论文总结-Densely Connected Convolutional Networks
DenseNet是一种密集练级的卷积神经网络。
首先,作者在摘要中概述了DenseNet的优点:
- 缓解梯度消失问题。(这个没什么特点,这类包含短连接的网络都有这个优点)
- 增强特征传播
- 鼓励特征复用(该论文一大特点)
- 大幅减少参数
一、训练非常深的网络成为现实
虽然卷积神经网络早在20年前就被提出,但是,直到近期研究学者们才成功的训练了非常深的网络。这主要得益于网络结构的优化和计算机硬件的发展。计算机硬件的发展为其提供了足够的算力;网络结构的优化缓解了网络加深出现的梯度消失问题。

二、总结网络结构优化的方法
1)ResNet和HightWay Net使用旁路连接增强梯度的传播
2)Stochastic depth在训练过程中随机丢弃网络层来达到缩短ResNet的目的。
以上的方法有个共同的特点:都建立了短连接
三、提出DenseNet
前人在优化网络结构时,有个共同点是都建立了短连接,作者将短连接做到了极致,所有具有相同尺寸特征图的网络层都直接与其他层连接。这进一步增强了信息/梯度在整个网络中的流动。如下图所示。并且与Res的合并方式不同,使用concatenate通道合并的方式代替求和的方式。

DenseNet与ResNet和传统模型前向传播方式的对比
- 传统方法

- ResNet
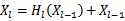
- DenseNet
 Dense Block中某层前面所有层的特征图都作为该层的输入
Dense Block中某层前面所有层的特征图都作为该层的输入
1、网络结构

主要由Dense Block和Transition layers组成。
1)Dense block:
是DenseNet的核心模块。一个Dense Block中所有特征图尺寸相同。每层与其他层都直接连接
Growth Rate:每层的卷积核个数。DenseNet的网络都非常窄,也就是卷积核的个数都很少。
Bottleneck layers:虽然每层网络的卷积核很少(输出信息很少),但是每层的输入信息非常多(因为其输入包含其前面所有层的特征图)。为降低计算量,使用1x1卷积作为bottleneck layers减少特征图的数量。然后进行3X3卷积操作。
2)Transition layers 过渡层
由于Dense block的通道合并concatrnate操作要求特征图尺寸相同,所以在Dense block中不会进行下采样的操作。但下采样是CNN中必不可少的一步,可有效减少计算量。为此每两个Dende block之间增加Transition layers。
transition laysrs包含三个部分:Batch Normalization,1x1卷积,2x2平均池化
2、DenseNet优点
1)更少的参数量
直观上,DenseNet特征图尺寸相同的层都直接连接,应该会有更多的参数量,但实际上,DenseNet的参数更少。这主要是由于DenseNet的网络层都很窄(网络卷积核很少,例如12个,正常VGG16的卷积核【64,128,256,512】,差距还是很大的)。卷积层的参数量NxHxMxc+c。c大大较少肯定会减少参数量。
那么大大减少每层输出的特征图不会影响模型的性能么?
作者给出的解释是传统的模型中,信息从输入层逐层向后传递。每层既要学习新的信息,也要传递需要保存的信息(所有需要更多的卷积核个数)。然后在将新信息和保存的信息一起传递给后层。Dense block架构清晰的区分新的信息和需要保存的信息。因为需要保存的信息Dense block会直接通过短连接传递给后层,所以每个网络层只需要学习新的信息即可。然后将新的信息加到模型的整体信息中。实际上,每层只需向整体信息总加入少量的信息即可。
传统模型结构
![]()
传统的模型是简单的线性结构,每层接受上一层的输出作为输入,做该层的非线性操作后,输出到下一层。每层都会改变信息的状态。论文中作者将每层传递的信息概述为两部分:
- 该层产生的新特征
- 需保存传递到后层的信息(该层的输入信息可能对后层有用)
DenseNet 结构

DenseNet使用密集的短连接结构。
既然网络层需要将部分输入信息保留传递到后层,那为何不直接使用短连接直接传递呢呢。DenseNet使用旁路连接将该层前所有层生成的特征图作为输入。这样使得每层只需要负责产生新的特征,不需要负责将输入向后传递,所以DenseNet的网络层都很窄(需要很少的卷积核)。每层只需要向“整体知识”中添加很少的信息。这样子清晰的区分了这两部分信息:旁路快捷连接负责传递需保留的输入信息,网络层负责学校生成新的信息。
同时、直接旁路直接传递避免了网络层去重复的学习特征。增强了网络的特征复用。
2)更容易训练
- 改变了整个网络信息和梯度流动的方式,每层都直接连接损失函数和最初的输入信息。
- DenseNet密集连接具有正则作用,可减少在较小训练集上或拟合的风险。