Jupyter 进阶教程
2019 年第 65 篇文章,总第 89 篇文章
本文大约 7500 字,建议收藏阅读
原题 | Tutorial: Advanced Jupyter Notebooks
作者 | Benjamin Pryke
译者 | kbsc13("算法猿的成长"公众号作者)
原文 | https://www.dataquest.io/blog/advanced-jupyter-notebooks-tutorial/
声明 | 翻译是出于交流学习的目的,欢迎转载,但请保留本文出于,请勿用作商业或者非法用途
前言
上次介绍了Jupyter 入门教程,这次介绍更多 Jupyter notebook 的使用技巧。
本文主要介绍以下内容:
介绍一些基本的
shell命令和方便的魔法命令,包括 debug,计时以及执行多种语言;探索如
logging、macros、运行外部代码以及 Jupyter 的拓展插件;介绍如何加强
Seaborn模块的图表,通过命令行运行,以及使用数据库。
Shell 命令
在 notebook 中可以直接采用 shell 命令,只需要在 code cell 中,以 ! 开头的都会被当做一个 shell 命令,这在处理数据或者文件,管理 Python 包的时候非常有用。以下是一个简单的示例:
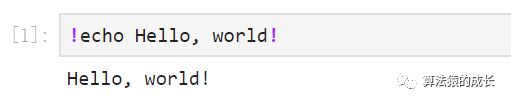
此外,也可以通过添加 $ 命令在 shell 命令中加入 Python 的变量,如下所示:
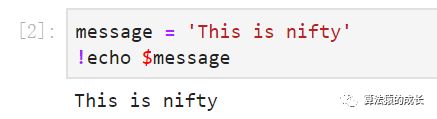
由于 ! 开头的命令在执行完成后就会被丢弃,因此像 cd 这样的命令是没有效果的。不过,IPython 的魔法命令提供了一个解决方法。
基本的魔法命令
魔法命令是内建于 IPython 核中的非常方便有用的命令,它们专门用于处理特定的任务。它们虽然看起来类似 unix 命令,但实际都是通过 Python 实现的。魔法命令非常多,但在本文中仅介绍其中一部分魔法命令。
魔法命令也分两种:
行魔法命令(line magics)
单元魔法命令(cell magics)
从名字就可以知道,主要是根据其作用范围划分,有的在单行内执行,有的可以作用多行或者整个单元内。
想了解可用的魔法命令,可以输入命令 %lsmagic ,输出结果如下所示,可以看到确实分为 line 和 cell 两类,并且分别给出命令的数量。

如果想具体了解这些命令的作用,可以上官网查看--https://ipython.readthedocs.io/en/stable/interactive/magics.html。
行魔法命令和单元魔法命令的使用形式也是不同的,行魔法命令是以 % 开头,而单元魔法命令则是 %% 开头。
实际上 ! 开头是用于 shell 命令的一种比较复杂的魔法语法,之前说的无法采用类似 cd 的命令,可以采用魔法命令实现,即 %cd、%alias、%env 。
下面介绍更多的例子。
自动保存(Autosaving)
首先是 %autosave 命令可以决定 notebook 自动保存的时间间隔,使用例子如下所示,命令后添加时间间隔参数,单位是秒。
%autosave 60
输出结果:
Autosaving every 60 seconds
显示 Matplotlib 的图表
