【推荐系统】AutoFIS: Automatic Feature Interaction Selection in FM for CTR Prediciton
AutoFIS: Automatic Feature Interaction Selection in Factorization Models for Click-Through Rate Prediction
论文地址:https://arxiv.org/abs/2003.11235
代码地址:https://github.com/zhuchenxv/AutoFIS
Abstract
- 在推荐系统中学习有效的特征交互对于CTR预估任务是十分重要的。
- 本文提出了一种两阶段的算法:Automatic Feature Interaction Selection (AutoFIS).,能够自动识别(identify) 在因子分解模型(Factorization Models)中重要的特征交互(feature interactions),而计算成本仅仅相当于将模型训练至收敛的计算成本:
- search stage: 引入结构上的参数(architecture parameters),并且使用正则化的优化器( regularized optimizer) 去学习这些参数,在这个阶段,architecture parameters的作用在于去除无效的feature interactions
- retrain stage: 根据search stage的结果,去除冗余的feature interactions, 保留architecture parameters重新训练模型,这个时候,这些architecture parameters的作用相当于注意力单元(attention units)
Methodology
1. Factorization Model
Factorization models是这样一类模型: 通过将不同特征的embedding利用诸如内积、神经网络等操作映射到一个实数上的过程对于特征的交互进行建模。
本文基于FM, DeepFM 和 IPNN 对 AutoFIS 进行探索。
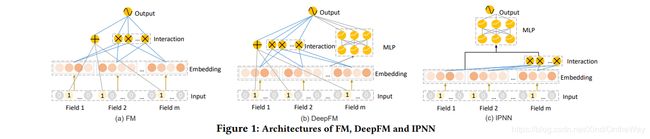
模型主要有以下几个部分组成:
-
Embedding Layer
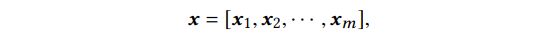

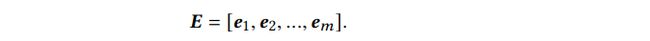
-
Feature Interaction Layer: 通过embedding内积的方式表示特征交互
- 二阶特征交互

- 三阶特征交互

- 二阶特征交互
-
MLP Layer:

-
Output Layer:
- FM
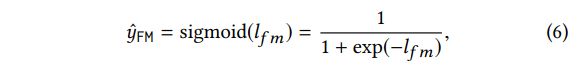
- Deep FM
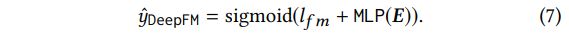
- IPNN
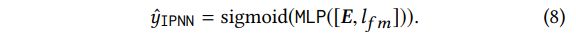
- FM
-
Objective Function
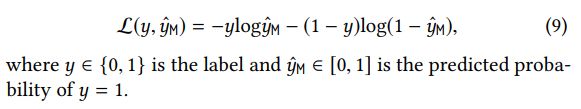
2. AutoFIS
AutoFIS旨在自动识别出有效的feature interaction, 避免无效的feature interaction引入噪声。
分为两个阶段: search stage(去检测有效的feature interactions)和 retrain-stage(去除冗余的feature interactions重新训练模型)
2.1 search stage
Architecture parameters
- 为每个feature interaction引入一个gate来控制是否选择这个feature interaction:
- gate打开表示选择这个interaction进入模型训练,关闭则在训练时丢掉这个interaction
- 对于2阶的feature interaction,会有 C m 2 C_m^2 Cm2个gate,那么就需要在 2 C m 2 2^{C_m^2} 2Cm2的空间内去进行gate的最优解搜索,这是十分困难的
- 文章并没有在一个离散的空间内去解决这个问题,而是引入了 architecture parameters α \alpha α,通过梯度下降来学习每个feature interaction的相对重要性
(instead of searching over a discrete set of open gates, we relax the choices to be continuous by introducing architecture parameters α \alpha α, so that the relative importance of each feature interaction can be learned by gradient descent.) - 具体地,Factorization Models 中的 interaction layer 如下:
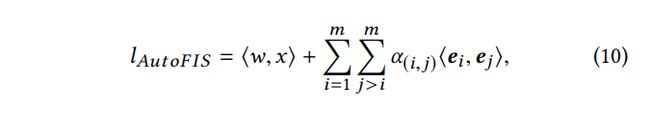
其中, α = { α ( 1 , 2 ) , ⋯ , α ( m − 1 , m ) } \alpha=\{ \alpha_{(1,2)},\cdots, \alpha_{(m-1,m)} \} α={α(1,2),⋯,α(m−1,m)}是 architecture parameters。在 search stage, α \alpha α 表示每个feature interaction对于最后预测贡献的相对大小。
Batch Normalization
-
从整个神经网络的角度看,某个feature interaction的贡献由 α ( i , j ) < e i , e j ) > \alpha_{(i,j)}
-
α ( i , j ) \alpha_{(i,j)} α(i,j)和 < e i , e j ) >
-
为了去除 < e i , e j ) >

-
在AutoFIS中,将 BN 中的 scale 和 shift 固定为1和0:

GRDA Optimizer -
Generalized regularized dual averaging (GRDA) optimizer 会学习一个稀疏的神经网络(a sparse deep neural network),在 step t t t,针对数据 Z t Z_t Zt, α \alpha α 的更新如下:

-
其中, g ( t , γ ) = c γ 1 / 2 ( t γ ) μ g(t,\gamma)=c{\gamma}^{1/2}(t\gamma)^\mu g(t,γ)=cγ1/2(tγ)μ, γ \gamma γ是 learning rate, c c c和 μ \mu μ是在accuracy 和 sparsity之间进行权衡的超参数
-
grda 的 github代码: https://github.com/donlan2710/gRDA-Optimizer
-
超参数调整建议:
- μ : 0.5 < μ < 1 \mu: 0.5<\mu <1 μ:0.5<μ<1. μ \mu μ越大,参数越稀疏。 为了获得和原始网络相当的accuracy, 对于大型的任务,比如 ImageNet, μ \mu μ 可以设置的接近于0.5,比如0.501;而对于较小的任务,比如CIFAR-10, μ \mu μ可以大一点,比如0.6;
- c : 0 < c < 0.005 c: 0
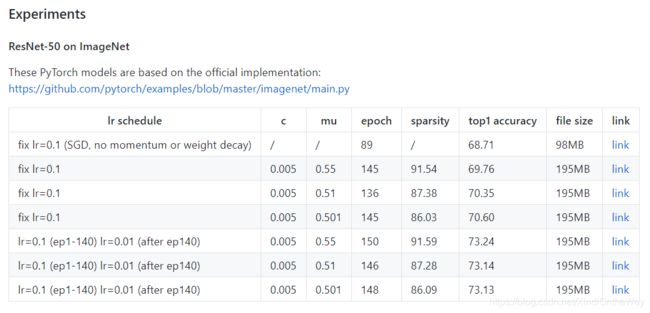
-
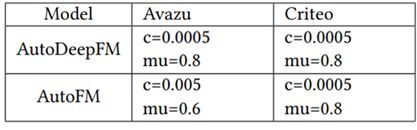
AutoFIS里的c和mu设置:
One Level Optimization -
在DARTS中, α \alpha α被视作 higher-level的决策变量,而模型的其他参数 v v v 被视作是 lower-level的变量,假设模型只有在权重被正确学习之后,才能select operation,而 α \alpha α和 v v v是迭代学习的。
-
在本文中 α \alpha α 和 v v v被视作为同一层级的参数,模型同时学习这两套参数
代码
feature interaction layer的实现:
#self.xv就是 [batch_size, feature_num, emb_size]
# 生成所有的二阶特征组合
self.cols, self.rows = generate_pairs(range(self.xv.shape[1]),mask=comb_mask)
t_embedding_matrix = tf.transpose(self.xv, perm=[1, 0, 2]) # [feature_num, batch_size, emb_size]
left = tf.transpose(tf.gather(t_embedding_matrix, self.rows), perm=[1, 0, 2]) # [batch_size, C(feature_num,2), emb_size]
right = tf.transpose(tf.gather(t_embedding_matrix, self.cols), perm=[1, 0, 2]) # [batch_size, C(feature_num,2), emb_size]
level_2_matrix = tf.reduce_sum(tf.multiply(left, right), axis=-1) # [batch_size, C(feature_num,2)]
# edge_weights 就是 architecture parameters: alpha [C(feature_num,2)]
with tf.variable_scope("edge_weight", reuse=tf.AUTO_REUSE):
self.edge_weights = tf.get_variable('weights', shape=[len(self.cols)],
initializer=tf.random_uniform_initializer(
minval=weight_base - 0.001,
maxval=weight_base + 0.001))
normed_wts = tf.identity(self.edge_weights, name="normed_wts")
tf.add_to_collection("structure", self.edge_weights)
tf.add_to_collection("edge_weights", self.edge_weights)
mask = tf.identity(normed_wts, name="unpruned_mask")
mask = tf.expand_dims(mask, axis=0) #[1, C(feature_num,2)]
level_2_matrix = tf.layers.batch_normalization(level_2_matrix, axis=-1, training=self.training,
reuse=tf.AUTO_REUSE, scale=False, center=False, name='prune_BN')
level_2_matrix *= mask
参数的更新使用不同的optimizer:
weight_var = list(set(tf.get_collection("edge_weights")))
all_variable = [v for v in tf.trainable_variables()]
other_var = [i for i in all_variable if i not in weight_var]
self.optimizer1 = optimizer1.minimize(loss=_loss_, var_list=other_var) # adam
self.optimizer2 = optimizer2.minimize(loss=_loss_, var_list=weight_var) # grda
2.2 retrain-stage
search stage之后,一些不重要的 feature interaction就被自动丢弃了。我们中 G i , j \mathcal{G}_{i,j} Gi,j 来表示 feature interaction < e i , e j >
丢掉冗余的feature interaction,重新训练模型。在这个时候, α i , j \alpha_{i,j} αi,j 不再用来作为决定 feature interaction < e i , e j >

注意,此时包括 α \alpha α在内的所有参数都是用同一个 Adam 优化器学习的:
all_variable = [v for v in tf.trainable_variables()]
self.optimizer1 = optimizer1.minimize(loss=_loss_, var_list=all_variable)
问题:
grad的超参不是很好调,而且筛选出来的特征不稳定(用不同天的训练集)