Lucene之入门案例-yellowcong
这个是一个简单的Lucene案例,基本包含了如何建立一个Lucene索引和如何读取Lecene的索引。
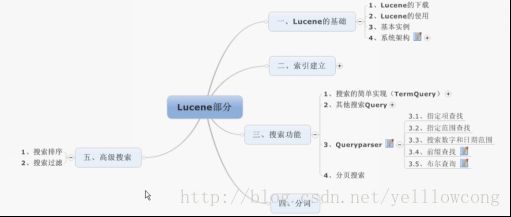
Lucene的学习结构
案例
建立索引
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:上午11:54:53
* 机能概要:建立索引
* @throws Exception
*/
public void index() throws Exception{
//1.创建索引
String path = this.getIndexPath();
//打开索引目录
FSDirectory fs = FSDirectory.open(new File(path));
//2.创建IndexWrite
IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_45, new StandardAnalyzer(Version.LUCENE_45));
//新建一个索引
IndexWriter writer = new IndexWriter(fs, cfg);
//3.创建Document 对象
String targetpath = "E:/服务器学习";
this.getFile(new File(targetpath));
//遍历里面的文件,建立索引
for(File file:files){
//4.建立索引文档
Document doc = new Document();
//添加索引,但是不分析
doc.add(new Field("path",file.getPath(), Field.Store.YES,Field.Index.NOT_ANALYZED));
//索引的名称存储
doc.add(new Field("name", file.getName(),Field.Store.YES,Field.Index.ANALYZED));
//5.添加文档到索引 中
writer.addDocument(doc);
System.out.println(file.getPath());
}
writer.close();
}读取索引
//读取索引
public void search(String keyword) throws Exception{
//1.创建索引
String path = this.getIndexPath();
//打开索引目录
FSDirectory fs = FSDirectory.open(new File(path));
//2.获取IndexReader 读取索引
IndexReader reader = IndexReader.open(fs);
//3.根据IndexReader c创建IndexSeacher
IndexSearcher searcher = new IndexSearcher(reader);
//4.创建搜索Query
//创建parser 来确定索索文件的内容 ,就是搜索文件的哪一个部分
QueryParser parser = new QueryParser(Version.LUCENE_45, "name",new StandardAnalyzer(Version.LUCENE_45));
//5.创建Query ,表示搜索的域中包含Java的文档
Query query = parser.parse(keyword);
//6.根据Seacher 搜索返回TopDose , 10表示查询10条
TopDocs docs = searcher.search(query, 10);
//7.根据TopDocs 获取SocreDoc
for(ScoreDoc result : docs.scoreDocs){
//根据id来获取到document
Document doc = searcher.doc(result.doc);
//获取索引的文件名称
System.out.println(doc.get("name")+"\r"+doc.get("path"));
}
}整体代码
package com.yellowcong.demo;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* 创建用户:狂飙的yellowcong
* 创建时间:上午11:53:52
* 创建日期:2017年12月2日
* 机能概要:索引我的笔记文件夹,然后输入关键词,获取到文件
*/
public class HelloDemo {
//索引存储的地址
private static final String INDEX_PATH = "index";
//用来存储File
private static List files = new ArrayList();
public static void main(String [] args) throws Exception{
HelloDemo demo = new HelloDemo();
//建立索引
//demo.index();
demo.search("韩顺平");
}
//读取索引
public void search(String keyword) throws Exception{
//1.创建索引
String path = this.getIndexPath();
//打开索引目录
FSDirectory fs = FSDirectory.open(new File(path));
//2.获取IndexReader 读取索引
IndexReader reader = IndexReader.open(fs);
//3.根据IndexReader c创建IndexSeacher
IndexSearcher searcher = new IndexSearcher(reader);
//4.创建搜索Query
//创建parser 来确定索索文件的内容 ,就是搜索文件的哪一个部分
QueryParser parser = new QueryParser(Version.LUCENE_45, "name",new StandardAnalyzer(Version.LUCENE_45));
//5.创建Query ,表示搜索的域中包含Java的文档
Query query = parser.parse(keyword);
//6.根据Seacher 搜索返回TopDose , 10表示查询10条
TopDocs docs = searcher.search(query, 10);
//7.根据TopDocs 获取SocreDoc
for(ScoreDoc result : docs.scoreDocs){
//根据id来获取到document
Document doc = searcher.doc(result.doc);
//获取索引的文件名称
System.out.println(doc.get("name")+"\r"+doc.get("path"));
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:上午11:54:53
* 机能概要:建立索引
* @throws Exception
*/
public void index() throws Exception{
//1.创建索引
String path = this.getIndexPath();
//打开索引目录
FSDirectory fs = FSDirectory.open(new File(path));
//2.创建IndexWrite
IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_45, new StandardAnalyzer(Version.LUCENE_45));
//新建一个索引
IndexWriter writer = new IndexWriter(fs, cfg);
//3.创建Document 对象
String targetpath = "E:/服务器学习";
this.getFile(new File(targetpath));
//遍历里面的文件,建立索引
for(File file:files){
//4.建立索引文档
Document doc = new Document();
//添加索引,但是不分析
doc.add(new Field("path",file.getPath(), Field.Store.YES,Field.Index.NOT_ANALYZED));
//索引的名称存储
doc.add(new Field("name", file.getName(),Field.Store.YES,Field.Index.ANALYZED));
//5.添加文档到索引 中
writer.addDocument(doc);
System.out.println(file.getPath());
}
writer.close();
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午12:14:54
* 机能概要:遍历文件夹,获取所有文件
* @param file
*/
public void getFile(File file){
if(file.isFile()){
files.add(file);
}else{
//文件夹下面的文件
File [] childFile = file.listFiles();
for(File child:childFile){
if(child.isFile()){
files.add(child);
}else{
getFile(child);
}
}
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午12:05:52
* 机能概要:获取索引目录
* @return
*/
public String getIndexPath(){
//获取索引的目录
String path = HelloDemo.class.getClassLoader().getResource("index").getPath();
//不存在就创建目录
File file = new File(path);
if(!file.exists()){
file.mkdirs();
}
return path;
}
}
环境搭建
工程目录

pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>yellowconggroupId>
<artifactId>day12_02artifactId>
<version>0.0.1-SNAPSHOTversion>
<packaging>jarpackaging>
<name>day12_02name>
<url>http://maven.apache.orgurl>
<repositories>
<repository>
<id>aliyunmavenid>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
repository>
repositories>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<lucene.version>4.5.1lucene.version>
properties>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.10version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-coreartifactId>
<version>${lucene.version}version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-queryparserartifactId>
<version>${lucene.version}version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-analyzers-commonartifactId>
<version>${lucene.version}version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-highlighterartifactId>
<version>${lucene.version}version>
dependency>
dependencies>
project>