《Xception: Deep Learning with Depthwise Separable Convolutions》论文翻译
论文地址:https://arxiv.org/abs/1512.03385 这篇基本是直译,很多意思不到位,还需要改进。
深度可分卷积的深度学习
摘要
我们将卷积神经网络中的初始模块解释为常规卷积和深度可分离卷积(深度卷积后是点态卷积)之间的一个中间步骤。在这种情况下,深度可分离卷积可以被理解为具有最大数量塔的初始模块。这一发现促使我们提出了一种新的深度卷积神经网络架构,灵感来自于Inception,其中Inception模块被深度可分离的卷积所取代。我们展示了这个被称为Xception的架构,在ImageNet数据集上(Inception V3就是为这个数据集设计的)的性能略优于Inception V3,而在一个更大的图像分类数据集上(包括3.5亿幅图像和1.7万个类别)的性能则显著优于Inception V3。由于Xception架构具有与Inception V3相同数量的参数,所以性能的提高不是由于容量的增加,而是由于模型参数的更有效使用。
1.介绍
卷积神经网络近年来已成为计算机视觉领域的主要算法,开发设计卷积神经网络的方案一直是一个备受关注的课题。卷积神经网络设计的历史始于LeNet-style model[10],它是用于特征提取的简单卷积堆栈和用于空间子采样的最大池操作。2012年,这些想法被提炼到AlexNet架构[9]中,在最大池操作之间,卷积操作被重复多次,允许网络在每个空间尺度上学习更丰富的特性。随之而来的是一种趋势,使这种风格的网络越来越深入,主要是由每年的ILSVRC竞争;首先是2013年的Zeiler和Fergus,然后是2014年[18]的VGG架构。
此时,一种新型的网络出现了,即Inception架构,由Szegedy等人在2014年引入的[20]称为GoogLeNet (Inception V1),后来被改进为Inception V2 [7], Inception V3[21],以及最近的incep- resnet[19]。Inception本身受到早期网络-网络架构[11]的启发。自首次引入以来,Inception一直是ImageNet数据集[14]以及谷歌中使用的内部数据集(特别是JFT[5])上性能最好的模型系列之一。
入门风格模型的基本构建块是Inception模块,它有几个不同的版本。在图1中,我们显示了在先启模块的规范形式,正如在在先启V3架构中所发现的那样。先启模型可以被理解为这样的模块的堆栈。这与早期的vggstyle网络不同,后者是一堆简单的卷积层。

图1 规范的初始模块(Inception V3)
虽然在先启模块在概念上与卷积相似(它们是卷积的特征提取器),但从经验来看,它们似乎能够用更少的参数学习更丰富的表示。它们是如何工作的,它们与常规卷积有何不同?奠基之后会出现什么设计策略?
1.1 初始的假设
卷积层试图学习一个三维空间中的过滤器,有两个空间维度(宽度和高度)和一个通道维度;因此,单个卷积核的任务是同时映射跨通道相关性和空间相关性。
Inception模块背后的想法是通过明确地将其分解为一系列操作,独立地查看跨通道关联和空间关联,从而使这个过程更简单、更高效。更准确地说,典型的Inception模块首先着眼于跨渠道的相关性通过一组1 x1旋转,将输入数据映射到3或4单独的空间小于原始输入空间,然后地图所有这些较小的3 d空间的相关性,通过定期3 x3或5 x5的隆起。如图1所示。实际上,《盗梦空间》背后的基本假设是,交叉通道相关性和空间相关性是完全解耦的,所以最好不要共同映射它们。
考虑一个Inception模块的简化版本,它只使用一个卷积大小(例如3x3),不包括一个平均池塔(图2)。这个Inception模块可以被重新描述为一个大的1x1卷积,然后是空间卷积,它将在输出信道的非重叠段上工作(图3)。这个观察结果自然地提出了一个问题:分区中的段数(及其大小)有什么影响?是否有理由提出一个比初始假设更强的假设,并假设跨通道相关性和空间相关性可以完全分开映射?