在数据科学中最常用的一个行魔法命令就是 %matplotlib ,它可以用于显示 matplotlib 的图表,使用例子如下:
%matplotlib inline
加上参数 inline 可以确保在一个单元内显示 Matplotlib 的图表。通常需要在导入 Matplotlib 前就采用这个行魔法命令,通常都会放在第一个代码单元内。
代码执行时间(Timing Execution)
通常我们都需要考虑代码的执行时间,在 notebook 中可以有两个时间魔法命令 %time 和 %timeit,它们都有行和单元两种模式
对于 %time ,使用例子如下所示:

%timeit 和 %time 的区别在于,它会对给定代码运行多次,并计算一个平均时间,可以通过添加参数 -n 来指定运行的次数,如果没有指定,则会自动选择一个最佳的数量。例子如下所示:

执行不同编程语言
在 Jupyter notebook 中可以执行不同的编程语言,尽管选择的核有既定的语言,比如本文例子选择的就是 Python3 ,但通过魔法命令可以执行不同的编程语言,在 %lsmagic 的输出结果也可以找到。
下面是一些使用的例子,包括执行 HTML 语言,以及用于显示数学公式的 LaTeX 语言。

当然还可以执行其他编程语言,包括 Ruby 、markdown 、JavaScript、R 等等。
配置日志(Configuring Logging)
在 Jupyter 中有自定义了如何输出错误信息的方法,它可以通过导入 logging 模块实现。
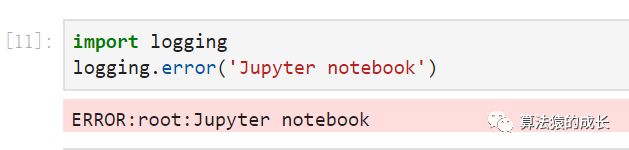
如上图所示,对于错误信息,会高亮显示。
另外,logging 模块的输出和 print 以及标准的单元输出是分开的,如下图所示:
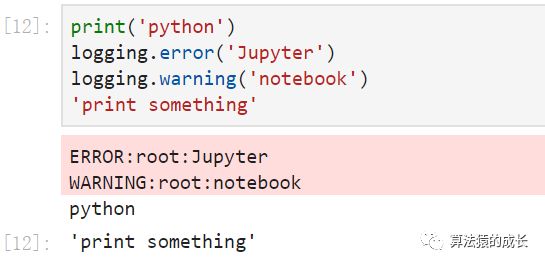
之所以会出现上图的原因是 Jupyter notebook 会监听标准的输出流,stdout 和 stderr ,但 print 和单元输出默认是输出 stdout ,而 logging 则是通过 stderr 输出。
因此,我们可以对 logging 进行配置来显示 stderr 的其他类型的信息,比如下图就显示了 INFO 和 DEBUG 类型的信息。
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
logging.info('This is some information')
logging.debug('This is a debug message')

还可以自定义信息的输出格式:
handler = logging.StreamHandler()
handler.setLevel(logging.DEBUG)
formater = logging.Formatter('%(levelname)s: %(message)s')
handler.setFormatter(formater)
logger.handlers = [handler]
logging.error('An error')
logging.warning('An warning')
logging.info('An info')
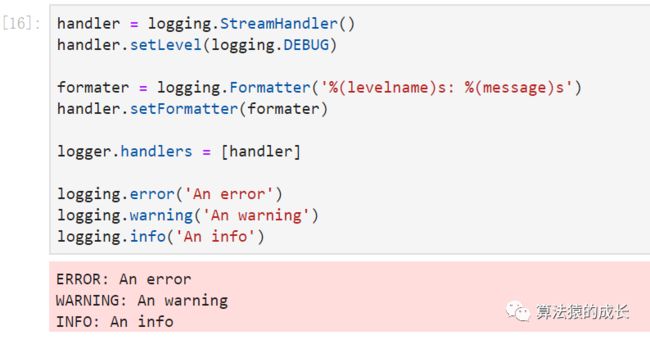
