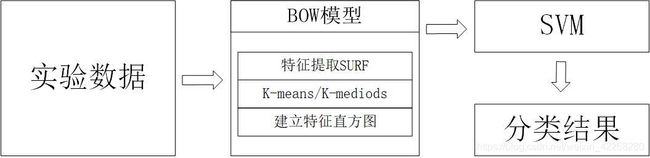
基于词袋模型(bag-of-words)的图像识别分类
基于词袋模型(bag-of-words)的图像识别分类
GitHub代码:https://github.com/doublecheckhjc/Image-classification_1
1. 词袋模型
词袋模型(bag-of-words,BOW)即将所有词语装进一个袋子里,不考虑其词法和语序的问题,即每个词语都是独立的,把每一个单词都进行统计,同时计算每个单词出现的次数。词袋中每个词语都是独立的,不考虑词法和语序的问题。这里举个例子。
文本1. I like apples,I like bananas.
文本2. I like playing games.
我们来建立一个词袋,[I,like,apples,bananas,playing,games],那么两个文本就可以表示成如下形式:
文本1. [2,2,1,1,0,0],
文本2. [1,1,0,0,1,1].

那文本1来说明,这些数字代表的是词袋中每次词在文本1中出现的次数,如I出现2次,like出现2次,apples和bananas出现1次,playing和games出现0次,这样就得到文本1的序列。文本2同样的道理,这里不再重复。
词袋模型最初是出现在了NLP和IR领域,被用于文本特征的提取,近些年,Fei-fei Li[1]提出了用BoW模型表达图像的方法,他们认为, 图像可以类比为文档(document), 图像中的单词(words)可以定义为一个图像块(image patch)的特征向量,那么图像的BoW模型即是 “图像中所有图像块的特征向量得到的直方图”。
2. BOW模型应用于图像识别分类
首先介绍一下该模型的一般步骤:
-
特征提取
类比一下上面文本特征的提取,把文本1这句话切成一个个单词,这个过程就是在提取这个文本的特征,那么在图像中提取特征也类似,就是把图像切成一个个的片(patch),每片当成该图像的特征。常用的特征提取方法有SIFT、LBP、SURF等。 -
生成字典/词袋(codebook)
在上一步特征提取中我们得到了很多的特征点,我们不能把每个点都放进词袋吧,那么就需要想一个招找到这些点中具有代表性的几类点,这一般需要聚类方法来完成的。对全部特征点进行聚类,得到了几个聚类中心,这些聚类中心就是这些点的特征向量。这一步之后就得到了词袋。(不理解的可以类比一下上面文本形成词袋的过程,上面文本形成词袋是把所有单词都放进去了,但是对图像来说特征点太多不可能全部放进去,所以使用聚类把聚类中心就当成词袋中的点)。 -
根据词袋生成特征直方图
对于每张图片都有大量的特征点,那么就把这些点对照着上面得到的词袋统计出来,这样每张图片都会得到一个特征直方图,可以参考一下上面文本直方图。
3. 实例
实验数据集来自于http://multibandtexture.recherche.usherbrooke.ca/normalized_brodatz.html,这是一组标准纹理数据集。更多实验数据集详见更多实验数据集。
在本节将要结合实际数据来介绍BOW模型的应用。
1.数据集

这里我只使用了Brodatz数据集的前五类样本,原图片是640640大小的tif格式图片,我先把每一类样本切割成6464大小的块,这样每类图片得到100张实验样本,80张作为训练样本,20张作为测试样本。为了方便后序实验,在切割保存时按照"类别-样本数"命名。如第一类第一个样本命名为"1-1.jpg"。下图是部分切割后的图片。

