3 算法分析
“分析”二字的含义很广泛,在算法分析的领域,指的就是算法的效率,包括运行时间效率(时间复杂度)和内存空间使用效率(空间复杂度)两方面。同时,研究表明,通常时间方面比空间能取得更大的进展,因此我们进一步将分析的重点放在时间复杂度上。

3.1 算法分析 - 科学实验方法
科学家用来理解自然世界的方法对分析程序的运行时间来说同样有效:
1) 观察:观察自然世界的一些特性,并用准确的度量表示。
2) 假设:假设一个能与观察保持一致的模型。
3) 预测:用上面的假设预测事件。
4) 检验:做更多的实验并观察记录,验证预测是否准确。
5) 证明:不断重复假设和观察的过程,直到理论和现实达成一致,得到正确的模型。
要注意的三点是:
Ø 实验必须是可重复的(reproducible)
Ø 假设的模型能够证伪,即能够判断是否与观察一致(falsifiable)。
Ø我们没法确信假设一定是正确的,这就像算法正确性证明与单元测试验证的关系,我们只能证明假设与当前的观察相符合。爱因斯坦说过:“No amount of experimentation can ever prove me right; a single experiment can prove me wrong”。
3.1.1 观察
与科学家面对同样的问题是,我们也需要考虑如何观察程序?如何度量程序?这些问题已经有了标准答案:
Ø 如何观察:我们的程序都会涉及问题大小(problem size),例如输入规模或某个命令行参数。几乎所有的算法,其运行时间都会随问题大小增大而增加,因此用输入规模n作为参数的函数来分析算法时间效率是合理的。
Ø 如何度量:作为程序员是幸福的,因为我们的实验比科学家简单得多,我们不需要发射火箭到火星,或者分割一个原子。我们每运行一次程序就是执行一次实验。因此只需记录程序执行时间就可以了。
3.1.2 假设
《算法》中举了一个计算文件中相加之和为0的三元组的例子。ThreeSum就是实验的主题,而DoublingTest则是实验的脚手架,它在main()方法中反复运行ThreeSum,每次输入规模都翻倍。
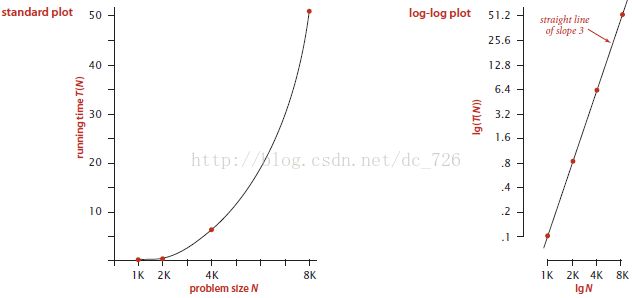
经过实验的观察和记录后,得到下面的问题大小N与运行时间T(N)的坐标图,这里为了数据分析出二者的准确关系,引入了log-log双对数坐标图。这里简单介绍一下,对于![]() ,对y取log/lg/ln,得到
,对y取log/lg/ln,得到![]() ,于是就能得到logy与logx是线性关系。反过来说呢,如果logy和logx是线性关系,那么x和y二者符合幂定律(power law),许多自然界的现象都符合这个定律:
,于是就能得到logy与logx是线性关系。反过来说呢,如果logy和logx是线性关系,那么x和y二者符合幂定律(power law),许多自然界的现象都符合这个定律:
经过推导,ThreeSum的运行时间T(N):
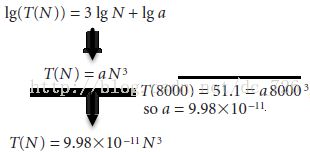
3.1.3 预测与验证
使用上面假设的模型进行预测,N=16000时,T(N)=408.8秒,实验结果为409.3秒,因此验证了我们的预测是对的。
3.2 算法分析 - 数学建模方法
3.2.1 分析框架
Knuth提出了数学建模的方法,观察步骤与传统自然科学方法相同,都是使用输入规模,但在模型假设和运行时间度量上提出了更简单的方法。他的想法很简单,总的运行时间由两个因素决定:
Ø 执行每条指令的代价:计算机、编译器、操作系统的属性。我们一般会假定一个理想模型,拥有无限的内存,以及加减乘除等标准指令,指令顺序执行,每条指令耗时相同。
Ø 每条指令的执行频率:程序本身和输入的属性。(重点!)
这样,我们的分析框架的主要构成如下:
Ø 输入规模(input size):因为通过观察我们发现,对于越大的输入规模算法执行时间越长,因此以算法输入规模的函数来度量时间与空间效率是合理的。例如对于排序、查找,输入规模就是表大小;对于矩阵乘法就是矩阵大小或秩。输入规模的选取是会受算法做何种操作影响的,例如一个拼写检查程序,若程序检测单个字符,那么输入规模就该用字符度量,若检测整个单词则就该用词的个数来度量。而对于质数检查程序,我们应该用输入数字的位数来度量。
Ø 度量单位(measure unit):用基本操作(basic operation or
![]()
Ø 按情况区分(worst/average/best-case):即使是相同输入规模,算法的效率仍可能会因输入的差别而很不同,因此对于这些算法,我们要区分最坏情况、平均情况、最好情况。最坏情况定义了算法性能的增长率量级的上界,而平均情况反映算法典型或随机情况下的执行效率,那最好情况有什么用?1)对于最好情况下性能非常好的算法,可以利用这一点对输入数据进行预处理;2)分析时,如果一个算法的最好情况依然很糟,那我们直接放弃这种算法。
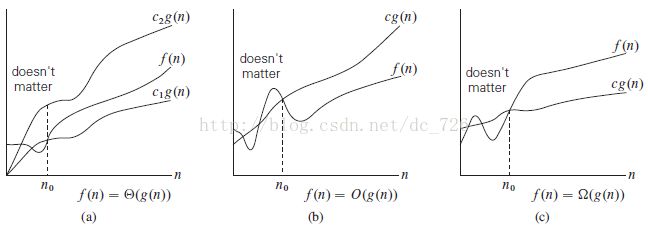
Ø 增长率的数量级(order of growth):框架着重关心随着输入规模的增长,算法运行时间增长率的数量级。当比较两个算法的增长率量级时,我们通常采用求极限的方法,公式如下:

3.2.2 通用分析步骤
在上面分析框架内,非递归程序的通用分析规则是:
1) 确定一个或多个入参作为输出规模。
2) 确定算法的基本操作。
3) 检查基本操作的执行次数是否依赖输入规模。若是,则要按三种情况分别分析。
4) 建立求和表达式,表示基本操作乘以执行次数。(递归程序:建立基本操作的递归关系和初始条件)
5) 求解求和公式,得出算法的增长率数量级。(递归程序:求解递归表达式,得出算法的增长率数量级)
3.2.3 陷阱
有许多因素可能会影响我们上面模型的准确性,例如计算增长率时忽略了很大的常数项,不是最耗时的inner loop,指令执行时间的差异,系统环境的影响等等。