注意,如果每次运行一个单元内包含代码 logger.addHandler(handler) 来添加一个新的 stream handler ,那么每次输出都会多一行额外的信息。我们可以将对日志的配置放在单独的一个单元内,或者就如同上述所示代码,即直接代替所有现在的 handler ,不采用 addHandler ,而是 logger.handlers = [handler]。这种做法可以移除默认的 handler 。
当然也可以将日志信息保存到文件中,代码如下所示,采用 FileHandler 而非 StreamHandler 。
handler = logging.FileHandler(filename='important_log.log', mode='a')
最后,这里采用的日志跟通过 %config Application.log_level='INFO' 设置的日志等级是不相同的,通过 %config 配置的是 Jupyter 输出到当前运行 Jupyter 的终端上的日志信息。
拓展
Jupyter 是一个开源的工具,因此有很多开发者开发了很多拓展插件,具体可以查看:
https://github.com/ipython/ipython/wiki/Extensions-Index
在后面介绍的使用数据库,就采用了插件 ipython-sql,还有就是包含了拼写检查、代码折叠等等功能的一个拓展插件 Github:
https://github.com/ipython-contrib/jupyter_contrib_nbextensions
安装这些插件可以通过下面的命令
pip install ipython-sql
pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
jupyter nbextension enable spellchecker/main
jupyter nbextension enable codefolding/main
加强 Seaborn 的图表
Jupyter notebook 的最常见的一种应用就是用于绘制图表。但 Python 的最常见绘图库 Matplotlib 在 Jupyter 中并未能给出很吸引人的结果,这可以通过 Seaborn 进行美化并添加一些额外的功能。
如果没有安装 seaborn,可以通过命令 pip install seaborn ,或者在 jupyter 中,根据开始介绍的 shell 命令执行方式--!pip install seaborn ,安装完后,就可以先导入必须的库和数据:
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
data = sns.load_dataset("tips")
通过 seaborn 提供的简单的数据集,这里采用的 tips 是一个 pandas 的 DataFrame 格式数据集,内容是来自一个酒吧或者饭店的账单信息。
通过 data.head() 可以展示前 5 条数据,并查看属性信息。
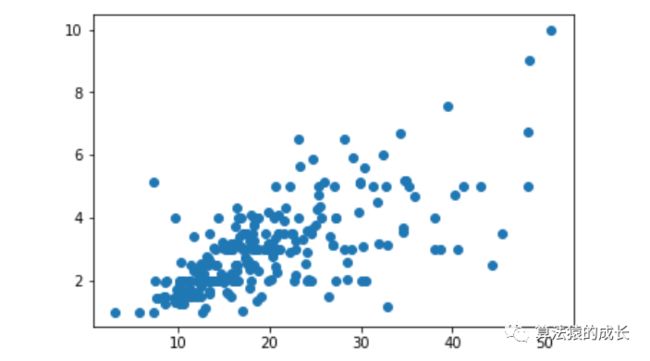
采用 Matplotlib 绘制 total_bill 和 tip 的关系图:
plt.scatter(data.total_bill, data.tip);
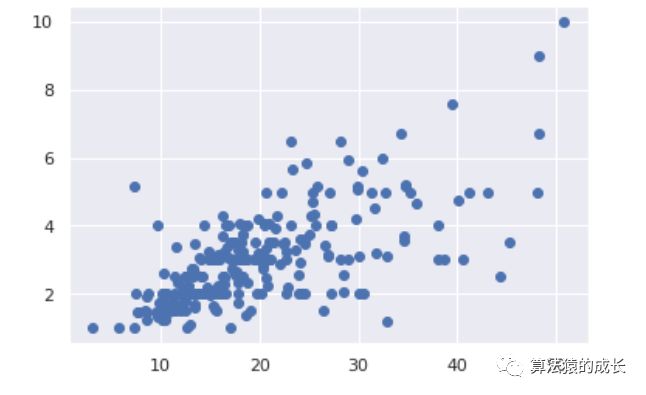