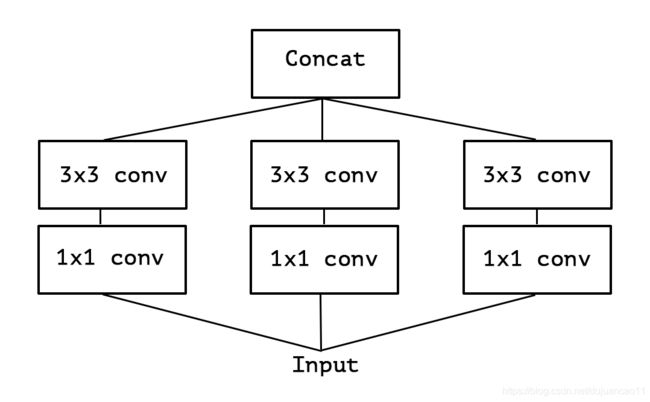
图2 简化的Inception模块。
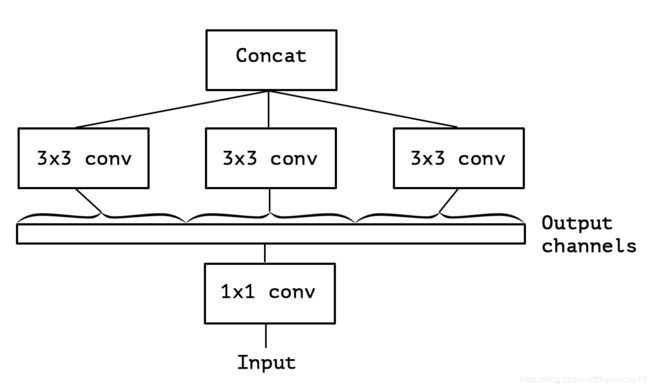
图3 一个严格等效的简化Inception模块的重新表述。
1.2 卷积与可分离卷积之间的连续体
一个“极端”版本的Inception模块,基于这个更强的假设,将首先使用1x1卷积来映射跨信道相关性,然后分别映射每个输出信道的空间相关性。如图4所示。我们注意到,初始模块的这种极端形式几乎等同于深度可分离卷积,这种操作早在2014年就已用于神经网络设计[15],自2016年被纳入TensorFlow框架[1]后,该操作变得更加流行。
深度可分离卷积,在TensorFlow和Keras等深度学习框架中通常称为“可分离卷积”,包括深度卷积,即在输入的每个通道上独立执行的空间卷积,然后是逐点卷积,即1x1卷积,将深度卷积输出的信道投影到新的信道空间。这不应与空间上可分离卷积混淆,后者在图像处理领域也通常称为“可分离卷积”。
Inception模块和深度可分离卷积的“极端”版本之间的两个小区别是:
•操作顺序:通常执行的深度可分离卷积(例如在TensorFlow中)执行第一个信道方向的空间卷积,然后执行1x1个卷积,而Inception首先执行1x1个卷积。
•首次运行后出现非线性。在Inception阶段,这两种操作都是一个相对非线性的,然而深度可分离卷积通常是在没有非线性的情况下实现的。
我们认为第一个区别并不重要,特别是因为这些操作是在堆叠的环境中使用的。第二个差异可能很重要,我们在实验部分对其进行了研究(特别是见图10)。
我们还注意到,位于规则初始模块和深度可分离卷积之间的初始模块的其他中间公式也是可能的:实际上,在规则卷积和深方向可分离卷积之间存在离散谱,参数化为所使用的独立信道空间段的数量用于执行空间卷积。在该频谱的一个极端处,规则卷积(前面是1x1卷积)对应于单段情况;深度可分离卷积对应于另一个极端,每个通道有一个段;Inception模块位于这两个极端之间,将几百个信道分成3或4个段。这种中间模的性质似乎还没有被探索。
在进行了这些观察之后,我们建议可以通过用深度可分离的卷积替换Inception模块来改进初始体系结构族,即通过构建将是纵向可分离卷积的堆栈的模型。TensorFlow中有效的深度卷积实现使其成为现实。接下来,我们提出了一种基于这种思想的卷积神经网络结构,其参数数目与Inception V3相似,并针对Inception V3在两个大规模图像分类任务中的性能进行了评估。
2前期工作
目前的工作在很大程度上依赖于以下领域的前期工作:
•卷积神经网络[10,9,25],尤其是VGG-16架构[18],它在一些方面与我们提出的架构类似。
•卷积神经网络的Inception架构家族[20,7,21,19],它首先证明了将卷积分解为多个分支的优势,这些分支依次在信道上和空间上运行。
