简介
1)HFile由DataBlock、Meta信息(Index、BloomFilter)、Info等信息组成。
2)整个DataBlock由一个或者多个KeyValue组成。
3)在文件内按照Key排序。
HFile 组织形式
这里只介绍V2版本的,HFileV1的数据格式在0.92版本升级到V2版本。

1)文件分为三部分:Scanned block section,Non-scanned block section,以及Opening-time data section
Scanned block section:表示顺序扫描HFile时(包含所有需要被读取的数据)所有的数据块将会被读取,包括Leaf Index Block和Bloom Block;
Non-scanned block section:HFile顺序扫描的时候该部分数据不会被读取,主要包括Meta Block即BloomFilter和Intermediate Level Data Index Blocks两部分;
Load-on-open-section:这部分数据在HBase的region server启动时,需要加载到内存中。包括FileInfo、Bloom filter block、data block index和meta block index;
Trailer:这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
- 为DataBlockIndex建立多层索引。DataBlockIndex分为Leaf Index Block、Root Data Index(或者multi Root Data index(紫色的Meta Index区域)),
Leaf index block具体存储了DataBlock的offset、length、以及firstkey的信息。
RootDataIndex 存储的是每个Leaf index block的offset、length、Leaf index Block记录的第一个key,以及截至到该Leaf Index Block记录的DataBlock的个数。
假定DataBlock的个数足够多,HFile文件又足够大的情况下,默认的128KB的长度的ROOTDataIndex仍然存在超过chunk大小的情况时,会分成更多的层次。这样最终的可能是ROOT INDEX –> IntermediateLevel ROOT INDEX(可以是多层) —〉Leaf index block
在ROOT INDEX中会记录Mid Key所对应的信息,帮助在做File Split或者折半查询时快速定位中间Row的信息。
写HFile
HFile V2的写操作流程:
1)Append KV到 Data Block。在每次Append之前,首先检查当前DataBlock的大小是否超过了默认的设置,如果不超出阈值,写入输出流。如果超出了阈值,则执行finishBlock(),按照Table-CF的设置,对DataBlock进行编码和压缩,然后写入HFile中。//以Block为单位进行编码和压缩,会有一些性能开销,可以参考HBase实战系列1—压缩与编码技术
2)根据数据的规模,写入Leaf index block和Bloom block。
Leaf index Block,每次Flush一个DataBlock会在该Block上添加一条记录,并判断该Block的大小是否超过阈值(默认128KB),超出阈值的情况下,会在DataBlock之后写入一个Leaf index block。对应的控制类:HFileBlockIndex,内置了BlockIndexChunk、BlockIndexReader和BlockIndexWriter(实现了InlineBlockWriter接口)。
Bloom Block设置:默认使用MURMUR hash策略,每个Block的默认大小为128KB,每个BloomBlock可以接收的Key的个数通过如下的公式计算,接收的key的个数 与block的容量以及errorRate的之间存在一定的关系,如下的计算公式中,可以得到在系统默认的情况下,每个BloomBlock可以接纳109396个Key。
注意:影响BloomBlock个数的因素,显然受到HFile内KeyValue个数、errorRate、以及BlockSize大小的影响。可以根据应用的需求合理调整相关控制参数。
每一个BloomBlock会对应index信息,存储在Meta Index区域。
这样在加载数据的时候,只需加载不超过128KB的RootDataIndex以及IntermediateLevelRootIndex,而避免加载如HFile V1的所有的Leaf index block信息,同样,也只需要加载BloomBlockIndex信息到内存,这样避免在HFile V1格式因为加载过大的DataBlockIndex造成的开销,加快Region的加载速度。
读HFile
在HFile中根据一个key搜索一个data的过程:
1、先内存中对HFile的root index进行二分查找。如果支持多级索引的话,则定位到的是leaf/intermediate index,如果是单级索引,则定位到的是data block
2、如果支持多级索引,则会从缓存/hdfs(分布式文件系统)中读取leaf/intermediate index chunk,在leaf/intermediate chunk根据key值进行二分查找(leaf/intermediate index chunk支持二分查找),找到对应的data block。
3、从缓存/hdfs中读取data block
4、在data block中遍历查找key。
读取HFile
1、 首先读取文件尾的4字节Version信息(FileTrailer的version字段)。
2、 根据Version信息得到Trailer的长度(不同版本有不同的长度),然后根据trailer长度,加载FileTrailer。
3、 加载load-on-open部分到内存中,起始的文件偏移地址是trailer中的loadOnOpenDataOffset,load-on-open部分长度等于(HFile文件长度 - HFileTrailer长度)
Load-on-open各个部分的加载顺序如下:
依次加载各部分的HFileBlock(load-on-open所有部分都是以HFileBlock格式存储):data index block、meta index block、FileInfo block、generate bloom filter index、和delete bloom filter。HFileBlock的格式会在下面介绍。
HFile Block
在hfile中,所有的索引和数据都是以HFileBlock的格式存在在hdfs中,
HFile version2的Block格式如下两图所示,有两种类型,第一种类型是没有checksum;第二种是包含checksum。对于block,下图中的绿色和浅绿色的内存是block header;深红部分是block data;粉红部分是checksum。
第一种block的header长度= 8 + 2 * 4 + 8;
第二种block的header长度=8 + 2 * 4 + 8 + 1 + 4 * 2;
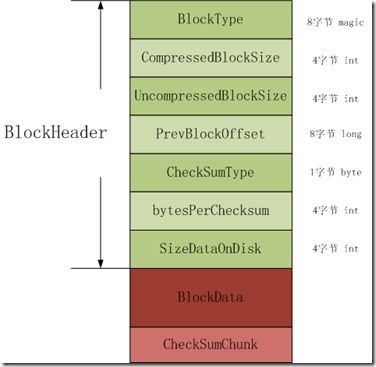
BlockType:8个字节的magic,表示不同的block 类型。
CompressedBlockSize:表示压缩的block 数据大小(也就是在HDFS中的HFileBlock数据长度),不包括header长度。
UncompressedBlockSize:表示未经压缩的block数据大小,不包括header长度。
PreBlockOffset:前一个block的在hfile中的偏移地址;用于访问前一个block而不用跳到前一个block中,实现类似于链表的功能。
CheckSumType:在支持block checksum中,表示checksum的类型。
bytePerCheckSum:在支持checksum的block中,记录了在checksumChunk中的字节数;records the number of bytes in a checksum chunk。
SizeDataOnDisk:在支持checksum的block中,记录了block在disk中的数据大小,不包括checksumChunk。
DataBlock
DataBlock是用于存储具体kv数据的block,相对于索引和meta(这里的meta是指bloom filter)DataBlock的格式比较简单。
在DataBlock中,KeyValue的分布如下图,在KeyValue后面跟一个timestamp。

