原创 | 工业场景中的预测性维护

在社会整体安全水平日益提升的大背景下,因工业设备的故障导致的重大事故愈发受到社会的深切关注。以化工行业为例,令人痛心的安全事故屡屡发生,2019年甚至被称为化工行业的“本命年”,自19年年初至19年4月25日,以响水“3•21”爆炸事故为代表的重大事故致使148人死亡或失联。
生产管理学中著名的“海恩法则”指出: 每一起严重事故的背后,必然有29次轻微事故和300起未遂先兆以及1000起事故隐患。经分析,相当多的恶性事故发生前,现场的传感器数据都表现出了明显的异常,完全可以通过监测、报警等方式及时预警并启动预案,防患于未然。本文结合个人实践经验,主要从监督学习与异常检测这两种视角看待问题,尝试在适当的假定下解决之。
监督学习视角
如果数据容易标记,可以标记到时间窗,做有监督学习分类模型。这里分为两种方式:
第一种是传统特征工程设计,将生成的特征输入到机器学习模型中。工业场景中常见的数据不平衡、样本量小、过拟合等问题,都应纳入基本考量。
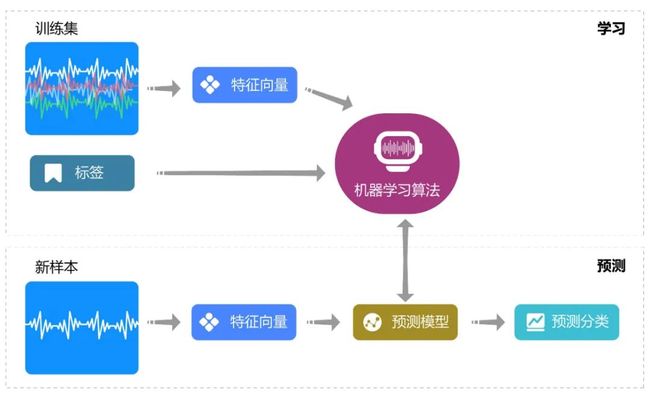
图 机器学习分类框架
第二种是:用NN模型直接进行序列分类。值得一提的是,LSTM-FCN和ALSTM-FCN在序列信号进行分类的任务中表现出很好的效果。
在许多工业场景中,手工设计特征需要工业领域甚至是特定工艺的深入业务理解,要设计基本统计、功率谱参数、业务衍生等多层次特征。特别是业务衍生特征,如果现场工程师提供了一个超强的特征(即magic feature),例如某真空蒸发器在同时出现负压超过68kPa,温度超过90℃的情况下极易致使损坏,那么该真空蒸发器的预警建模难度就会大大降低。
树模型给出的特征重要度可为特征提供优良的可解释性,对异常追根溯源有很好的指导作用。
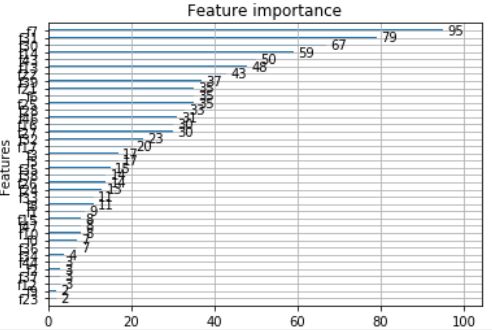
图 xgboost的特征重要性排序
深度学习的优点是端到端的快速解决问题,绕过了成本高昂的特征工程,极大降低了业务知识门槛,而缺点是与之俱来的可解释性问题。好消息是机器学习正朝着更高的易用性、更低的技术门槛、更敏捷的开发成本的方向去发展,Auto-ML极大减少了手工工作,其中自动化特征工程旨在自动创建候选特征。在时序数据分类问题上,使用tsfresh可以自动抽取超过100个特征子集(每个特征子集根据参数设置包含一个或多个特征)。