添加 Seaborn 也是很简单,如下所示,通过 seaborn 设置了一个 darkgrid的样式
sns.set()
plt.scatter(data.total_bill, data.tip);
seaborn 总共有 5 种样式:darkgrid, whitegrid, dark, white, and ticks。
实际上我们也可以单独采用 seaborn 的绘图函数,如下所示:
sns.scatterplot(x="total_bill", y="tip", data=data);
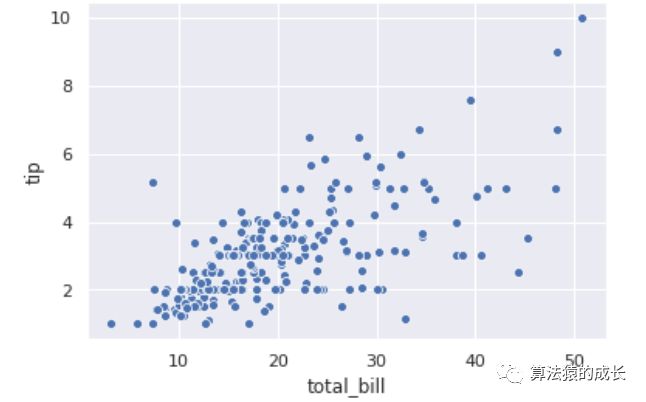
上图可以添加每个坐标的标题信息以及对每个数据点有一个提升的标记。Seaborn还可以自动根据数据的类型进行划分,即可以再添加一个维度,这里我们可以再添加属性 smoker 作为参数 hue ,表示数据点的颜色:
sns.scatterplot(x="total_bill", y="tip", hue="smoker", data=data);
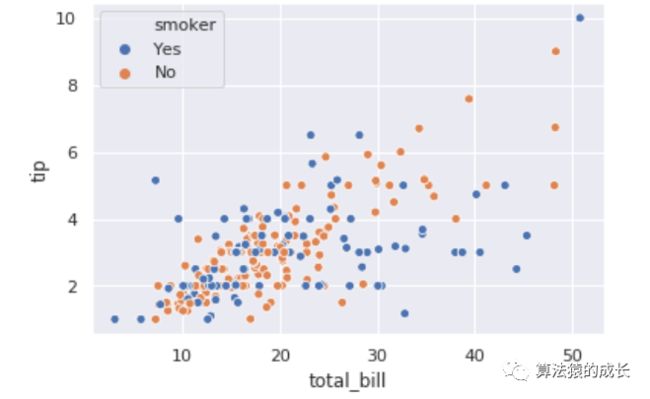
添加 smoker 后,我们可以看到每个数据点都根据是否划分为两种颜色的数据点,展示的信息就更加丰富了。我们再进一步,加入属性 size 作为颜色的划分,而 smoker 作为样式,如下所示:
sns.scatterplot(x="total_bill", y="tip", hue="size", , data=data);
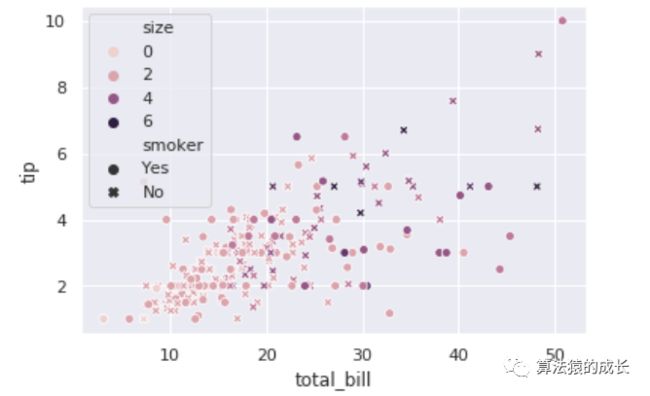
seaborn 可以绘制更多更好看的图表,更多的例子可以查看其官网:
https://seaborn.pydata.org/examples/index.html
宏命令(Macros)
很多时候,我们可能会重复做相同的任务,比如每次创建一个新的 notebook,都需要导入相同的一堆第三方库,对每个数据集都进行的统计方法,或者绘制相同类型的图表。
在 Jupyter 里可以将一些代码片段保存为可执行的宏命令,并且能用在所有的 notebooks 里。这种操作可能对其他阅读使用你的 notebook 的人来说并不是很友好的方式,但对你来说,确实会是非常方便以及减轻工作量的方法。
宏命令也是代码,因此也可以包含变量。下面开始介绍示例
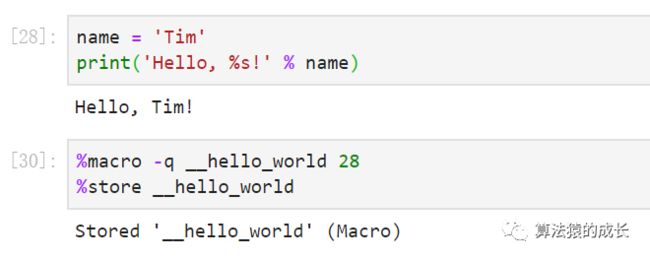
首先是写好一个代码单元,主要作用就是输出 Hello, name!,其中 name 也是定义好的一个变量,然后利用命令 %macro 来保存宏命令,名字是 __hello_world,而 28 表示的就是上一个运行顺序为 28 的代码单元,即 In [28] 对应的代码单元,然后 %store 是保存宏命令。
载入宏命令的操作如下,还是采用命令 %store ,但需要加上参数 -r ,以及宏命令的名字。
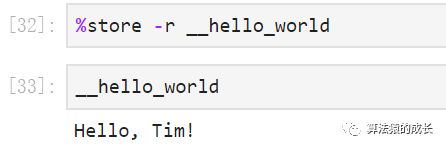
如果修改在宏命令中采用的变量,其输出结果也会改变:
name = 'Ben'
__hello_world
输出结果:
Hello, Ben!
宏命令还可以实现更多的操作,具体还是可以查看官网。
执行外部代码
在 Jupyter 还可以加载和运行外部代码,也就是 .py 代码文件。这里需要采用的命令分别是 %load 和 %run。
