Stata新命令:psestimate - 倾向得分匹配中协变量的筛选
作者:丁海 (华中科技大学)
Stata 连享会: 知乎 | 简书 | 码云 | CSDN
Stata连享会 精品专题 || 精彩推文

2019暑期“实证研究方法与经典论文”专题班-连玉君-江艇主讲

倾向得分匹配分析 (PSM) 已经在诸多领域得到了应用。虽然 PSM 不能完全解决内生性问题,但却能在很大程度上缓解自我选择问题导致的偏差。在前期文献中,Becker & Ichino (2002, Stata Journal, 2(4):358-377) 对 PSM 的分析过程进行了详细的介绍,Stata 中也有多个命令可以执行 PSM 分析,如 pscore, psmatch2, treatrew (Stata Journal, 14(3): 541-561), gpscore (SJ 8(3):354–373), kmatch
net describe st0328, from(http://www.stata-journal.com/software/sj14-1)
平衡性假设
在 PSM 匹配时,用treat变量对控制变量进行Logit回归,得到倾向得分值。倾向得分值最接近的控制组个体即为实验组的配对样本,通过这种方法可以最大程度减少实验组与控制组个体存在的系统性差异,从而减少估计偏误。在进行PSM匹配后的其他估计前比如PSM-DID 估计前,还需进行协变量的平衡性假设检验,即匹配后各变量在实验组和控制组之间是否变得平衡,也就是说实验组和控制组协变量的均值在匹配后是否具有显著差异。如果不存在显著差异,则支持进一步的模型估计。
在平衡性检验之前,我们先使用psmatch2命令进行PSM匹配,处理变量为train,协变量为age、educ、black,结果变量为re78,采用一对一近邻匹配,具体操作如下:
use ldw_exper.dta,clear
psmatch2 train age educ black, out(re78) logit ate neighbor(1) common caliper(.05) ties
PSM 匹配完成之后,我们需要检验匹配后的样本是否满足平衡性假设,即实验组与控制组的匹配协变量是否没有显著性差异,在这里可以使用pstest命令进行检验,具体如下:
pstest age educ black hisp married , t(train)
平衡性假设检验结果如下:
------------------------------------------------------------------------------
| Mean | t-test | V(T)/
Variable | Treated Control %bias | t p>|t| | V(C)
------------------------+--------------------------+---------------+----------
age | 25.527 24.714 11.4 | 1.19 0.234 | 1.24
educ | 10.291 10.401 -6.0 | -0.59 0.557 | 1.60*
black | .84066 .87363 -8.9 | -0.90 0.370 | .
hisp | .06044 .09066 -10.9 | -1.09 0.277 | .
married | .18681 .1522 9.2 | 0.88 0.380 | .
------------------------------------------------------------------------------
根据t检验结果发现,以上5个协变量在实验组与控制组之间不存在显著性差异。
那么,在进行 PSM 分析之前,应当如何选择匹配协变量,使模型实现最佳的拟合效果呢?今天介绍的 psestimate 命令可以通过比较不同模型的极大似然值,帮助我们选择能实现最佳拟合效果的协变量的一阶和二阶形式。
The psestimate command estimates the propensity score proposed by Imbens and Rubin (2015). The main purpose of the program is to select a linear or quadratic function of covariates to include in the estimation function of the propensity score.