•深度分离可分离卷积,我们提出的架构完全基于此。虽然空间可分离卷积在神经网络中的应用由来已久,至少可以追溯到2012年[12](但可能更早),而深度卷积的使用则是最近的版本。2013年,Laurent Sifre在Google Brain实习期间开发了depthwise可分离卷积,并将其用于AlexNet,在精确度上获得了小幅度的提高,在收敛速度上获得了较大的提高,同时模型尺寸也显著减小。他在2014年ICLR的一次演讲中首次公开了他的工作概况[23]。详细的实验结果在Sifre的论文第6.2节[15]中报告。这项关于深度可分离卷积的最初工作是受到Sifre和Mallat关于变换不变散射的先前研究的启发[16,15]。后来,深度可分离卷积被用作Inception V1和Inception V2的第一层[20,7]。在Google内部,Andrew Howard[6]引入了一种高效的移动模型MobileNets,它使用depthwise可分离卷积。Jin等人。2014年[8]和Wang等人。2016年[24]还做了相关工作,旨在使用可分离卷积来减小卷积神经网络的规模和计算成本。另外,我们的工作是可能的,因为在TensorFlow框架中包含了一个有效的深度可分离卷积的实现[1]。
•残余连接,由He等人介绍。在[4]中,我们提出的体系结构广泛使用。
3 Xception体系结构
我们提出了一个完全基于深度可分离卷积层的卷积神经网络结构。实际上,我们提出了以下假设:卷积神经网络的特征映射中的跨通道相关性和空间相关性映射可以完全解耦。因为这个假设是Inception架构下的假设的一个更强大的版本,我们将我们提出的架构Xception命名为“Extreme Inception”。
图5给出了网络规范的完整描述。Xception结构有36个卷积层构成网络的特征提取库。在我们的实验评估中,我们将专门研究图像分类,因此我们的卷积基础将是一个逻辑回归层。可选地,可以在logistic回归层之前插入完全连接的层,这在实验评估部分进行了探讨(特别是,见图7和图8)。36个卷积层被构造成14个模块,除第一个和最后一个模块外,所有模块周围都有线性剩余连接。
简而言之,Xception体系结构是一个具有剩余连接的深度可分离卷积层的线性堆栈。这使得架构非常容易定义和修改;使用Keras[2]或TensorFlow Slim[17]这样的高级库只需要30到40行代码,这与VGG-16[18]等架构没有什么不同,而是不像Inception V2或V3这样的架构,后者的定义要复杂得多。使用Keras和TensorFlow的Xception的开源实现作为Keras应用程序模块2的一部分,在MIT许可下提供。
4实验评价
我们选择将Xception与Inception V3架构进行比较,因为它们的规模相似:Xception和Inception V3的参数数目几乎相同(表3),因此任何性能差距都不能归因于网络容量的差异。我们对两个图像分类任务进行了比较:一个是著名的ImageNet数据集上的1000级单标签分类任务,另一个是在大规模JFT数据集上的17000级多标签分类任务。
