海量日志存储和查询方法及系统
技术领域
[0001] 本发明涉及通讯日志处理技术领域,更为具体地,涉及一种海量日志存储和查询 方法及系统。
背景技术
[0002] 随着云计算、移动互联网、物联网的崛起与发展,大数据的时代已经来临。各种系 统、程序、运维、交易等的日志作为系统恢复、错误跟踪、安全检测等操作的重要依据,变得 越来越重要。因此,在海量日志中快速的寻找到有用的信息,也变得十分重要。
[0003] 例如,入侵监测、漏洞扫描、审计等系统作为安全监测系统,能够完成对安全构成 威胁的任何一个行为进行报警,即生成操作日志。当某一个操作持续进行时,就会发出相同 的操作日志,假设一个黑客使用暴力破解软件进行一个主机的密码操作时,这台主机就会 不停的报出密码错误的操作日志。如果管理员每天的看这些日志,就难免会将一些有用的 信息掩没在这海量的日志中,从而无法从海量日志中定位目标日志。
[0004] 针对上述问题,目前的日志审计系统或相关产品,可以实现日志采集、审计分析、 集中存储和信息展示等功能。这类产品的一个主要的特点是对相同的日志进行聚合,相同 的日志指的是同一种类的日志,比如上面提到的密码错误就属于同一种类的日志,密码成 功就是另外一种日志。对日志进行聚合的目的是方便展示,其存储方式还是按照日志事件 的主从关系存储到表或数据结构中。主关系存储事件的特征信息和聚合的数量,比如,密码 错误50次。从关系存储具体信息,比如,发生密码错误的具体时间、来源的IP地址等等。
[0005] 管理员除了关注聚合数量外,还需要关注日志在不同时间段的发生频率和某一时 间段具体日志的内容,这样就引入了海量日志聚合后的查询问题。对应以上的问题,一般的 实现是查询从关系并关联主关系的方式,具体实现如下:
[0006] -般情况下,将主从关系对应到数据库中的主从表中,并将从表按照时间进行分 区。查询条件为时间或者是时间和设备类型相结合,返回结果为时间轴(TimeLine)和列表 相结合的方式。这种方式查询性能低,即使是使用分区存储效果也不好,随着日志数量的增 多,性能下降的更加明显,此外,需轮询消息列队,效率较低。
[0007] 综上所述,使用传统的主从表做联合查询、分组和排序存在以下缺点:
[0008] 1、查询性能非常的低,即使是使用分区存储效果也不好。并且随着日志数量的增 多,性能下降的非常明显。当到达一定数量时,界面几乎无响应。
[0009] 2、查询到之后,必须等排序完成后才能返回结果。
发明内容
[0010] 鉴于上述问题,本发明的目的是提供一种海量日志存储和查询方法及系统,以解 决现有对日志处理中以主从表做查询、分组和排序存在的查询效率低等问题。
[0011] 根据本发明的一个方面,提供了一种海量日志存储和查询方法,包括将聚合后的 日志按时间进行分片,其中,分片的时间根据日志的聚合时间确定;将分片后的日志按照主 从关系存储为文件结构,其中,分片后的日志按照主从关系存储在主文件和从文件内,主文 件包括日志的聚合数量、分片开始时间和分片结束时间,且主文件采用XML数据结构,包括 event元素、count元素、Level元素和Keyword元素,从文件包括日志的发生时间和发生日 志的设备的IP ;在主文件和从文件内对日志进行查询。
[0012] 其中,在对日志进行查询的过程中,查询条件为时间或者为时间与日志的等级、名 称、关键字或设备类型中至少一个的结合。