1. 命令的安装与示例数据导入
在Stata命令窗口执行第一行代码即可完成对 psestimate 命令的下载,然后输入第二行命令下载网上示例数据 nswre74.dta(LaLonde, 1986),并执行第三行命令导入数据。
ssc install psestimate, replace //安装命令
net get psestimate //下载命令附带的数据到当前工作路径下
use "psestimate.dta", replace
2. 命令的语法
该命令的语法如下:
psestimate depvar [indepvars] [if] [in] [, options]
options:
totry(indepvars)
notry(varlist)
nolin
noquad
clinear(real)
cquadratic(real)
iterate(#)
genpscore(newvar)
genlor(newvar)
各个主要选项的含义如下:
depvar,必选项,填入处理变量(如 treat),即标记是否参与实验的虚拟变量indepvars,可选项,指定基准模型中的协变量totry(indepvars),可选项,放入供选择的协变量列表,默认为全部notry(varlist),可选项,指定不包括的协变量列表,默认为没有nolin,可选项,指定不进行一阶多项式的选择noquad,可选项,指定不进行二阶多项式的选择clinear(real),可选项,指定一阶协变量似然比检验的门槛值,默认值为 1cquadratic(real),可选项,指定二阶协变量似然比检验的门槛值,默认值是 2.71iterate(#),可选项,指定在每个 logit 中执行循环的最大值,默认值是 16000genpscore(newvar),可选项,由于指定程序自动生成的用于记录倾向得分值的新变量的名称genlor(newvar),可选项,生成对数似然比的新变量的名称
3. 命令操作
3.1 命令基本操作
下面本文将基于 psestimate 命令的作者提供的数据集 nswre74.dta 来简要说明如何使用 psestimate 这一命令来选择能最好拟合处理变量 (treat) 的协变量的一阶及二阶形式。
在这里,我们事先选定教育变量 ed 作为基准模型中的一个协变量,意味着 Stata 自动将 ed 放入基准模型中。另外,我们将指定 age、black、hisp、nodeg 四个变量作为待选协变量。代码如下:
use "nswre74.dta", clear
psestimate treat ed, totry(age black hisp nodeg)
运行结果如下:
Selecting first order covariates... (10)
----+--- 1 ---+--- 2 ---+--- 3 ---+--- 4 ---+--- 5
...s..s..
Selected first order covariates are: nodeg hisp
Selecting second order covariates... (21)
----+--- 1 ---+--- 2 ---+--- 3 ---+--- 4 ---+--- 5
.....s.....
Selected second order covariates are: c.nodeg#c.ed
Final model is: ed nodeg hisp c.nodeg#c.ed
根据以上结果,可以确定在倾向得分匹配中,我们应该选取的一阶协变量为 nodeg、hisp,二阶协变量为 c.nodeg#c.ed。综上,根据 psestimate 命令的运算结果,我们应该选取 ed、nodeg、hisp、c.nodeg#c.ed 等四个变量作为倾向得分匹配的协变量。
3.2 提升运算速度
psestimate命令在运算中会耗费较长时间,而通常来说,该命令在选择协变量的一阶形式时要快于二阶形式的选择,因此,为了加快运算速度,我们可以首先通过加入noquad选项,只对协变量的一阶形式进行筛选,当一阶形式选定后,将其作为解释变量放入基准模型中,然后加入nolin 选项跳过一阶形式筛选步骤,只对协变量的二阶形式进行筛选。具体操作如下。
首先,加入入noquad选项,只筛选协变量的一阶形式,如下:
use "nswre74.dta", clear
psestimate treat ed, totry(age black hisp nodeg) noquad
一阶协变量的筛选结果如下:
Selecting first order covariates... (10)
----+--- 1 ---+--- 2 ---+--- 3 ---+--- 4 ---+--- 5
...s..s..
Selected first order covariates are: nodeg hisp
Final model is: ed nodeg hisp
然后,将选定的ed、nodeg、hisp作为解释变量放入基准模型中,加入nolin选项值进行二阶形式的筛选,操作如下:。
psestimate treat ed nodeg hisp , totry(age black hisp nodeg) nolin
二阶协变量的筛选结果如下:
Selecting second order covariates... (21)
----+--- 1 ---+--- 2 ---+--- 3 ---+--- 4 ---+--- 5
.....s.....
