深入理解 hash 函数、HashMap、LinkedHashMap、TreeMap 【中】
LinkedHashMap - 有序的 HashMap
我们之前讲过的 HashMap 的性能表现非常不错,因此使用的非常广泛。但是它有一个非常大的缺点,就是它内部的元素都是无序的。如果在遍历 map 的时候, 我们希望元素能够保持它被put进去时候的顺序,或者是元素被访问的先后顺序,就不得不使用 LinkedHashMap。
LinkdHashMap 继承了 HashMap,因此,它具备了 HashMap 的优良特性-高性能。在HashMap 的基础上, LinkedHashMap 又在内部维护了一个链表,用来存放元素的顺序。因此,我们可以将 LinkedHashMap 理解为在内部增加了一个链表的 HashMap。
LinkedHashMap 提供了两种类型的顺序:元素插入的顺序 和 元素最近访问的顺序。可以通过下面构造函数指定排序方式。
/**
* Constructs an empty LinkedHashMap instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - true for
* access-order, false for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}accessOrder 为 true 时为访问顺序排列,false 为插入顺序排列。
通过上节我们知道,HashMap 中的 Entry 包括 key,value,next 指针以及 hash 值。而 LinkedHashMap 通过继承它,实现了 LinkedHashMap.Entry , 为 HashMap.Entry 增加了 before 和 after 属性用来记录某一表项的前驱和后继,并构成循环链表。因此,它的 Entry table 结构如下图:
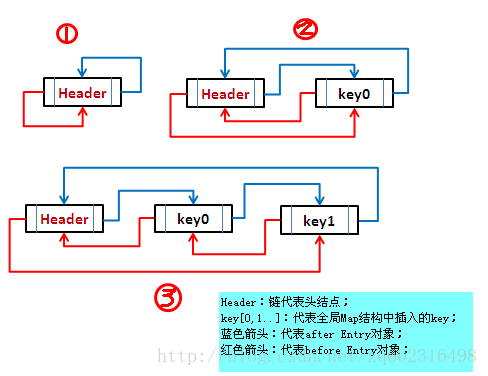
以下代码实例,展示了 LinkedHashMap 的有序性:
public static void main(String[] args){
Map map = new LinkedHashMap();
map.put("1", "aa");
map.put("2", "bb");
map.put("3", "cc");
map.put("4", "dd");
map.get("3");
for(Iterator it = map.keySet().iterator();it.hasNext();){
String name = it.next();
System.out.println(name+"-->"+map.get(name));
}
} 输出结果为:
1-->aa
2-->bb
3-->cc
4-->dd
如果将实现改为 HashMap,则输出结果为:
3-->cc
2-->bb
1-->aa
4-->dd
可以看到,LinkedHashMap 迭代中,很好的保持了元素输入时候的顺序。我们还可以将其顺序改为按照访问时间排序:
Map
结果出乎意料,抛出了异常:java.util.ConcurrentModificationException 。
我们知道,实现了 Iterable 接口都会在集合内部维护一个 modcount 的变量,当集合元素被改动的时候,便会自动递增。这是防止使用迭代器的时候,代码修改原集合状态。这种情况一般是由于用户迭代过程中调用了 remove add 等方法。但这里为什么会报这种异常呢?问题就在 LinkedHashMap 的 get 方法上。一般认为 get 方式是只读的,但是当前的 LinkedHashMap 工作在元素访问顺序排序的模式中,get 方法会修改 LinkedHashMap 中的链表结构,以便将最近访问的元素放置到链表的末尾,因此,LinkedHashMap 工作在这种模式的时候,不能使用 get 操作。
TreeMap - 另一种 Map 实现
HashMap 通过 hash 算法可以最快速的进行 put() 和 get() 操作。TreeMap 则提供了一种完全不同的 Map 实现。从功能上讲,TreeMap 有着比 HashMap 更为强大的功能,它实现了 SortedMap 接口,这意味着它可以对元素进行排序。而且与 LinkedHashMap 基于元素进入顺序和元素访问顺序排列相比,TreeMap 是基于元素的固有顺序排列的(由 Comparator 或者 Comparable 确定)。然而,TreeMap 的性能略低于 HashMap 。
虽然性能略有逊色,但是,如果在开发中需要对元素进行排序,TreeMap 就成为了不二选择。TreeMap 提供的有关排序的接口如下:
public SortedMap subMap(K fromKey, K toKey)
public SortedMap headMap(K toKey)
public SortedMap tailMap(K fromKey)
public K firstKey()
public K lastKey() 1) 在 TreeMap 的构造函数中注入一个 Comparator。
public TreeMap(Comparator comparator)
2) 使用实现了 Comparable 接口的 key。
对 TreeMap 而言,排序是一个必须的过程,因此,要正常使用 TreeMap ,必须指定排序规则,否则会抛出 java.lang.ClassCastException 异常。