HFile Index
HFile中的index level是不固定的,根据不同的数据类型和数据大小有不同的选择,主要有两类,一类是single-level(单级索引),另一类是multi-level(多级索引,索引block无法在内存中存放,所以采用多级索引)。
HFile中的index chunk有两大类,分别是root index chunk、nonRoot index chunk。而nonRoot index chunk又分为interMetadiate index chunk和leaf index chunk,但intermetadiate index chunk和leaf index chunk在内存中的分布是一样的。
对于meta block和bloom block,采用的索引是single-level形式,采用single-level时,只用root index chunk来保存指向block的索引信息(root_index-->xxx_block)。
而对于data,当HFile的data block数量较少时,采用的是single level(root_index-->data_block)。当data block数量较多时,采用的是multi-level,一般情况下是两级索引,使用root index chunk和leaf index chunk来保存索引信息(root_index-->leaf_index-->data_block);但当data block数量很多时,采用的是三级索引,使用root index chunk、intermetadiate index chunk和leaf index chunk来保存指向数据的索引(root_index-->intermediate_index-->leaf_index-->data_block)。
所有的index chunk都是以HFileBlock格式进行存放的,首先是一个HFileBlock Header,然后才是index chunk的内容。
Root Index
Root index适用于两种情况:
1、作为data索引的根索引。
2、作为meta和bloom的索引。
在Hfile Version2中,Meta index和bloom index都是single-level,也都采用root索引的格式。Data index可以single-level和multi-level的这形式。Root index可以表示single-level index也可以表示multi-level的first level。但这两种表示方式在内存中的存储方式是由一定差别,见图。

对于multi-level root index,除了上面index entry数组之外还带有格外的数据mid-key的信息,这个mid-key是用于在对hfile进行split时,快速定位HFile的中间位置所使用。Multi-level root index在硬盘中的格式见图3.4。
Mid-key的信息组成如下:
1、Offset:所在的leaf index chunk的起始偏移量
2、On-disk size:所在的leaf index chunk的长度
3、Key:在leaf index chunk中的位置。