图 tsfresh的时序特征抽取
为了避免提取无关的功能,tsfresh具有内置的过滤过程,这一过程评估每个特征的解释能力和重要性。我们也可使用标准的Filter、Wrapper、Embedded。
有时样本的标记成本高,我们可以使用半监督学习的方法--使用协同学习 (co-training),用有标记的数据迭代生成伪标记。
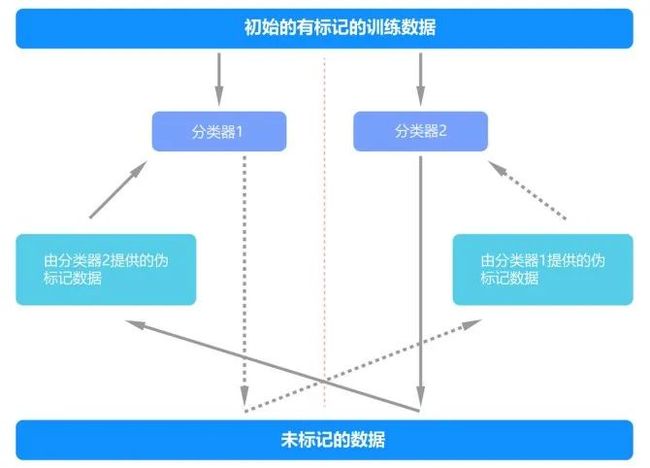
图 协同学习的标记过程
异常检测视角
接下来让我们从异常检测的视角去审视同样的问题,这里的异常表示广义的故障,即过程中至少一个特征或变量发生异常偏离。我们经常面对样本没有标记或标记主观差异性大的现实,可以说,无监督学习或者基于统计的离群点检测是工作的重点。
一般来说“异常”数据内含2个假定:1.具有某种比例稀少的特征。2.最少在某个隐空间中,与其他数据是A与A-bar(只有落在某区域才正常)或者A、B、C、D(异常数据自成一类)这样的关系。
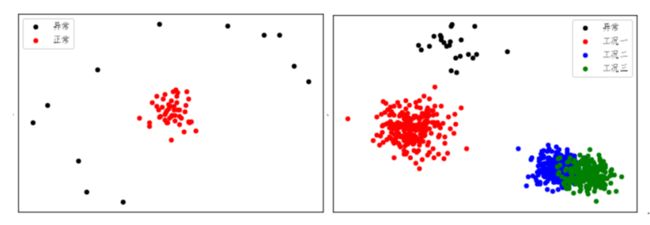
图 正常数据与异常数据的两种关系
下面介绍几类效果较好的异常检测算法的原理及其适用场景。
一、基于统计的方法
这一类方法最为简单直接,且很多场景中相当有效。
在某个序列不含多个模式的时候,(举例)我们姑且默认某个数据分布近似正态分布,在1、2、3倍标准差内会有68%、95%、99%的数据,我们稍微放宽对分布的假设,可以想到箱线图。考虑把上下触须作为数据分布的边界,任何超过内限(或者外限)数据点都可以认为是离群点或异常值。
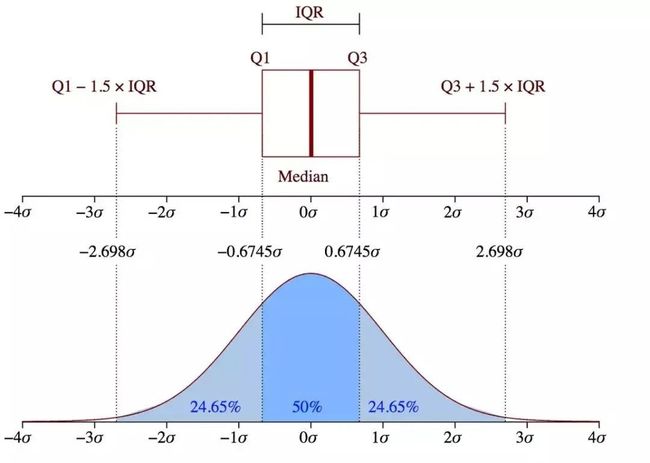
图 箱线图与正态分布
在实践中,应当注意“训练数据”的正常性,如果在适用一维GMM的数据(例如有开车、停车两种模式的电流测点数据)上使用该方法,效果应该不会很理想。
二、基于距离的方法
基于距离的方法同样是忽略了时序,只不过对象从单个测量值变成了时窗,在做完特征构建后,每个时窗都投射成了高维空间中的点。