[0013] 其中,在对日志进行查询的过程中,包括两种情况:第一种情况,对现在至过去一 个时间段的日志进行查询,当分片的开始时间晚于查询的开始时间时,将该时间段内的所 有分片中的相同日志做合并,作为第一批数据进行显示;当分片的开始时间早于查询的开 始时间、并且分片的结束时间晚于查询的开始时间时,对从文件中的日志进行计算,并作为 第二批数据进行显示;第二种情况,对过去某一个时间段内的日志进行查询,当分片的开始 时间晚于查询的开始时间、并且分片的结束时间早于查询的结束时间时,将该时间段内的 所有分片中相同的事件做合并,作为第一批数据进行显示;当分片的开始时间早于查询的 开始时间、并且分片的结束时间晚于查询的开始时间,或者分片的结束时间晚于查询的结 束时间、并且查询的结束时间晚于分片的开始时间时,将从文件中的日志进行计算,并作为 第二批数据进行显示。
[0014] 根据本发明的另一方面,提供了一种海量日志存储和查询系统,包括分片模块,用 于将聚合后的日志按时间进行分片,其中,分片的时间根据日志的聚合时间确定;存储模 块,用于将分片后的日志按照主从关系存储为文件结构,其中,分片后的日志按照主从关系 存储在主文件和从文件内,主文件包括日志的聚合数量、分片开始时间和分片结束时间,且 主文件采用XML数据结构,包括event元素、count元素、Level元素和Keyword元素,从文 件包括日志的发生时间和发生日志的设备的IP。
[0015] 其中,在查询模块中,查询条件为时间或者为时间与日志的等级、名称、关键字或 设备类型中至少一个的结合。
[0016] 其中,对日志进行查询的过程包括两种情况:第一种情况,对现在至过去一个时间 段的日志进行查询,当分片的开始时间晚于查询的开始时间时,将该时间段内的所有分片 中的相同日志做合并,作为第一批数据进行显示;当分片的开始时间早于查询的开始时间、 并且分片的结束时间晚于查询的开始时间时,对从文件中的日志进行计算,并作为第二批 数据进行显示;第二种情况,对过去某一个时间段内的日志进行查询,当分片的开始时间晚 于查询的开始时间、并且分片的结束时间早于查询的结束时间时,将该时间段内的所有分 片中相同的事件做合并,作为第一批数据进行显示;当分片的开始时间早于查询的开始时 间、并且分片的结束时间晚于查询的开始时间,或者分片的结束时间晚于查询的结束时间、 并且查询的结束时间晚于分片的开始时间时,将从文件中的日志进行计算,并作为第二批 数据进行显示。
[0017] 利用上述根据本发明的海量日志存储和查询方法及系统,具有以下优点:
[0018] (1)在海量日志中,快速查询到满足时间范围和一定条件的所有日志;
[0019] ⑵特有的主从文件式结构,可以快速的统计聚合日志的数量并快速的查询详细 事件;
[0020] (3)可以快速的形成以时间为横坐标、以数量为纵坐标的时间轴;
[0021] (4)特有的主从文件式结构,存储体积小、易于压缩,方便保存更长时间的日志;
[0022] (5)对查询事件分批返回,界面响应及时,用户体验好。
[0023] 为了实现上述以及相关目的,本发明的一个或多个方面包括后面将详细说明并在 权利要求中特别指出的特征。下面的说明以及附图详细说明了本发明的某些示例性方面。 然而,这些方面指示的仅仅是可使用本发明的原理的各种方式中的一些方式。此外,本发明 旨在包括所有这些方面以及它们的等同物。
附图说明
[0024] 通过参考以下结合附图的说明及权利要求书的内容,并且随着对本发明的更全面 理解,本发明的其它目的及结果将更加明白及易于理解。在附图中:
[0025] 图1为根据本发明实施例的海量日志存储和查询方法的流程图;
[0026] 图2为根据本发明实施例的海量日志存储和查询方法的主从文件结构示意图;
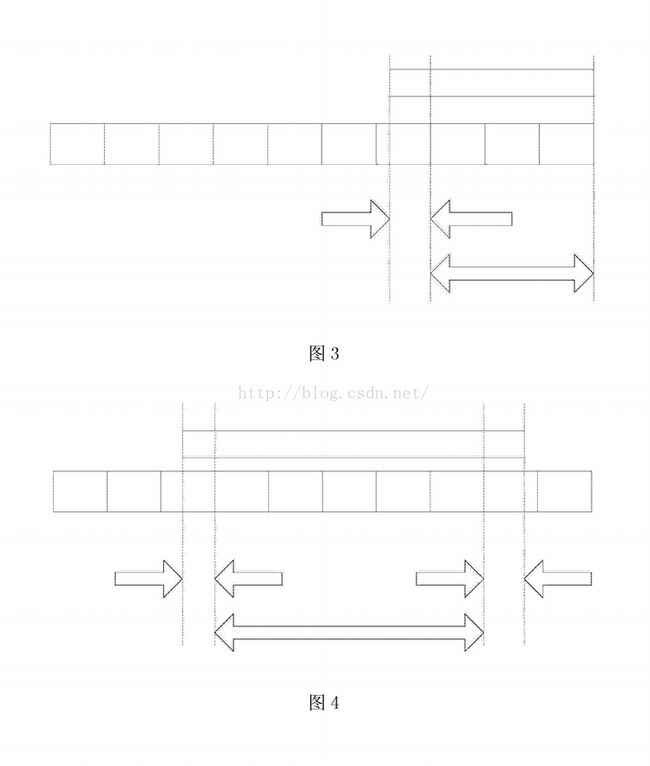
[0027] 图3为根据本发明实施例的海量日志存储和查询方法的第一种查询情况分片结 构示意图;
[0028] 图4为根据本发明实施例的海量日志存储和查询方法的第二种查询情况分片结 构示意图;
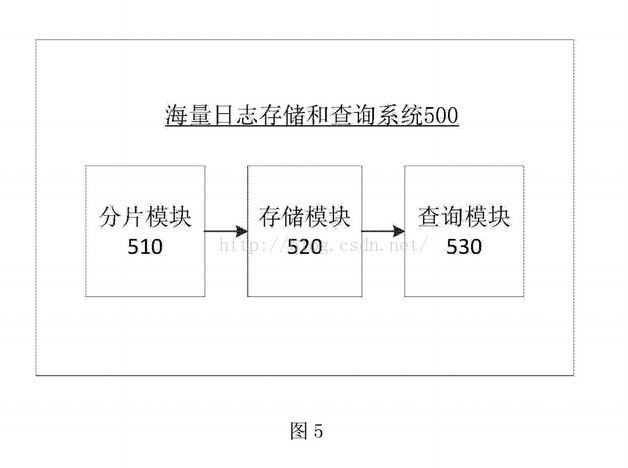