4.1 JFT数据集
JFT是Google内部的大规模图像分类数据集,由Hinton等人首次引入。在[5]中,它包含了超过3.5亿张高分辨率图像,这些图像用来自17000个类的标签进行了注释。为了评估在JFT上训练的模型的性能,我们使用了一个辅助数据集FastEval14k。
FastEval14k是一个由14000幅图像组成的数据集,其中包含来自大约6000个类的密集注释(平均每个图像36.5个标签)。在这个数据集中,我们使用前100个预测的平均精度来评估性能(地图@100),我们衡量每个班级对地图@100用一个分数来评估这个班级在社交媒体形象中的普遍性(因此也很重要)。这个评估过程的目的是从社交媒体上获取频繁出现的标签的性能,这对谷歌的产品模型至关重要。
4.2 优化配置
ImageNet和JFT使用了不同的优化配置:
•在ImageNet上:
–优化器:SGD
–动量:0.9
–初始学习速率:0.045
–学习速率衰减:每2个周期速率衰减0.94
•在JFT上:
–Optimizer:RMSprop[22]
–动量:0.9
–初始学习率:0.001
–学习速率衰减:每3000000个样本衰减率为0.9
对于这两个数据集,Xception和Inception V3都使用了完全相同的优化配置。请注意,这个配置是为Inception V3的最佳性能而优化的;我们没有尝试为Xception优化超参数。由于网络具有不同的训练配置文件(图6),这可能是次优的,尤其是在ImageNet数据集上,使用的优化配置已经针对Inception V3进行了仔细调整。
此外,所有模型在推断时都使用Polyak平均值[13]进行评估。
4.3 正则化构形
•权重衰减:Inception V3模型使用4e−5的权重衰减(L2正则化)速率,该速率已针对ImageNet的性能进行了仔细调整。我们发现这个比率对于例外情况来说是非常不理想的,相反,我们将其定为1e−5。我们没有对最佳的重量衰减率进行广泛的搜索。JFT的净重量和衰减率都是相同的。
•Dropout::对于ImageNet实验,这两个模型在逻辑回归层之前都包括一个速率为0.5的丢失层。对于JFT实验,由于数据集大,在任何合理的时间内都不太可能出现过度拟合,因此没有数据丢失。
•辅助损失塔:Inception V3架构可选择性地包括一个辅助塔,该辅助塔在网络中较早地反向传播分类损失,作为附加的正则化机制。为了简单起见,我们选择不在任何模型中包含此辅助塔。
4.4 训练基础设施
所有的网络都是使用TensorFlow框架[1]实现的,并分别在60个NVIDIA K80 gpu上进行训练。在ImageNet实验中,我们使用数据并行性与同步梯度下降来获得最佳的分类性能,而在JFT中,我们使用异步梯度下降来加速训练。ImageNet实验每次大约花费3天时间,而JFT实验每次花费一个多月时间。JFT模型没有被训练到完全收敛,每次实验都要花上三个月的时间。
