读取整个原始txt文件
with open("F:\\gang\\gzhh\\2017-0313_001.txt", "r",encoding='gb18030', errors='ignore') as f:
#with open("F:\\gang\\gzhh\\2017-0313_001.txt", "r") as f:
data = [line.rstrip('\n') for line in f]
#print(data)
#获取所有id,并把他们放到同一个列表里
list_1 = []
for e in range(0,len(data)):
list_1.append(data[e][:3])
#print(list_1)
#相同id连续出现数据放同一文件中,视为该id出现一次,列表2用于id出现次数
list_2 = []
list_2.append(list_1[0])
file_name = file_path + list_1[0] + '_' + str(1) + '.txt'
file = open(file_name, 'w') # 创建一个txt文件,文件名为file_name
file.write(data[0])
file.write('\r\n')
for i in range(0,len(list_1)-1):
if list_1[i] == list_1[i+1]:
#遍历列表1,id与后一个相比,相同的该行数据写进同一txt文件中
file.write(data[i+1])
file.write('\r\n')
else:
#与后一个不同,则新建文件
list_2.append(list_1[i + 1])
num = countX(list_2, list_1[i + 1])
file_name = file_path + list_1[i+1] + '_' + str(num) + '.txt'
file = open(file_name, 'w')
file.write(data[i+1])
file.write('\r\n')
print('end!')
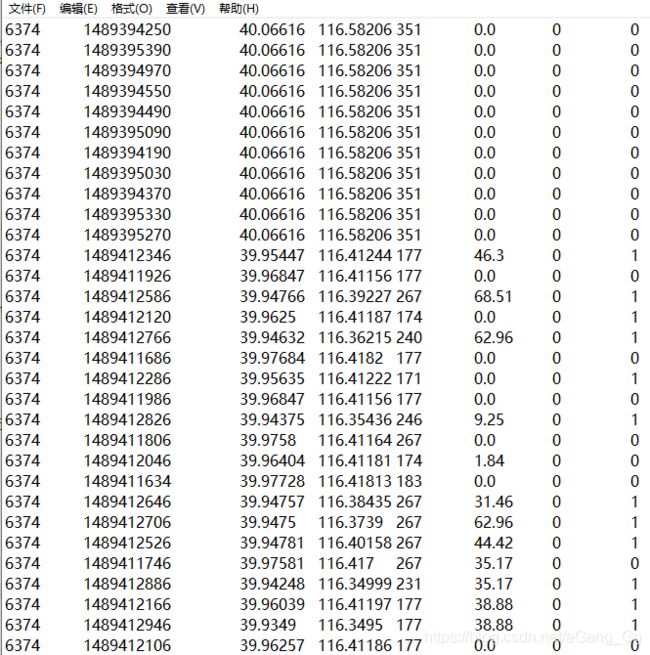
结果展示


3.遇到问题:
1.utf-8和gbk编码解码的问题。
2.id截取切片灵活运用。