[0029] 图5为根据本发明实施例的海量日志存储和查询系统方框示意图。
[0030] 在所有附图中相同的标号指示相似或相应的特征或功能。

具体实施方式
[0031] 在下面的描述中,出于说明的目的,为了提供对一个或多个实施例的全面理解,阐 述了许多具体细节。然而,很明显,也可以在没有这些具体细节的情况下实现这些实施例。
[0032] 根据目前使用的主从表做联合查询、分组和排序,存在查询性能非常低的问题,即 使是使用分区存储,查询效果也不好,并且查询到之后,必须等排序完成后才能返回结果。 针对上述现有技术中存在的问题,本发明通过将聚合后的日志进行分片,对分片后的数据 分段存储,并根据查询条件将分段后的数据快速拼装,提高日志查询效率,并能快速返回查 询结果。
[0033] 以下将结合附图对本发明的具体实施例进行详细描述。
[0034] 图1示出了根据本发明实施例的海量日志存储和查询方法流程。
[0035] 如图1所示,根据本发明的海量日志存储和查询方法流程包括:
[0036] S110 :将聚合后的日志按时间进行分片,其中,分片的时间根据日志的聚合时间确 定。
[0037] 具体地,将聚合后的日志事件做分片的预先处理,将长时间的日志聚合改为中、短 时间的分片。例如,将永久聚合的同一日志事件,改为按照一天或者一小时的聚合。在本发 明中对聚合后的所有日志按照整点、整分的时间进行分片,分片的时间根据日志聚合时间 的大小进行确定,也就是说日志聚合时间大小不同,分片时间的大小也不同,同时,对分片 后的日志以特殊结构进行存储,以方便用户对日志进行查询和保存。
[0038] S120 :将分片后的日志按照主从关系存储为文件结构,其中,分片后的日志按照主 从关系存储在主文件和从文件内,主文件包括日志的聚合数量、分片开始时间和分片结束 时间,且主文件采用XML数据结构,包括event元素、count元素、Level元素和Keyword元 素,从文件包括日志的发生时间和发生日志的设备的IP。
[0039] 具体地,将聚合日志进行分片后,按照主从文件的结构进行存储。其中,当分片后 的日志按照主从关系存储在主文件和从文件内时,主文件主要包括日志的聚合数量、分片 开始时间和分片结束时间,从文件主要包括日志的发生时间和发生日志的设备的IP。此外, 文件名为对聚合日志进行分片的开始时间,分片的结束时间可以由分片的开始时间和分片 大小计算得出。
[0040] 其中,对于上述描述也可以理解为,在本发明的海量日志存储和查询方法中,设置 两个存储单元,一个主存储单元和一个从存储单元,可知存储单元为文件结构。其中,主存 储单元的主要字段有日志事件的聚合数量、分片的开始时间和结束时间;从存储单元存储 详细的每一个日志事件。主存储单元对应数据库中的主文件,从存储单元对应数据库中的 从文件。
[0041] 作为示例,图2示出了根据本发明实施例的海量日志存储和查询方法的主从文件 结构。
[0042] 如图2所示,主文件存储日志的聚合时间,从文件存储日志的详细事件。此外,文 件名为分片的开始时间,分片的结束时间可以由开始时间和分片大小计算得出。在该实施 例中,主文件名为20140801000000,表示存储2014年8月1日零点以后的分片数据,由于 分片时间设定为一天,所以该分片的结束时间为20140801232359,即该分片的结束时间为 2014年8月1日23点23分59秒。从文件名为20140801000000_d,该从文件与下划线之 前同名的主文件相对应。
[0043] 需要说明的是,在本发明的海量日志存储和查询方法中,按照主从文件的结构对 分片后的日志进行存储时,主文件采用XML的数据结构,表示对相应的从文件中日志时间 的结构描述,主要包括event元素、count元素、Level元素和Keyword元素。具体地,上述 示例的主文件中存储的内容如下所述:
[0044] 〈context〉
[0045]
[0046] 其中,主文件中的Event元素为必须项,表示该时间段内日志事件的信息,属性 count表示该种日志事件的数量,上述内容中用逗号分隔的数字表示从文件中对应的行号。 在数据存储时,先追加从文件的内容,由于是增量操作,只能在原有的文件后面进行追加, 所以行号是不会改变的。然后,修改Event元素,Event元素需要先读入到内存中,修改后 再写回到主文件中。由于写入主文件和从文件的时候都是定时或者批量完成的,不会出现 频繁的磁盘输入/输出情况。
[0047] 此外,主文件的其它元素,如Level、Keyword等,用做扩展使用。在以时间为查询 条件的前提下,用做数据查询,通过对查询条件做预先的处理,可以大大提高日志的查询速 度。内容中用逗号分隔的数字表示从文件中对应的行号,查询的时候只需要找到相应的元 素,将元素中的行号做交集计算,即可以得到查询后的日志事件数量和相对应的日志事件。
[0048] 对应上述主文件内容,从文件中存储的内容如下所述:
[0049] 行号1 时间 Message 1 行号2 时间 Message】 行号3 时间 Message3 行号4 时间 Message4 行号5 时间 Message5 行号N 时间 MessageN
[0050] 其中,通过设定的查询条件,在主文件的各元素中进行筛选,并对各元素内的行号 取交集运算,最终得到一个行号值,并对该值在从文件内进行对应,进而得到具体的查询日 ;志肩、。
[0051] S130 :在主文件和从文件内对日志进行查询。
[0052] 其中,在对日志进行查询的过程中,查询条件为时间或者为时间与日志的等级、名 称、关键字或设备类型中至少一个的结合,也就是说在对日志事件进行查询的时候,时间为 必须条件,事件的等级、名称、关键字、设备类型等为可选条件。根据查询条件对主存储单元 内容进行筛选,以确定最终的查询结果并进行显示,存储单元为主从文件结构,需要到对应 的主存储单元中进行行号的交集计算。
[0053] 具体地,在查询过程中会出现两种情况,以下将结合附图对这两种情况分别进行 说明。
[0054] 图3示出了根据本发明实施例的海量日志存储和查询方法的第一种查询情况分 片结构。
[0055] 如图3所示,在第一种情况中,对现在至过去一个时间段的日志进行查询,当分片 的开始时间晚于查询的开始时间时,将该时间段内的所有分片中的相同日志做合并,作为 第一批数据进行显示;当分片的开始时间早于查询的开始时间、并且分片的结束时间晚于 查询的开始时间时,对从文件中的日志进行计算,并作为第二批数据进行显示。
[0056] 具体地,对最近一段时间内的日志进行查询(例如,最近1小时或最近1天),此 时,双向箭头部分(分片的开始时间晚于查询的开始时间)为确定数量,需要进行分组计算 后(将多个分片中相同的事件做合并),作为第一批在界面显示的数据。单向箭头部分(分 片的开始时间早于查询的开始时间、并且分片的结束时间晚于查询的开始时间)为不确定 的数量,需要到从存储单元即从文件中进行计算后(对从存储单元做逐一过滤,由于是已 经确定到很小的分片中,并且事件是按照时间上的先后顺序插入的,即使是有其它条件查 询也比较快。),作为第二批在界面显示的数据。如果选择的开始时间都是整点,并且数据 存储也是按照整点进行存储的,那么所有的数据都在双向箭头中,不需要操作从存储单元 即可完成。
[0057] 图4示出了根据本发明实施例的海量日志存储和查询方法中的第二种查询情况 分片结构。
[0058] 如图4所示,在第二种查询情况中,对过去某一个时间段内的日志进行查询,当分 片的开始时间晚于查询的开始时间、并且分片的结束时间早于查询的结束时间时,将该时 间段内的所有分片中相同的事件做合并,作为第一批数据进行显示;当分片的开始时间早 于查询的开始时间、并且分片的结束时间晚于查询的开始时间,或者分片的结束时间晚于 查询的结束时间、并且查询的结束时间晚于分片的开始时间时,将从文件中的日志进行计 算,并作为第二批数据进行显示。
