大数据Zookeeper_05
简介
Zookeeper 是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务。
分布式应用程序可以基于它实现数据同步服务,配置维护和命名空间服务等
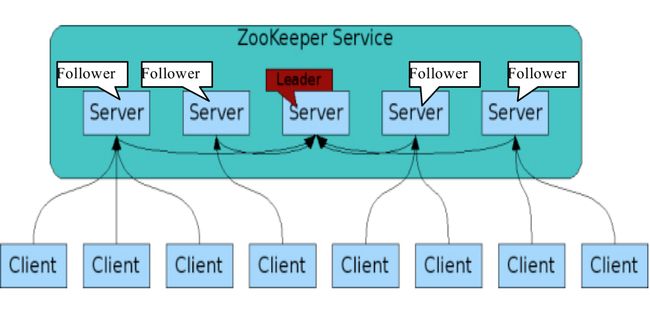
上图的讲解:
Zookeeper本身就是一个集群(意味着有好多的机器),为了保证Zookeeper服务的高可靠性,所以我们搭建了多台机器。即使有多台机器宕掉了也不会影响Zookeeper服务。Zookeper中的机器的数量是有要求的,必须是奇数台,既想实现高的可靠性还能让其正常的工作,至少使用3台,这样就可以允许有一台机器当掉,只要有一半以上的机器运行就能正常的工作。不需要太多的Zookeeper,2000多台机器允许有7台Zookeeper。
上图中5台机器组成了一个Zookeeper的服务,这5天机器中有着两种角色:Follower和Leader。Leader只有一个,Follower 有多个。当Leader机器当掉了,可以从另外的几台机器中选出一台作为Leader。
Zookeeper的数据同步服务功能:
比如有一台机器的配置文件中有一个变量为a=1;当使用客户端将这个数据改为a=100;为了做到对这个集群中数据进行同步,Leader检测到某台机器的数据发生变化,Leader会将这份数据进行同步,然后再将这份数据在各个几点之间进行同步。在这里有个锁的服务,就是说当数据在同步的时候,如果客户端有对数据的访问就必须等待,当数据同步完成以后,才能进行数据的访问。
Zookeeper提供少量数据(客户端)的存储和管理,客户端的数据可以向Zookeeper的集群中存储,Zookeper会将这些数据在集群的内部进行同步,也就是说在各个节点之间将这些数据进行同步,来保持这些数据在整个集群里面的一致性。
Zookeeper集群的两种角色:Follower和Leader。Leader是一个主节点,所有数据的写操作都是由Leader来实现的。当客户端向server端写数据的时候,都是Leader来实现数据的同步。当这个集群中超过一半的节点把这份数据跟新成功了,它就认为这份数据更新成功了。
Zookeeper能帮我们做什么?
1、Hadoop2.0,使用Zookeeper的事件处理,确保整个集群只有一个活跃的NameNode,存储配置信息等.
2、HBase,使用Zookeeper的事件处理,确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等.
Zookeeper的特性
Zookeeper是简单的(不需要写代码,只需要做配置即可)。
Zookeeper是富有表现力的(功能强大)。
Zookeeper具有高可用性(Apache下)。
Zookeeper采用松耦合交互方式。
Zookeeper是一个资源库。
Zookeeper的安装和配置(单机模式)
前期准备就不详细说了
1.修改Linux主机名
2.修改IP
3.修改主机名和IP的映射关系
注意:如果你们公司是租用的服务器或是使用的云主机(如华为用主机、阿里云主机等)
/etc/hosts里面要配置的是内网IP地址和主机名的映射关系
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等
解压Zookeeper
将Zookeeper的压缩包解压到/usr/local 目录下
tar -zxvf zookeeper-3.4.5.tar.gz -C /usr/local/
使用命令切换到 zookeeper-3.4.5 /conf目录下
使用mv zoo_sample.cfg zoo.cfg将zoo_sample.cfg重命名为zoo.cfg
启动Zookeeper的服务端
切换到 bin目录下zkServer.sh start命令启动Zookeeper
启动Zookeeper的客户端
zkCli.sh1、在Zookeeper目录下使用命令
Ls /
查看Zookeeper的根目录为Zookeeper
2、create命令
create /itcast0106 8000$ 暂时认为itcast0106为一个文件夹
Zookeeper的安装和配置(集群模式)
软件环境:
Linux 服务器 一台;三台;五台(2*n+1台)
Java jdk1.7.0
Zookeeper 3.4.6稳定版
Zookeeper集群的搭建很简单,只需要将搭建好的一台Zookeeper拷贝到其他的节点即可。
使用命令切换到conf目录下,修改zoo.cfg
vim zoo.cfg
zookeeper的默认配置文件为zookeeper/conf/zoo_sample.cfg,需要将其修改为zoo.cfg。其中各配置项的含义,解释如下:
1.tickTime:CS通信心跳时间
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime=2000
2.initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=5
3.syncLimit:LF同步通信时限
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
syncLimit=2
4.dataDir:数据文件目录
Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
dataDir=/home/michael/opt/zookeeper/data
即:dataDir=/usr/local/zookeeper-3.4.5/data
5.clientPort:客户端连接端口
客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
clientPort=2181
6.服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
这个配置项的书写格式比较特殊,规则如下:
server.N=YYY:A:B
server.1=weekend11:2888:3888
server.2=weekend12:2888:3888
server.3=weekend13:2888:3888
创建存放数据的目录
切换到zookeper-3.4.5 创建data目录 mkdir data
在这个目录下创建一个文件为myid touch myid
给这个文件添加内容 vim myid 添加的值为服务器的编号
将创建好的zookeeper拷贝到其他的节点。
scp -r /usr/local/zookeeper-3.4.5 root@weekend12
scp -r /usr/local/zookeeper-3.4.5 root@weekend13
并且修改 myid文件中的内容其内容的值为对应的服务器编号。
在weekend11、weekend12、weekend13的节点上 启动服务器端:切换到bin目录下 执行 zkServer.sh start命令 查看启动的状态 :zkServer.sh status
数据同步的演示
在weekend11的机器上启动一个客户端 结果连接到本地
在zookeeper的根目录下创建一个文件夹为hadoop123其值为123
create /hadoop123 123

在weekend11、weekend12查看数据是否同步完成
演示Leader宕掉看是否能够实现Leader的切换
将weekend11的进程杀死
然后再去查看weekend12和weekend13的状态 发现weekend13变为了Leader weekend12为follower
在启动weekend11 发现其状态变为follower