原文链接:http://tecdat.cn/?p=5147
介绍
深度学习是机器学习最近的一个趋势,模拟高度非线性的数据表示。在过去的几年中,深度学习在各种应用中获得了巨大的发展势头(Wikipedia 2016a)。其中包括图像和语音识别,无人驾驶汽车,自然语言处理等等。
今天,深度学习对于几乎所有需要机器学习的任务都是非常有效的。但是,它特别适合复杂的分层数据。其潜在的人工神经网络模型高度非线性表示; 这些通常由多层结合非线性转换和定制架构组成。图1描述了一个深度神经网络的典型表示。
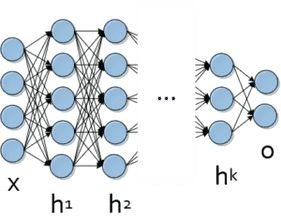
图1.深度神经网络的模型
深度学习的成功带来了各种编程语言的各种框架和库。例子包括Caffee,Theano,Torch和Tensor Flow等等。这篇博客文章的目的是为编程语言R提供不同深度学习软件包的概述和比较。我们比较不同数据集的性能和易用性。
R学习
R编程语言在统计人员和数据挖掘人员之间的易用性以及复杂的可视化和分析方面已经获得了相当的普及。随着深度学习时代的到来,对R的深度学习的支持不断增长,随着越来越多的软件包的推出,本节提供以下软件包提供的有关深度学习的概述:MXNetR,darch,deepnet,H2O和deepr。
首先,我们注意到,从一个包到另一个包的底层学习算法有很大的不同。同样,表1显示了每个软件包中可用方法/体系结构的列表。
表1. R包中可用的深度学习方法列表。
包神经网络的可用体系结构
MXNetR前馈神经网络,卷积神经网络(CNN)
达奇限制玻尔兹曼机,深层信念网络
DEEPNET前馈神经网络,受限玻尔兹曼机器,深层信念网络,堆栈自动编码器
H2O前馈神经网络,深度自动编码器
deepr从H2O和深网包中简化一些功能
包“MXNetR”
MXNetR包是用C ++编写的MXNet库的接口。它包含前馈神经网络和卷积神经网络(CNN)(MXNetR 2016a)。它也允许人们构建定制的模型。该软件包分为两个版本:仅限CPU或GPU版本。以前的CPU版本可以直接从R内部直接安装,而后者的GPU版本依赖于第三方库(如cuDNN),并需要从其源代码(MXNetR 2016b)中构建库。
前馈神经网络(多层感知器)可以在MXNetR中构建,其函数调用如下:
mx.mlp(data, label, hidden_node=1, dropout=NULL, activation=”tanh”, out_activation=”softmax”, device=mx.ctx.default(),…)参数如下:
data - 输入矩阵
label - 培训标签
hidden_node - 包含每个隐藏层中隐藏节点数量的向量
dropout - [0,1)中包含从最后一个隐藏层到输出层的丢失率的数字
activation - 包含激活函数名称的单个字符串或向量。有效值是{ 'relu','sigmoid','softrelu','tanh'}
out_activation - 包含输出激活函数名称的单个字符串。有效值是{ 'rmse','sofrmax','logistic'}
device- 是否训练mx.cpu(默认)或mx.gpu
... - 传递给其他参数 mx.model.FeedForward.create
函数mx.model.FeedForward.create在内部使用,mx.mpl并采用以下参数:
symbol - 神经网络的符号配置
ctx - 上下文,即设备(CPU / GPU)或设备列表(多个CPU或GPU)
num.round - 训练模型的迭代次数
optimizer- 字符串(默认是'sgd')
initializer - 参数的初始化方案
eval.data - 过程中使用的验证集
eval.metric - 评估结果的功能
epoch.end.callback - 迭代结束时回调
batch.end.callback - 当一个小批量迭代结束时回调
array.batch.size - 用于阵列训练的批量大小
array.layout-可以是{ 'auto','colmajor','rowmajor'}
kvstore - 多个设备的同步方案
示例调用:
model <- mx.mlp(train.x, train.y, hidden_node=c(128,64), out_node=2, activation="relu", out_activation="softmax",num.round=100, array.batch.size=15, learning.rate=0.07, momentum=0.9, device=mx.cpu())之后要使用训练好的模型,我们只需要调用predict()指定model第一个参数和testset第二个参数的函数:
preds = predict(model, testset)这个函数mx.mlp()本质上代表了使用MXNet的'Symbol'系统定义一个神经网络的更灵活但更长的过程。以前的网络符号定义的等价物将是:
data <- mx.symbol.Variable("data") fc1 <- mx.symbol.FullyConnected(data, num_hidden=128) act1 <- mx.symbol.Activation(fc1, name="relu1", act_type="relu")当网络架构最终被创建时,MXNetR提供了一种简单的方法来使用以下函数调用来图形化地检查它:
graph.viz(model$symbol$as.json())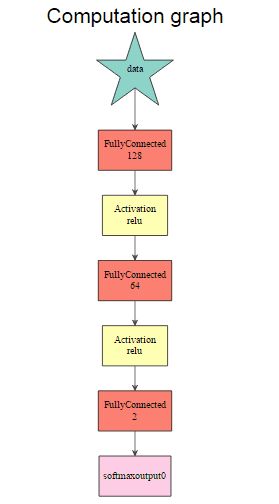
graph.viz(model2$symbol$as.json())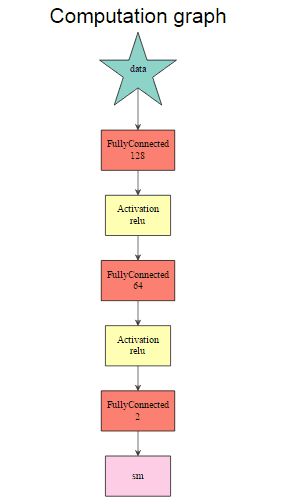
这里,参数是由符号表示的训练模型。第一个网络由mx.mlp()第二个网络构建,第二个网络使用符号系统。
该定义从输入到输出逐层进行,同时还为每个层分别允许不同数量的神经元和特定的激活函数。其他选项可通过mx.symbol以下方式获得:mx.symbol.Convolution,将卷积应用于输入,然后添加偏差。它可以创建卷积神经网络。相反mx.symbol.Deconvolution,通常在分割网络中使用mx.symbol.UpSampling,以便重建图像的按像素分类。CNN中使用的另一种类型的层是mx.symbol.Pooling; 这实质上通过选择具有最高响应的信号来减少数据。该层mx.symbol.Flatten需要将卷积层和池层链接到完全连接的网络。另外,mx.symbol.Dropout可以用来应付过度配合的问题。它将输入的参数previous_layer和浮点值fraction作为下降的参数。
正如我们所看到的,MXNetR可用于快速设计标准多层感知器的功能,mx.mlp()或用于更广泛的关于符号表示的实验。
LeNet网络示例:
data <- mx.symbol.Variable('data')总而言之,MXNetR软件包非常灵活,同时支持多个CPU和多个GPU。它具有构建标准前馈网络的捷径,同时也提供了灵活的功能来构建更复杂的定制网络,如CNN LeNet。
“darch”
darch软件包(darch 2015)实施深层架构的训练,如深层信念网络,它由分层预训练的限制玻尔兹曼机器组成。该套件还需要反向传播进行微调,并且在最新版本中,可以选择预培训。
深层信仰网络的培训是通过darch()功能进行的。
示例调用:
darch <- darch(train.x, train.y, rbm.numEpochs = 0, rbm.batchSize = 100, rbm.trainOutputLayer = F, layers = c(784,100,10), darch.batchSize = 100, darch.learnRate = 2, darch.retainData = F, darch.numEpochs = 20 )这个函数带有几个最重要的参数,如下所示:
x - 输入数据
y - 目标数据
layers - 包含一个整数的矢量,用于每个图层中的神经元数量(包括输入和输出图层)
rbm.batchSize - 预培训批量大小
rbm.trainOutputLayer - 在训练前使用的布尔值。如果属实,RBM的输出层也会被训练
rbm.numCD - 执行对比分歧的完整步数
rbm.numEpochs - 预培训的时期数量
darch.batchSize - 微调批量大小
darch.fineTuneFunction - 微调功能
darch.dropoutInput - 网络输入丢失率
darch.dropoutHidden - 隐藏层上的丢失率
darch.stopErr - 如果错误小于或等于阈值,则停止训练
darch.numEpochs - 微调的时代数量
darch.retainData - 布尔型,指示在培训之后将训练数据存储在darch实例中的天气
根据以前的参数,我们可以训练我们的模型产生一个对象darch。稍后我们可以将其应用于测试数据集test.x来进行预测。在这种情况下,一个附加参数type指定预测的输出类型。例如,可以‘raw’给出‘bin’二进制向量和‘class’类标签的概率。最后,在调用时predict()进行如下预测:
predictions <- predict(darch, test.x, type="bin")总的来说,darch的基本用法很简单。它只需要一个功能来训练网络。但另一方面,这套教材只限于深层的信仰网络,这通常需要更广泛的训练。
包“deepnet ”
deepnet (deepnet 2015)是一个相对较小,但相当强大的软件包,有多种架构可供选择。它可以使用函数来训练一个前馈网络,也可以用nn.train()深度信念网络来初始化权重dbn.dnn.train()。这个功能在内部rbm.train()用来训练一个受限制的波尔兹曼机器(也可以单独使用)。此外,深网也可以处理堆叠的自动编码器sae.dnn.train()。
示例调用(for nn.train()):
nn.train(x, y, initW=NULL, initB=NULL, hidden=c(50,20), activationfun="sigm", learningrate=0.8, momentum=0.5, learningrate_scale=1, output="sigm", numepochs=3, batchsize=100, hidden_dropout=0, visible_dropout=0)人们可以设置原来的权initW重initB,否则随机生成。另外,hidden控制的在隐藏层单元的数量,而activationfun指定的隐藏层的激活功能(可以是‘sigm’,‘linear’或‘tanh’),以及输出层的(可以是‘sigm’,‘linear’,‘softmax’)。
作为一种选择,下面的例子训练一个神经网络,其中权重是由深层信念网络(via dbn.dnn.train())初始化的。差别主要在于训练受限玻尔兹曼机的对比散度算法。它是通过cd给定学习算法内的吉布斯采样的迭代次数来设置的。
dbn.dnn.train(x, y, hidden=c(1), activationfun="sigm", learningrate=0.8, momentum=0.5, learningrate_scale=1, output="sigm", numepochs=3, batchsize=100, hidden_dropout=0, visible_dropout=0, cd=1)同样,也可以从堆栈自动编码器初始化权重。output这个例子不是使用参数,而是sae_output和以前一样使用。
sae.dnn.train(x, y, hidden=c(1), activationfun="sigm", learningrate=0.8, momentum=0.5, learningrate_scale=1, output="sigm", sae_output="linear", numepochs=3, batchsize=100, hidden_dropout=0, visible_dropout=0)最后,我们可以使用训练有素的网络来预测结果nn.predict()。随后,我们可以借助nn.test()错误率将预测转化为错误率。第一次调用需要一个神经网络和相应的观察值作为输入。第二个电话在进行预测时还需要正确的标签和阈值(默认值为0.5)。
predictions = nn.predict(nn, test.x) error_rate = nn.test(nn, test.x, test.y, t=0.5)总而言之,深网代表了一个轻量级的包,其中包含了一系列有限的参数。但是,它提供了多种体系结构。
包 “H2O”
H2O是一个开源软件平台,可以利用分布式计算机系统(H2O 2015)。其核心以Java编码,需要最新版本的JVM和JDK,可以在https://www.java.com/en/downl...。该软件包为许多语言提供接口,最初设计用作基于云的平台(Candel et al。2015)。因此,通过调用h2o.init()以下命令启动H2O :
h2o.init(nthreads = -1)该参数nthreads指定将使用多少个核心进行计算。值-1表示H2O将尝试使用系统上所有可用的内核,但默认为2.此例程也可以使用参数,ip并且portH2O安装在不同的机器上。默认情况下,它将IP地址127.0.0.1与端口54321一起使用。因此,可以在浏览器中定位地址“localhost:54321”以访问基于Web的界面。一旦您使用当前的H2O实例完成工作,您需要通过以下方式断开连接:
h2o.shutdown()示例调用:
所有培训操作h2o.deeplearning()如下:
model <- h2o.deeplearning( x=x, y=y, training_frame=train, validation_frame=test, distribution="multinomial", activation="RectifierWithDropout", hidden=c(32,32,32), input_dropout_ratio=0.2, sparse=TRUE, l1=1e-5, epochs=100)用于在H2O中传递数据的接口与其他包略有不同:x是包含具有训练数据的列的名称的向量,并且y是具有所有名称的变量的名称。接下来的两个参数,training_frame并且validation_frame,是H2O帧的对象。
最后,我们可以使用h2o.predict()以下签名进行预测:
predictions <- h2o.predict(model, newdata=test_data)H2O提供的另一个强大工具是优化超参数的网格搜索。可以为每个参数指定一组值,然后找到最佳组合值h2o.grid()。
超参数优化
H2 =包将训练四种不同的模型,两种架构和不同的L1正则化权重。因此,可以很容易地尝试一些超参数的组合,看看哪一个更好:
深度自动编码器
H2O也可以利用深度自动编码器。为了训练这样的模型,使用相同的功能h2o.deeplearning(),但是这组参数略有不同
在这里,我们只使用训练数据,没有测试集和标签。我们需要深度自动编码器而不是前馈网络的事实由autoencoder参数指定。和以前一样,我们可以选择多少隐藏单元应该在不同的层次。如果我们使用一个整数值,我们将得到一个天真的自动编码器。
训练结束后,我们可以研究重建误差。我们通过特定的h2o.anomaly()函数来计算它。
总的来说,H2O是一个非常用户友好的软件包,可以用来训练前馈网络或深度自动编码器。它支持分布式计算并提供一个Web界面。
包deepr
deepr (deepr 2015)包本身并没有实现任何深度学习算法,而是将其任务转交给H20。该包最初是在CRAN尚未提供H2O包的时候设计的。由于情况不再是这样,我们会将其排除在比较之外。我们也注意到它的功能train_rbm()使用深层的实现rbm来训练带有一些附加输出的模型。
软件包的比较
本节将比较不同指标的上述软件包。其中包括易用性,灵活性,易于安装,支持并行计算和协助选择超参数。另外,我们测量了三个常见数据集“Iris”,“MNIST”和“森林覆盖类型”的表现。我们希望我们的比较帮助实践者和研究人员选择他们喜欢的深度学习包。
安装
通过CRAN安装软件包通常非常简单和流畅。但是,一些软件包依赖于第三方库。例如,H2O需要最新版本的Java以及Java Development Kit。darch和MXNetR软件包允许使用GPU。为此,darch依赖于R软件包gpuools,它仅在Linux和MacOS系统上受支持。默认情况下,MXNetR不支持GPU,因为它依赖于cuDNN,由于许可限制,cuDNN不能包含在软件包中。因此,MXNetR的GPU版本需要Rtools和一个支持C ++ 11的现代编译器,以使用CUDA SDK和cuDNN从源代码编译MXNet。
灵活性
就灵活性而言,MXNetR很可能位列榜首。它允许人们尝试不同的体系结构,因为它定义了网络的分层方法,更不用说丰富多样的参数了。在我们看来,我们认为H2O和darch都是第二名。H20主要针对前馈网络和深度自动编码器,而darch则侧重于受限制的玻尔兹曼机器和深度信念网络。这两个软件包提供了广泛的调整参数。最后但并非最不重要的一点,deepnet是一个相当轻量级的软件包,但是当想要使用不同的体系结构时,它可能是有益的。然而,我们并不推荐将其用于庞大数据集的日常使用,因为其当前版本缺乏GPU支持,而相对较小的一组参数不允许最大限度地进行微调。
使用方便
H2O和MXNetR的速度和易用性突出。MXNetR几乎不需要准备数据来开始训练,而H2O通过使用as.h2o()将数据转换为H2OFrame对象的函数提供了非常直观的包装。这两个包提供了额外的工具来检查模型。深网以单热编码矩阵的形式获取标签。这通常需要一些预处理,因为大多数数据集都具有矢量格式的类。但是,它没有报告关于培训期间进展的非常详细的信息。该软件包还缺少用于检查模型的附加工具。darch,另一方面,有一个非常好的和详细的输出。
总的来说,我们将H2O或者MXNetR看作是这个类别的赢家,因为两者都很快并且在训练期间提供反馈。这使得人们可以快速调整参数并提高预测性能。
并行
