聚类(Clustering) hierarchical clustering 层次聚类
假设有N个待聚类的样本,对于层次聚类来说,步骤:
1、(初始化)把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
2、寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
3、重新计算新生成的这个类与各个旧类之间的相似度;
4、重复2和3直到所有样本点都归为一类,结束
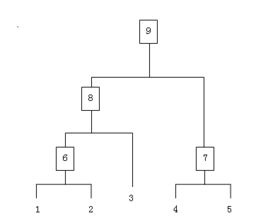
整个聚类过程其实是建立了一棵树,在建立的过程中,可以通过在第二步上设置一个阈值,当最近的两个类的距离大于这个阈值,则认为迭代可以终止。另外关键的一步就是第三步,如何判断两个类之间的相似度有不少种方法。这里介绍一下三种:
SingleLinkage:又叫做 nearest-neighbor ,就是取两个类中距离最近的两个样本的距离作为这两个集合的距离,也就是说,最近两个样本之间的距离越小,这两个类之间的相似度就越大。容易造成一种叫做 Chaining 的效果,两个 cluster 明明从“大局”上离得比较远,但是由于其中个别的点距离比较近就被合并了,并且这样合并之后 Chaining 效应会进一步扩大,最后会得到比较松散的 cluster 。
CompleteLinkage:这个则完全是 Single Linkage 的反面极端,取两个集合中距离最远的两个点的距离作为两个集合的距离。其效果也是刚好相反的,限制非常大,两个 cluster 即使已经很接近了,但是只要有不配合的点存在,就顽固到底,老死不相合并,也是不太好的办法。这两种相似度的定义方法的共同问题就是指考虑了某个有特点的数据,而没有考虑类内数据的整体特点。
Average-linkage:这种方法就是把两个集合中的点两两的距离全部放在一起求一个平均值,相对也能得到合适一点的结果。
average-linkage的一个变种就是取两两距离的中值,与取均值相比更加能够解除个别偏离样本对结果的干扰。
代码:
from numpy import *
"""
Code for hierarchical clustering, modified from
Programming Collective Intelligence by Toby Segaran
(O'Reilly Media 2007, page 33).
"""
class cluster_node:
def __init__(self,vec,left=None,right=None,distance=0.0,id=None,count=1):
self.left=left
self.right=right
self.vec=vec
self.id=id
self.distance=distance
self.count=count #only used for weighted average
def L2dist(v1,v2):
return sqrt(sum((v1-v2)**2))
def L1dist(v1,v2):
return sum(abs(v1-v2))
# def Chi2dist(v1,v2):
# return sqrt(sum((v1-v2)**2))
def hcluster(features,distance=L2dist):
#cluster the rows of the "features" matrix
distances={}
currentclustid=-1
# clusters are initially just the individual rows
clust=[cluster_node(array(features[i]),id=i) for i in range(len(features))]
while len(clust)>1:
lowestpair=(0,1)
closest=distance(clust[0].vec,clust[1].vec)
# loop through every pair looking for the smallest distance
for i in range(len(clust)):
for j in range(i+1,len(clust)):
# distances is the cache of distance calculations
if (clust[i].id,clust[j].id) not in distances:
distances[(clust[i].id,clust[j].id)]=distance(clust[i].vec,clust[j].vec)
d=distances[(clust[i].id,clust[j].id)]
if d=0:
# positive id means that this is a leaf
return [clust.id]
else:
# check the right and left branches
cl = []
cr = []
if clust.left!=None:
cl = get_cluster_elements(clust.left)
if clust.right!=None:
cr = get_cluster_elements(clust.right)
return cl+cr
def printclust(clust,labels=None,n=0):
# indent to make a hierarchy layout
for i in range(n): print ' ',
if clust.id<0:
# negative id means that this is branch
print '-'
else:
# positive id means that this is an endpoint
if labels==None: print clust.id
else: print labels[clust.id]
# now print the right and left branches
if clust.left!=None: printclust(clust.left,labels=labels,n=n+1)
if clust.right!=None: printclust(clust.right,labels=labels,n=n+1)
def getheight(clust):
# Is this an endpoint? Then the height is just 1
if clust.left==None and clust.right==None: return 1
# Otherwise the height is the same of the heights of
# each branch
return getheight(clust.left)+getheight(clust.right)
def getdepth(clust):
# The distance of an endpoint is 0.0
if clust.left==None and clust.right==None: return 0
# The distance of a branch is the greater of its two sides
# plus its own distance
return max(getdepth(clust.left),getdepth(clust.right))+clust.distance
【注】:本文为麦子学院机器学习课程的学习笔记