TreeMap 的内部实现是基于红黑树的。红黑树是一种平衡查找树,它的统计性能要由于平衡二叉树。有良好的最坏运行时间,可以再 O(log n) 时间内做查找、插入和删除,n 表示树中元素的个数。
下面以一个实例展示 TreeMap 对排序的支持。假设现在需要对学生的成绩进行统计,以学生的成绩排序,需要通过统计的范围筛选出符合条件的学生,并查找这些学生的详细信息。这样的功能仅使用 HashMap 来时间是相当费力的,排序算法也需要在应用程序中自己实现,其效率也取决于程序员对算法的理解,较难得到保证。而是用 TreeMap 则可以高效且方便的实现以上功能。
public class Student implements Comparable {
public Student(String name, int score) {
this.name = name;
this.score = score;
}
String name;
int score;
@Override
public int compareTo(Student o) {
return score == o.score ? 0 : score > o.score ? 1 : -1;
}
@Override
public String toString() {
StringBuffer sb = new StringBuffer();
sb.append("name:");
sb.append(name);
sb.append(" ");
sb.append("score:");
sb.append(score);
return sb.toString();
}
public static void main(String[] args) {
Map map = new TreeMap();
Student s1 = new Student("Billy", 70);
Student s2 = new Student("David", 85);
Student s3 = new Student("Kite", 92);
Student s4 = new Student("Cissy", 68);
map.put(s1, new StudentDetailInfo(s1));
map.put(s2, new StudentDetailInfo(s2));
map.put(s3, new StudentDetailInfo(s3));
map.put(s4, new StudentDetailInfo(s4));
// 筛选出成绩介于 Cissy 和 David 之间的所有学生
Map map1 = ((TreeMap) map).subMap(s4, s2);
for (Iterator it = map1.keySet().iterator(); it.hasNext();) {
Student key = it.next();
System.out.println(key + "->" + map1.get(key));
}
System.out.println("subMap end");
// 筛选出成绩低于 Billy的所有学生
Map map2 = ((TreeMap) map).headMap(s1);
for (Iterator it = map2.keySet().iterator(); it.hasNext();) {
Student key = it.next();
System.out.println(key + "->" + map2.get(key));
}
System.out.println("headMap end");
// 筛选出成绩大于等于 Billy的所有学生
Map map3 = ((TreeMap) map).tailMap(s1);
for (Iterator it = map3.keySet().iterator(); it.hasNext();) {
Student key = it.next();
System.out.println(key + "->" + map3.get(key));
}
System.out.println("tailMap end");
}
}
class StudentDetailInfo {
Student s;
public StudentDetailInfo(Student s) {
this.s = s;
}
@Override
public String toString() {
return s.name + "'s detail infmation";
}
} 运行结果如下:
name:Cissy score:68->Cissy's detail infmation
name:Billy score:70->Billy's detail infmation
subMap end
name:Cissy score:68->Cissy's detail infmation
headMap end
name:Billy score:70->Billy's detail infmation
name:David score:85->David's detail infmation
name:Kite score:92->Kite's detail infmation
tailMap end
可以看到,TreeMap 提供了简明的接口对有序的 key 集合进行筛选,其结果集也是一个有序的 Map。同时,TreeMap 在最坏的情况下也可以在 O(log n) 时间内做查找、插入和删除。因此,就一个实现了排序功能的 Map 而言,TreeMap 是十分高效的。