这里给出切片的代码:
M=10;N=10;%M、N选择
rgb=imread('H:\RGB\Normalized Brodatz\D5.tif');
[m,n,~]=size(rgb);
xb=round(m/M)*M;yb=round(n/N)*N;%找到能被整除的M,N
rgb=imresize(rgb,[xb,yb]);
[m,n,c]=size(rgb);
count =1;
for i=1:M
for j=1:N
% 1) 分块
block = rgb((i-1)*m/M+1:m/M*i,(j-1)*n/N+1:j*n/N,:); % 图像分成块
%写上要对每一块的操作
num = N*(i-1)+j;
name = ['H:\RGB\Brodatz_patch\','5-',num2str(num),'.jpg'];
imwrite(block,name);
% subplot(M,N,count);
% imshow(block);
% count = count+1;
end
end
对代码做一个解释,其中M、N是把原图切割成M*N个块,这段代码只能是运行一遍对一张大图切割,你想切割第二张大图时,记得把imread后面的文件名改一下,还有下面保存时改一下name的后面的数字,保证上下对应。这里表示的是我在切割D5这张图片,是以5-样本数命名的图像块。
2.实验方法
本实验是以BOW模型为核心的图像识别分类。
实验数据的获取及切片的代码在上一步已经得到了,这里将给出BOW模型的代码:
clear
clc
close all
%第一步:求全部图像的sitf的特征点,结果是一个M*N的矩阵,M是全部图像的全部特征点的个数,N是sitf算法得出特征的长度
all_features = [];
for u=7:1:15
for v=1:1:50
str=['H:\RGB\7-15\',num2str(u),'-',num2str(v),'.jpg'];
img = imread(str);
features = calcSiftFeature(img);
all_features = [all_features;features];
fprintf('已完成第%d类第%d个样本\n',u,v);
end
end
fprintf('已完成第一步取出全部图像的特征点\n--------接下来进行第二步构建词典------------');
%第二步:根据上一步得到的特征点的集合开始聚类,方法是K-means或K-medoids.得到词典也叫词包。P*N的矩阵,P是特征的个数,N同上
centers = learnVocabulary(all_features,64); %参数是特征点集合和聚类个数
fprintf('已完成第二步求出聚类中心\n--------接下来进行第三步计算每个图像的特征频率直方图------------');
%第三步:计算特征频率直方图也就是特征向量。一个图像会得到一行特征向量,所以特征向量是H*K,H是图像个数,K是聚类中心数。
new_featVec = [];
for u=7:1:15
for v=1:1:50
str=['H:\RGB\7-15\',num2str(u),'-',num2str(v),'.jpg'];
img = imread(str);
features = calcSiftFeature(img);
featVec = calcFeatVec(features, centers,64);
new_featVec = [new_featVec;featVec];
fprintf('已完成第%d类第%d个样本的特征向量的输入\n',u,v);
end
end
fprintf('已完成第三步求出特征向量\n--------接下来进行第四步送进SVM训练并分类------------');
上面代码是本实验的主函数,其中用到了calcSurfFeature.m,learnVocabulary.m,calcFeatVec.m,三个文件,这里不详细的给出这三个代码内容,如有需要请移步我的GitHub:全部代码。
3.分类
上一步应该得到了一组特征向量,我们就用这个特征向量去分类。这就是使用Lisvm做的多分类,划分数据、编写标签、训练模型、测试,没什么说的直接上代码:
%第四步
result = new_featVec;
%数据归一化
result= mapminmax(result,0,1);
%数据划分
train_train = [result(1:40,:);result(51:90,:);result(101:140,:);result(151:190,:);result(201:240,:);result(251:290,:);result(301:340,:);result(351:390,:);result(401:440,:)];
test_simulation = [result(41:50,:);result(91:100,:);result(141:150,:);result(191:200,:);result(241:250,:);result(291:300,:);result(341:350,:);result(391:400,:);result(441:450,:)];
%训练标签
k=1;
trainlabel=[];
for i = 1:1:9
for j=1:1:40
trainlabel = [trainlabel;k];
end
k=k+1;
end
%测试标签
k=1;
testlabel=[];
for i = 1:1:9
for j=1:1:10
testlabel = [testlabel;k];
end
k=k+1;
end
%网格搜索法搜索最佳参数
% [bestacc,bestc,bestg] = SVMcgForClass(trainlabel,train_train,-8,8,-8,8,3,1,1,4.5);
%训练并分类
model = svmtrain(trainlabel, train_train, '-c 128 -g 0.03 -t 2');%核函数
[predict_label, accuracy] = svmpredict(testlabel, test_simulation, model);
fprintf('---------------------本程序结束----------------\n');
4.实验结果及结论
这里对实验结果做了一些讨论,特征提取方法固定都是用的SURF特征提取,聚类方法使用了K-means和K-mdediods,并对不同的聚类个数进行的讨论。话不多说直接上图。

上图给出的是K-means聚类时聚类中心数分别的16、32、48、64时的分类正确率。
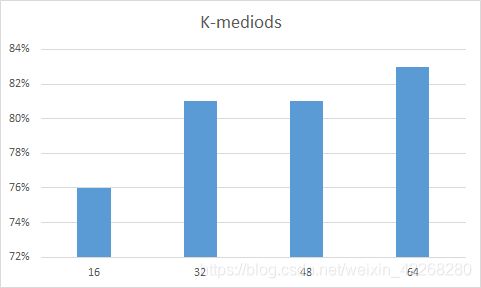
上图是K-mediods聚类时不同聚类中心数的分类正确率。

上图给了两种方法不同聚类数的总体效果。从图中可以看出K-mediods整体的正确率比较平稳,且最高正确率可达83%,K-means当聚类数少时效果不好,且差距较大。
5.展望
我觉得还可以补充一些不同特征提取方法的比较,这样更有说服力,同时也需要加大实验的数据量,本实验5类样本其实83%正确率并不高,可以改进。可能还需要补充聚类的一些图就会使实验更直观。
[1] L. Fei-Fei and P. Perona (2005). “A Bayesian Hierarchical Model for Learning Natural Scene Categories”. Proc. of IEEE Computer Vision and Pattern Recognition. pp. 524–531.