我们先创建一个新的代码文件--imports.py ,其包含内容如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
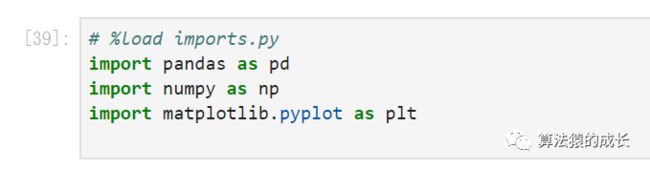
然后在 jupyter 中加载该代码文件:
%load imports.py
运行结果如下:
接着我们创建一个新的代码文件--triangle_hist.py ,代码如下,绘制一个三角形直方图。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
if __name__ == '__main__':
h = plt.hist(np.random.triangular(0, 5, 9, 1000), bins=100, linewidth=0)
plt.show()
然后调用命令 %run 运行:

此外,还可以传递参数给脚本,只需要在代码文件名后添加即可,比如 %run my_file.py 0 "Hello, World!",或者是传递变量名,如 %run $filename {arg0} {arg1} ,还可以添加 -p 来通过 Python 的分析器运行代码,具体可以参考下面两个 stackoverflow 上的回答:
https://stackoverflow.com/a/14411126/604687
https://stackoverflow.com/questions/582336/how-can-you-profile-a-python-script/582337#582337
脚本运行
Jupyter notebook 最强大的作用是其交互式的流程,但它也可以在非交互式的模式下运行,即可以通过脚本或者命令行形式运行 jupyter notebook。
命令行的基本语法如下:
jupyter nbconvert --to <format> notebook.ipynb
其中 nbconvert 是用于将 notebook 转换为其他形式的一个 API 接口,比如 PDF、HTML、python 脚本(即 .py 文件),甚至 LaTeX 文件。
比如,需要将 notebook 转换为 PDF 形式:
jupyter nbconvert --to pdf notebook.ipynb
这个操作将生成一个 pdf 文件--notebook.pdf ,当然如果要实现转换为 PDF ,还需要安装一些必须的库--pandoc 和 LaTeX,安装方法可以查看:
https://stackoverflow.com/a/52913424/604687
默认情况下,nbconvert 并不会执行 notebook 里的代码,但可以添加 --execute 来让其运行代码:
jupyter nbconvert --to pdf --execute notebook.ipynb
另外,还可以添加 --allow-errors 来让 nbconvert 会输出代码中的错误信息,并且不会因为出现错误而中断转换过程:
jupyter nbconvert --to pdf --execute --allow-errors notebook.ipynb
使用数据库
要在 jupyter 中使用数据库,首先需要安装 ipython-sql :
