深入理解梯度下降
背景:梯度下降于机器学习尤紧要,然已理解如蜻蜓点水,近决心重拾,乃于其刨根究底。
目录:
- 梯度下降作用
- 梯度下降公式推导
- 梯度下降代码实现 Python
梯度下降的作用:
机器学习能够动态求解出一个函数,用这个函数能够预测出新的结果。我们方程的复杂度大致分成简单方程,中等方程,复杂方程。
简单方程:中学知识可以解决了,回想我们中学解一个方程,往往通过消元来解决。
中等难度方程:10-100个未知数,线性代数可以解决。学线性代数时不知其用处。
复杂方程:成千上万个未知数,那么梯度下降,计算机来解决。
至此,梯度下降与工程应用,乃利器。
梯度下降的推导:
用常识来解决这个问题,那就是沿着最陡峭的地方下降的最快,假设一个极限,山坡是直立的,那你走一小步,就坠落悬崖了,然后你根本不用迈出第二步。用更加学术的概念说就是梯度下降法。
蓝后,梯度下降法又是什么东西呢?且听老衲娓娓道来(猥琐脸)。
简言之,一个公式解决施主的所有疑惑
说明一下:上面的公式是一个位置更新公式,说白了,就是你每走一步,就记录一下你现在的位置,也就是等号左边的 ,那这一步之前你在的位置就是等号右边的 ,那你一步走多远呢?答案是 ,那你是要朝哪个方向走呢?估计已经猜到了,就是 。
现在还有一点小疑惑。 是什么鬼?现在你可以把它假想为你在的位置的高度。
现在大概清楚了吧,既有前进的方向,又有前进的距离,很容易联想到学过的向量。这些向量首尾相连,这个轨迹就是这个方程的曲线图。画在图上大概是这个样子:
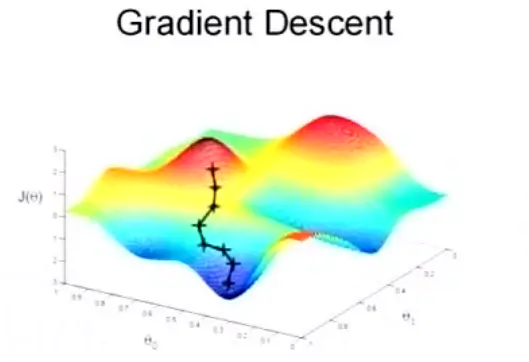
梯度下降法图解说明
且慢,施主不要走,你只学会了老衲的一成功力,还不足以出师
(呵呵呵)其实,这个公式虽然你能理解了,但是计算机无论如何也想不通,这样,就算电脑思考到死机也不会产生答案。。。。
现在我要把九阳真经传授于你:让计算机也能够像你一样去思考这个问题的答案。下面我们把这个公式给通俗化,把它展开成一个可以用计算机语言描述的柿子。
是否还记得上面的假想 ,现在告诉你,这个假想是错误的,因为它的真实含义不是高度,而是一个关于 方差的表达式。
它是这样定义的:
我来描述一下这个柿子:
首先给定一个 的矩阵
释义:
:表示需要求解的待定系数
:表示第 行所有的
:表示第 行所有的 乘以 后的取值,即 ,表示根据假设的模型计算的
:表示第 行对应的真实的 值
:表示令方差最小的函数(关于 )
=================================
答疑区
- 如何理解这个函数
可以简单的这样理解,我们要假设的模型最终要和现实世界的模型最好的吻合,这也是我们的初衷,如何来衡量吻合的效果呢?我们用方差来表示吻合的效果,这个其实也叫做损失函数,当我们把损失降低到最小的时候,吻合的效果是最好的。这个和我们一开始提出的下山路径规划是一个思路,所以就可以用同一种方法来求解了。其实这个方法就是用来求解最小值问题的。
- 那么为什么要走最快的路径呢?走其他路径不是也可以到达最低点吗?
答案是可以,通过其他的路径也可以到达最低点,在生活中确实也是这样的,但是根据我们从高中就建立起来的数学观念,貌似我们只学过两种求极值的方法,其一是根据曲线的特性,其二是求导。很明显,这个问题没有给定的曲线,所以我们只能用第二种方式来求解最值了。
当然如果你发现了一个新的求解极值的方式,也许你就是那个可以改变世界的人。期待你的进一步研究。
- 越接近最优解的时候发现图中的步长越小?
首先,你的发现是正确的。事实是这样的,这个向量等于 的乘积,虽然我们选择的 始终是一个定值,但是越接近最值的时候,这个坡度就会越缓,从而导数的值就越小,也就是乘积变小了,这就是看到步长变小的缘故。
=================================
推导过程
现在大致了解了计算机的工作流程。在下面就是公式的推导了。

推导过程
数据量很大如何解决呢?
对于数量级很小的数据集我们可以用上面的方法来进行求解,但是通常情况给出的数据集并不小,我们考虑到计算机的性能,需要换一种解决方案。但是庆幸的是,用到的原理并没有发生变化。
对于数据集较大的,我们可以从原始数据集中每次训练时随机的选择一部分来进行对真实情况的模拟,虽然会产生一定的误差,但是这是在准确度和效率之间权衡之后选择的一个方式。俗话说,鱼与熊掌不可兼得。
下面介绍的解决方法是:随机梯度下降法,用伪代码来解释一下:
Repeat{
for j=1 to m{
theta_i = theta_i - alpha * J’(theta) # 这个就是上面写的更新公式
}
}
这里随机选择的数据集的大小是 行。也就是 batch size。
在推导过程中需要用到的概念和公式:
- 迹
在线性代数中,一个n×n矩阵A的主对角线(从左上方至右下方的对角线)上各个元素的总和被称为矩阵A的迹(或迹数),一般记作tr(A)。
- 公式
- #A、B、C均为n*n的矩阵
- 若 ,则


待定系数现在已经不是一个未知数了,根据我们的数据,可以直接对其进行求解了。在使用的时候千万不要说你还不懂原理,老衲已经把毕生的功力传输于你。
3.梯度下降实现代码
import numpy as np
import pandas as pd
from numpy import *
from pandas import *
import matplotlib.pyplot as plt
a = np.array([[1, 2], [2, 1], [3, 2.5], [4, 3],
[5, 4], [6, 5], [7, 2.7], [8, 4.5],
[9, 2]])
m = a.shape[0]
print(m)
print(type(a))
x = a[:, 0]
y = a[:, 1]
plt.scatter(x, y, marker='*', color='r', s=20)
inittheta0 = 0
inittheta1 = 0
iterations = 1500
alpha = 0.01
# 小批量梯度下降
def gradientdescentminibatch(x, y, theta0, theta1, iterations, alpha):
j_h = np.zeros((iterations, 1))
for i in range(0, iterations):
y_hat = theta0 + theta1 * x
temp0 = theta0 - alpha * ((1 / m) * sum(y_hat - y))
temp1 = theta1 - alpha * (1 / m) * sum((y_hat - y) * x)
theta0 = temp0
theta1 = temp1
y_hat2 = theta0 + theta1 * x
aa = sum((y_hat2 - y) ** 2)
j = aa*(1 / (2 * m))
j_h[i, :] = j
return theta0, theta1, j_h
(theta0,theta1,J_h) = gradientdescentminibatch(x,y,inittheta0,inittheta1,iterations,alpha)
print(theta1)
print(theta0)
plt.plot(x,theta0+theta1*x)
plt.title("fittingcurve")
plt.show()
x2=np.arange(iterations)
plt.plot(x2,J_h)
plt.title("costfunction")
plt.show()