Selected second order covariates are: c.nodeg#c.ed
Final model is: ed nodeg hisp c.nodeg#c.ed
4. psestimate 的核心思想
4.1 协变量一阶形式的选择
第一步,该程序首先在基准模型(logit treat ed)基础上通过循环分别加入 totry() 中指定的四个变量 age、black、hisp、nodeg,进行四次模型估计,如下所示:
logit treat ed age
logit treat ed black
logit treat ed hisp
logit treat ed nodeg
每次估计完成后,它将得到的新的极大似然值与基准模型比较,选择上述四个模型中对数极大似然值 (Log-Likelihood, 简称 LL 值) 最大的模型中的协变量放入基准模型中,除非上述四个模型的极大似然值都低于 clinear(real) 中指定的门槛值。若此处假设为 nodeg,则基准模型扩展为 logit treat ed nodeg, 然后第二步,它将估计如下模型:
logit treat ed nodeg age
logit treat ed nodeg black
logit treat ed nodeg hisp
这一步的协变量筛选原则与第一步相同。可以看出,当供选择的协变量数量为 C C C 时,在确定协变量的一阶形式时,该程序理论上会估计 ∑ C ∑C ∑C 个 Logit 模型。本例中有 4 个供选择的协变量,则需要估计 10 次(如下括号中所示),该命令选择的协变量一阶形式结果如下:
Selecting first order covariates... (10)
----+--- 1 ---+--- 2 ---+--- 3 ---+--- 4 ---+--- 5
...s..s..
Selected first order covariates are: nodeg hisp
4.2 协变量二阶形式的选择
在协变量二阶形式的选择上,主要分为协变量平方项以及协变量间的交乘项。
如果在一阶形式中只选择了 a 这一个协变量,则二阶形式的选择只需要检验 a^2 这一变量。但是如果有 a、b 两个一阶协变量被选择,则二阶形式的选择需要检验 a2**、**b2、ab 三个二阶协变量形式。具体到本例,确定的一阶协变量有 ed、nodeg、hisp 三个,则需要检验的二阶协变量有六个,即 ed2**、**nodeg2、hisp^2、c.ed#c.nodeg、c.ed#c.hisp、c.nodeg#c.hisp,筛选过程与选择协变量一阶形式的方法一致。因此本例中共需估计 ∑ 6 ∑6 ∑6 即 21 次(如下括号中所示),结果如下所示:
Selecting second order covariates... (21)
----+--- 1 ---+--- 2 ---+--- 3 ---+--- 4 ---+--- 5
.....s.....
Selected second order covariates are: c.nodeg#c.ed
Final model is: ed nodeg hisp c.nodeg#c.ed
4.3 流程图展示
如下流程图可以更加直观地展现psestimate筛选协变量一阶及二阶形式的过程,为简化分析,我们可供选择的协变量为a、b两个变量,假设各模型的对数极大似然值存在如下大小关系,LL1>LL2> clinear() >LL3,LL4>LL5>LL6> cquadratic() >LL7>LL8。
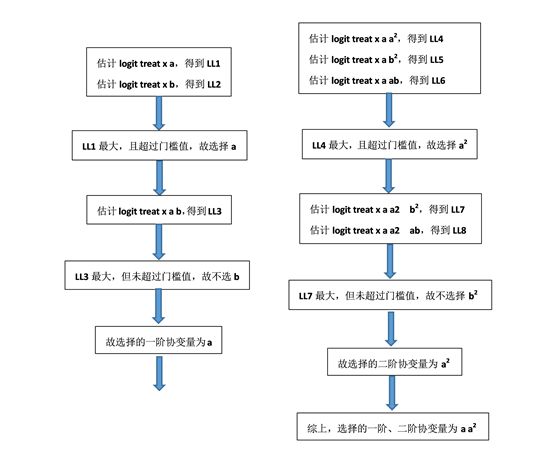
5. PSM估计的完整流程示例
5.1 psestimate 筛选匹配变量的一阶、二阶形式
第一步,使用psestimate筛选匹配变量
use "nswre74.dta", clear
psestimate treat ed, totry(age black hisp nodeg)
匹配变量选择如下:
Selecting first order covariates... (10)
----+--- 1 ---+--- 2 ---+--- 3 ---+--- 4 ---+--- 5
...s..s..