用简单的K近邻就可以很好地进行异常检验,前提是我们构造特征空间的过程是合适的。一个样本点和它的第k个近邻的距离(或平均距离)就可以被当做score,显然异常点的score比较大。同样,具有噪声的基于密度的聚类方法(DBSCAN)和局部离群因子检测方法( LOF)通过计算数据密度来检测异常。当然,这同样要求在特征空间异常点所在空间的数据点少,密度低。孤立森林(IF)的原理也有异曲同工之妙,它假定远离主流样本的点可以被更少的超平面分离。
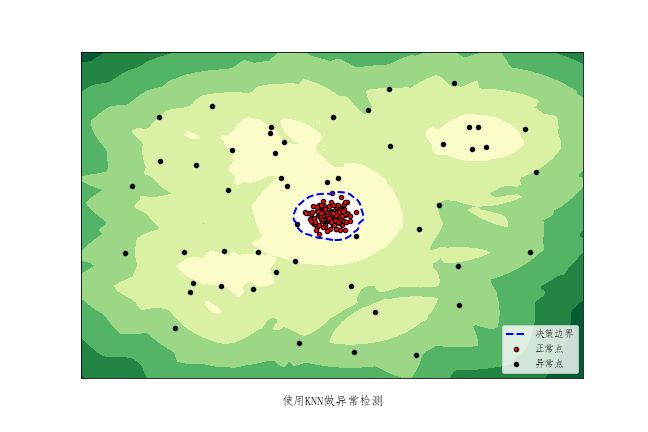
图 基于KNN的异常检测
除这些方法外,也可以直接对样本的协方差矩阵分析,把样本的马氏距离看作样本点的异常度。
三、基于重建误差
如果我们能标记或取得一些正常样本点,我们可以用“有罪推定”的想法,即“不像好的,那就是坏的”,利用重建误差做异常检测。在工业生产中,取正常样本是较为简单的事。
假设数据在低维空间上有嵌入,那么在低维空间投射后表现不好的数据点就可以认为是异常点。具体来说,PCA找到k个特征向量,计算每个样本再经过这k个特征向量投射后的重建误差,正常点的重建误差应小于异常点。
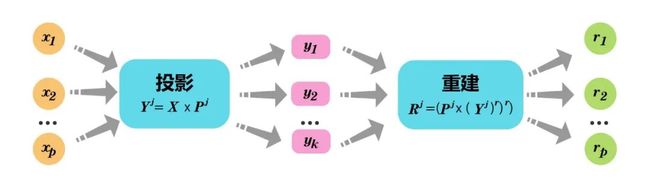
图 基于PCA的重构数据计算
利用同样的思想,我们也可以用自动编码器(AE)/GAN实现,基本上假设是异常点服从不同的分布。根据正常数据训练出来的AE,能够将正常样本重建还原,但是却无法将异于正常分布的数据点较好地还原,重建误差较大。在LSTM-GAN中,以 LSTM 为基本模型来捕获时间上的依赖关系,并将其嵌入到 GAN 的框架中,利用 GAN 的生成器和判别器来检测异常,利用判别器得到判别损失,利用生成器得到重建的损失。
四、基于时间序列预测
在工业场景中考虑时序的异常检测,与客流量预测、网络KPI异常检测等不太一样,因为很多测点的剧烈升降是客观的操作行为,我们可以结合监督学习过滤掉这些手动操作产生的错误告警。一般来说,考虑时序的异常检测可以分为对比与预测这两大类的方法。
对比方法指的是移动平均、绝对偏差等方法,这类方法用时序上最近的若干数据点做样本,和一个总体序列进行比对,不同的只是比对的对象。计算后常用残差的标准差判定异常。