pip install ipython-sql
安装好后,首先输入以下魔法命令来加载 ipython-sql 。
%load_ext sql
接着就是连接到一个数据库:
%sql sqlite://
输出:
'Connected: @None'
这里是连接到一个临时的数据库,你也可以指定连接到你的数据库,可以按照官网(https://docs.sqlalchemy.org/en/latest/core/engines.html#database-urls)的语法进行连接:
dialect+driver://username:password@host:port/database
比如可以是类似 postgresql://scott:tiger@localhost/mydatabase,也就是 driver 就是 postgresql ,usename 是 scott ,password 是 tiger,host 是 localhost ,然后 database 是 mydatabse .
接下来就是快速采用之前用 Seaborn 加载的 tips 的数据集来构建我们的数据库:
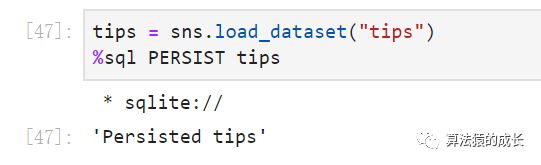
接下来就可以对数据进行一些查询的操作,如下所示,这里需要用到多行魔法命令形式 %% :
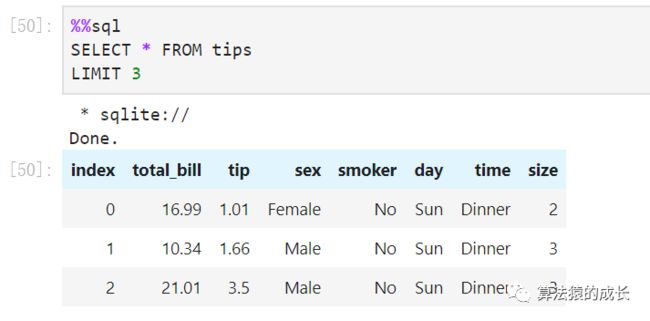
还可以进行更复杂的查询操作:
更多的例子可以查看 https://github.com/catherinedevlin/ipython-sql
小结
对比原文,其实删除了部分内容,比如脚本运行 jupyter 部分,自定义 jupyter 的样式,然后数据库部分也有所删减,主要是原文的代码总是缺失一部分内容。
本文中涉及到的网站链接:
https://github.com/catherinedevlin/ipython-sql
https://github.com/ipython-contrib/jupyter_contrib_nbextensions
https://github.com/mwaskom/seaborn-data
https://stackoverflow.com/a/14411126/604687
https://stackoverflow.com/questions/582336/how-can-you-profile-a-python-script/582337#582337
https://nbconvert.readthedocs.io/en/latest/install.html#installing-nbconvert
https://stackoverflow.com/a/52913424/604687
https://github.com/catherinedevlin/ipython-sql
最后本文的代码都上传到 Github 上了:
https://github.com/ccc013/Python_Notes/blob/master/Projects/jupyter_notebook_tutorial/jupyter_advanced_tutorial.ipynb
欢迎关注我的微信公众号--算法猿的成长,或者扫描下方的二维码,大家一起交流,学习和进步!

如果觉得不错,在看、转发就是对小编的一个支持!