Selected first order covariates are: nodeg hisp
Selecting second order covariates... (21)
----+--- 1 ---+--- 2 ---+--- 3 ---+--- 4 ---+--- 5
.....s.....
Selected second order covariates are: c.nodeg#c.ed
Final model is: ed nodeg hisp c.nodeg#c.ed
最终选择的匹配变量为ed、nodeg、hisp、c.nodeg#c.ed
5.2 psmatch2 基于筛选出的匹配变量进行PSM匹配
基于上述匹配变量进行PSM匹配:
psmatch2 treat ed nodeg hisp c.nodeg#c.ed, logit ate neighbor(1) common caliper(.05) ties
结果如下:
Logistic regression Number of obs = 445
LR chi2(4) = 17.03
Prob > chi2 = 0.0019
Log likelihood = -293.58317 Pseudo R2 = 0.0282
------------------------------------------------------------------------------
treat | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
ed | .5093428 .3298117 1.54 0.123 -.1370762 1.155762
nodeg | 6.506319 4.112404 1.58 0.114 -1.553845 14.56648
hisp | -.5954105 .3754841 -1.59 0.113 -1.331346 .1405248
|
c.nodeg#c.ed | -.6068825 .3375387 -1.80 0.072 -1.268446 .0546813
|
_cons | -6.021438 4.05441 -1.49 0.138 -13.96794 1.925059
------------------------------------------------------------------------------
5.3 pstest 进行平衡性假设检验
pstest ed nodeg hisp c.nodeg#c.ed, t(treat)
结果如下:
------------------------------------------------------------------------------
| Mean | t-test | V(T)/
Variable | Treated Control %bias | t p>|t| | V(C)
------------------------+--------------------------+---------------+----------
ed | 10.29 10.464 -9.6 | -0.91 0.363 | 1.28
nodeg | .71585 .69399 5.3 | 0.46 0.648 | .
hisp | .06011 .06011 -0.0 | -0.00 1.000 | .
c.nodeg#c.ed | 6.7814 6.694 2.1 | 0.18 0.854 | 0.96
------------------------------------------------------------------------------
可以发现,匹配后实验组与控制组的匹配变量均没有显著差异,满足平衡性假设条件
5.4 psgraph 绘图直观呈现各匹配变量的平衡性状况
psgraph
结果如下:

图中也可以直观看出,实验组与控制组的倾向得分值分布大致平衡。
参考文献
- Dehejia, Rajeev H. and Sadek Wahba. 1999. “Causal Effects in Nonexperimental Studies”. Journal of the American Statistical Association 94(448): 1053-1062.
- Imbens, Guido W. and Donald B. Rubin. 2015. Causal Inference in Statistics, Social, and Biomedical Sciences. New York: Cambridge University Press.
- Imbens, Guido W. 2015. “Matching Methods in Practice: Three Examples.” Journal of Human Resources 50 (2): 373–419. [PDF1], [PDF2-wp]
- LaLonde, Robert J. 1986. “Evaluating the Econometric Evaluations of Training Programs with Experimental Data.” The American Economic Review 76 (4): 604–20. [PDF]
关于我们
- 【Stata 连享会(公众号:StataChina)】由中山大学连玉君老师团队创办,旨在定期与大家分享 Stata 应用的各种经验和技巧。
- 公众号推文同步发布于 CSDN-Stata连享会 、简书-Stata连享会 和 知乎-连玉君Stata专栏。可以在上述网站中搜索关键词
Stata或Stata连享会后关注我们。 - 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- Stata连享会 精品专题 || 精彩推文
联系我们
- 欢迎赐稿: 欢迎将您的文章或笔记投稿至
Stata连享会(公众号: StataChina),我们会保留您的署名;录用稿件达五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。 - 意见和资料: 欢迎您的宝贵意见,您也可以来信索取推文中提及的程序和数据。
- 招募英才: 欢迎加入我们的团队,一起学习 Stata。合作编辑或撰写稿件五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。
- 联系邮件: [email protected]
往期精彩推文
- Stata连享会 精品专题 || 精彩推文