图 使用滑动平均计算误差
预测方法包含统计上的分解方法、其他可用于时序预测的ML模型。这类方法实际上是预测某个时间点的数值,再衡量这个时间点的真实值与预测值的差值是否超过给定阈值,从而判定异常。
其中,STL会把时间序列分解为趋势项、季节项和余项。这种方法该方法的优点在于其简单性和健壮性。
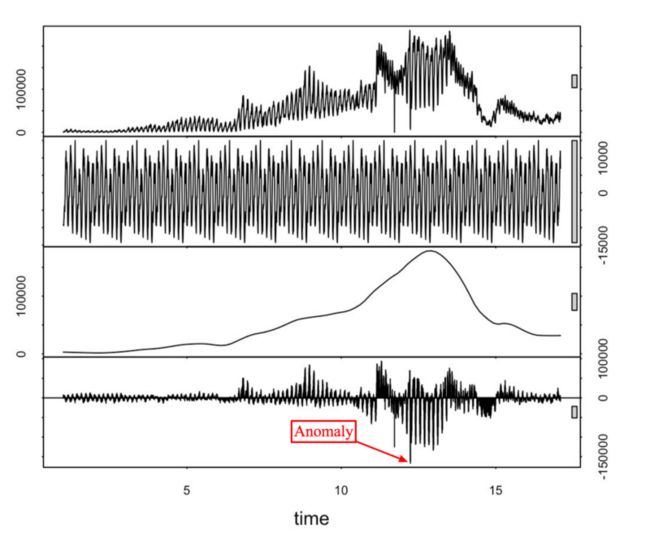
图 基于STL的残差计算
同样,我们也可使用LSTM等模型得到预测序列,之后可用使用格拉布斯法判断残差值。
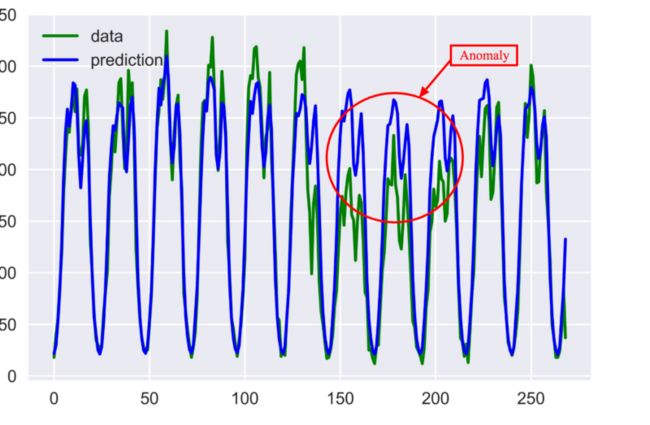
图 借助时序预测进行异常检测
五、预警上下限/预警带
在很多工业监测平台上,都标配预警上下限/预警带功能,这一功能直观且具有兜底能力,工厂管理人员与技术人员对此接受程度很高。
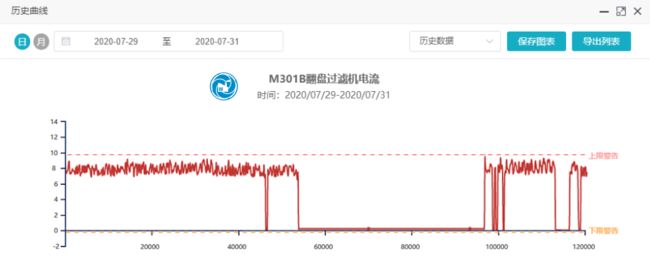
图 人工设置的监测预警带
这种方法有一些不足之处:
1. 只能针对一种工况,即使只有“开车/停车”,也只能设置-0.2-9.7这种包含两种模式大部分数据的预警带;
2. 太宽会漏掉异常,太窄会大量误报警。
结合基于距离、时间序列的一些方法,我们优化了预警带的效果。针对不同的工况,模型会给出特定的预警带,实现了更准确的监控,顺便也完成了不同工况生产的数据统计。
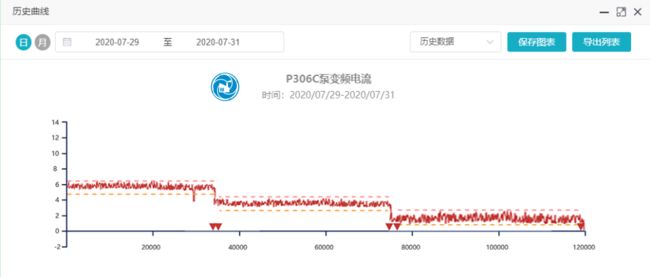
图 多工况模型控制的监测预警带
未来展望
故障监测、预测的解决方案与实施路径是很多的,在探索这些问题的同时,还可以结合寿命预测与维修决策共同研究:
1. 通过不同类型异常事件与设备寿命的建模,可以做基于预测信息的细化设备健康管理研究。
2. 工厂中有大量手工填写的维修记录表,如果可以做好基于NLP的粗糙故障信息知识表示与故障信息挖掘研究,有望形成故障树或者其他形式的智能维修决策。
工业场景中,我们探索如何从传感器数据中提取有价值的信息,工厂的数字化使得企业能够将人力聚焦于纯粹的生产。智能化的预知故障能够及时发现早期故障及隐患,减少继发性事故及恶性事故发生,对安全生产具有重要意义。
编辑:文婧
校对:林亦霖