[0059] 具体地,对过去某一个时间段内的日志进行查询,其中,双向箭头部分(分片的开 始时间晚于查询的开始时间、并且分片的结束时间早于查询的结束时间)为确定数量,需 要进行分组计算后(将多个分片中相同的事件做合并),作为第一批在界面显示的数据。单 向箭头部分(分片的开始时间早于查询的开始时间,并且分片的结束时间晚于查询的开始 时间。分片的结束时间晚于查询的结束时间、并且查询的结束时间晚于分片的开始时间) 为不确定的数量,需要到从存储单元即从文件中进行计算后(做逐一过滤,由于是已经确 定到很小的分片中,并且事件是按照时间上的先后顺序插入的,即使是有其它条件查询也 比较快。),作为第二批在界面显示的数据。如果选择的开始时间和结束时间都是整点,并 且数据存储也是按照整点进行存储的,那么所有的数据都在双向箭头中,不需要操作从存 储单元即可完成。
[0060] 根据上述本发明提供的海量日志存储和查询方法,本发明还提供一种海量日志存 储和查询系统。图5示出了根据本发明实施例的海量日志存储和查询系统。
[0061] 如图5所示,本发明提供的海量日志存储和查询系统500包括分片模块510、存储 模块520和查询模块530,其中,
[0062] 分片模块510,用于将聚合后的日志按时间进行分片其中,分片的时间根据日志的 聚合时间确定。
[0063] 具体地,将聚合后的日志事件做分片的预先处理,将长时间的日志聚合改为中、短 时间的分片,对聚合后的所有日志按照整点、整分的时间进行分片,分片的大小根据日志聚 合时间的大小进行确定,也就是说日志聚合时间大小不同,时间分片的大小也不同。
[0064] 存储模块520,用于将分片后的日志按照主从关系存储为文件结构,其中,分片后 的日志按照主从关系存储在主文件和从文件内,主文件包括日志的聚合数量、分片开始时 间和分片结束时间,且主文件采用XML数据结构,包括event元素、count元素、Level元素 和Keyword元素,从文件包括日志的发生时间和发生日志的设备的IP。
[0065] 具体地,将聚合日志进行分片后,按照主从文件的结构进行存储。其中,在以文件 结构进行存储的过程中,主文件包括日志的聚合数量、分片开始时间和分片结束时间,从文 件存储详细日志事件。此外,文件名为对聚合日志进行分片的开始时间,分片的结束时间可 以由开始时间和分片大小计算得出。
[0066] 查询模块530,用于在主文件和从文件内对日志进行查询。
[0067] 具体地,在对日志进行查询的过程中,查询条件为时间或者为时间与日志的等级、 名称、关键字或设备类型中至少一个的结合,也就是说在对日志事件进行查询的时候,时间 为必须条件,事件的等级、名称、关键字、设备类型等为可选条件。根据查询条件对主文件和 从文件的内容进行筛选,以确定最终的查询结果并进行显示,分片后的日志存储为文件结 构,需要到对应的存储内容中进行行号的交集计算。
[0068] 利用上述本发明提供的海量日志存储和查询方法及系统,能够在短时间内,在海 量日志中查询满足时间范围和一定条件的所有日志,并能以图像化的方式展现给用户。此 夕卜,采用特有的文件式结构,也可以快速的统计日志聚合数量和快速的查询详细日志事件, 存储体积小,方便压缩和保存。
[0069] 如上参照附图以示例的方式描述根据本发明的海量日志存储和查询方法及系统。 但是,本领域技术人员应当理解,对于上述本发明所提出的海量日志存储和查询方法及系 统,还可以在不脱离本发明内容的基础上做出各种改进。因此,本发明的保护范围应当由所 附的权利要求书的内容确定。