深度学习在处理大量数据集时很常见。因此,当软件包允许一定程度的并行化时,它可以是巨大的帮助。表2比较了并行化的支持。它只显示文件中明确说明的信息。
参数的选择
另一个关键的方面是超参数的选择。H2O软件包使用全自动的每神经元自适应学习速率来快速收敛。它还可以选择使用n-fold交叉验证,并提供h2o.grid()网格搜索功能,以优化超参数和模型选择。
MXNetR在每次迭代后显示训练的准确性。darch在每个纪元后显示错误。两者都允许在不等待收敛的情况下手动尝试不同的超参数,因为如果精度没有提高,训练阶段可以提前终止。相比之下,深网不会显示任何信息,直到训练完成,这使得调整超参数非常具有挑战性。
性能和运行时间
我们准备了一个非常简单的性能比较,以便为读者提供有关效率的信息。所有后续测量都是在CPU Intel Core i7和GPU NVidia GeForce 750M(Windows操作系统)的系统上进行的。比较是在三个数据集上进行的:“MNIST” (LeCun等人2012),“Iris” (Fisher 1936)和“森林覆盖类型” (Blackard和Dean 1998)。详情见附录。
作为基准,我们使用H2O包中实现的随机森林算法。随机森林是通过构建多个决策树(维基百科2016b)来工作的集合学习方法。有趣的是,它已经证明了它能够在不进行参数调整的情况下在很大程度上实现高性能。
结果
测量结果在表3中给出,并且在图2,图3和图4中分别针对“MNIST”,“虹膜”和“森林覆盖类型”数据集可视化。
'MNIST'数据集。根据表3和图2,MXNetR和H2O在“MNIST”数据集上实现了运行时间和预测性能之间的优越折衷。darch和deepnet需要相对较长的时间来训练网络,同时达到较低的精度。
'虹膜'数据集。在这里,我们再次看到MXNetR和H2O表现最好。从图3可以看出,深网具有最低的准确性,可能是因为它是如此小的数据集,在训练前误导。正因为如此,darch 100和darch 500/300通过反向传播训练,省略了训练前的阶段。这由表中的*符号标记。
“森林覆盖类型”数据集。H2O和MXNetR显示的准确率大约为67%,但是这还是比其他软件包好。我们注意到darch 100和darch 500/300的培训没有收敛,因此这些模型被排除在这个比较之外。
我们希望,即使是这种简单的性能比较,也可以为从业人员在选择自己喜欢的R包时提供有价值的见解
注意:从图3和图4可以看出,随机森林比深度学习包能够表现得更好。这有几个有效的原因。首先,数据集太小,因为深度学习通常需要大数据或使用数据增强才能正常工作。其次,这些数据集中的数据由手工特征组成,这就否定了深层架构从原始数据中学习这些特征的优势,因此传统方法可能就足够了。最后,我们选择非常相似的(也可能不是最高效的)体系结构来比较不同的实现。
表3. R中不同深度学习包的准确性和运行时间的比较
*仅使用反向传播训练的模型(不进行预训练)。
数据集MNIST鸢尾花森林覆盖类型
准确性 (%)运行时间(秒)准确性 (%)运行时间(秒)准确性 (%)运行时间(秒)
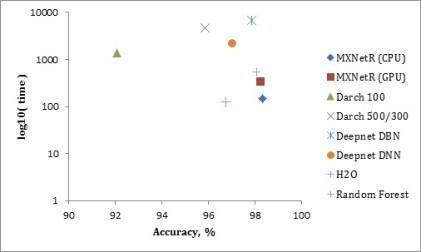
图2.比较“MNIST”数据集的运行时间和准确度。
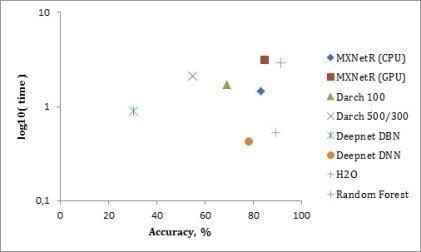
图3.“虹膜”数据集的运行时间和精度比较
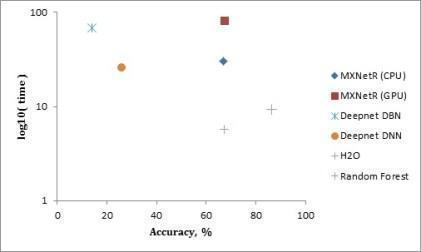
图4.“森林覆盖类型”数据集的运行时间和准确度的比较。
结论
作为本文的一部分,我们在R中比较了五种不同的软件包,以便进行深入的学习:(1)当前版本的deepnet可能代表可用体系结构中差异最大的软件包。但是,由于它的实施,它可能不是最快也不是用户最友好的选择。此外,它可能不提供与其他一些软件包一样多的调整参数。(2)H2O和MXNetR相反,提供了非常人性化的体验。两者还提供额外信息的输出,快速进行训练并取得体面的结果。H2O可能更适合集群环境,数据科学家可以在简单的流水线中使用它来进行数据挖掘和勘探。当灵活性和原型更受关注时,MXNetR可能是最合适的选择。它提供了一个直观的符号工具,用于从头构建自定义网络体系结构。此外,通过利用多CPU / GPU功能,它可以在个人电脑上运行。(3)darch提供了一个有限但是有针对性的功能,重点是深度信念网络。
总而言之,我们看到R对深度学习的支持正在顺利进行。最初,R提供的功能落后于其他编程语言。但是,这不再是这种情况。有了H20和MXnetR,R用户就可以在指尖上使用两个强大的工具。在未来,看到更多的接口 - 例如Caffe或Torch将是可取的。