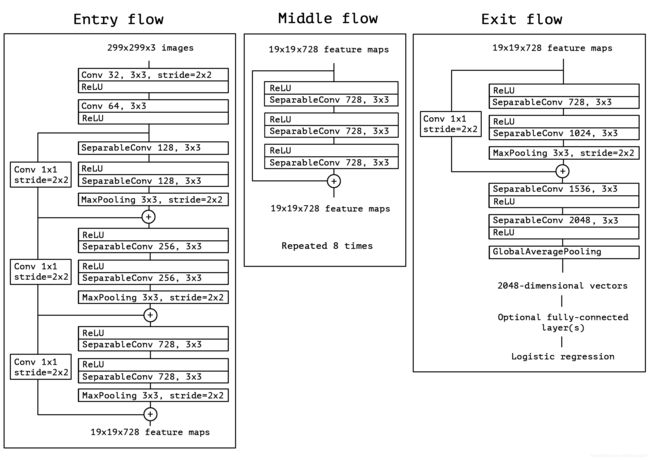
图5 Xception架构:数据首先通过入口流,然后通过重复8次的中间流,最后通过出口流。注意,所有的卷积和可分离的褶积层都跟着批处理归一化[7](不包括在图中)。所有可分离的图层都使用1的深度倍增器(没有深度扩展)。
4.5 与Inception V3的比较
4.5.1 分类性能
所有的评估都是在单一的输入图像作物和单一的模型下进行的。ImageNet的结果报告在验证集而不是测试集上(即ILSVRC 2012验证集中未被列入黑名单的图像)。JFT结果在3000万次迭代(一个月的训练)之后才会报告,而不是在完全收敛之后。结果见表1、表2,以及图6、图7、图8。在JFT上,我们测试了两种版本的网络,一种是不包含任何完全连接层的网络,另一种是包含两个完全连接层的网络,每个层在logistic回归层之前都有4096个单元。
在ImageNet上,Xception的结果比Inception V3稍微好一些。在JFT上,Xception相对FastEval14k MAP@100指标有4.3%的改进。我们还注意到,对于ResNet-50、ResNet-101和ResNet152 [4], Xception优于He等人报道的ImageNet结果。
表1。在ImageNet(单作物、单模型)上的分类性能比较。VGG-16和ResNet-152号码仅作为提醒。被基准测试的Inception V3版本不包括辅助塔。

与ImageNet数据集相比,Xception架构在JFT数据集上显示了更大的性能改进。我们认为这可能是由于Inception V3的开发重点是ImageNet,因此可能在设计上过于适合这个特定的任务。另一方面,这两种架构都没有为JFT进行优化。在ImageNet上搜索更好的超参数(特别是优化参数和再流化参数)可能会带来显著的额外改进。
表2 JFT(单作物、单模式)分类性能比较

图6 ImageNet上的培训资料
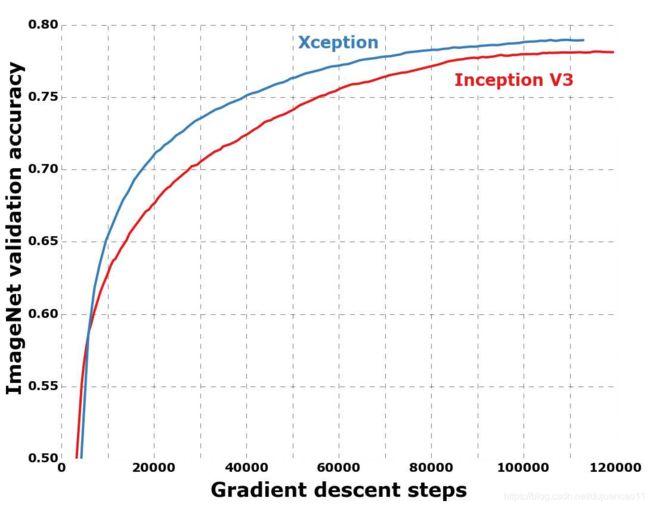
图7 在JFT上的培训简介,没有全连接层
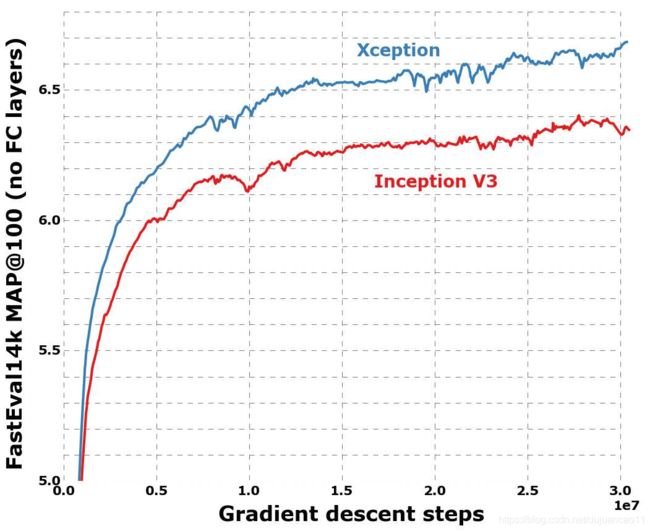
4.5.2 尺寸和速度
表3 大小和训练速度的比较。

在表3中,我们比较了Inception V3和Xception的大小和速度。在ImageNet上报告参数计数(1000个类,没有完全连接的层),在运行同步梯度下降的60 K80个gpu上报告每秒的训练步骤(梯度更新)数。这两种架构的大小大致相同(在3.5%以内),而Xception稍微慢一些。我们期望在深度卷积操作级别上的工程优化可以使Xception在不久的将来比Inception V3更快。这两种架构具有几乎相同数量的参数这一事实表明,在ImageNet和JFT上看到的改进不是来自增加的容量,而是来自更有效地使用模型参数。
4.6 剩余连接的影响
图9 有和没有剩余的联系的培训档案。
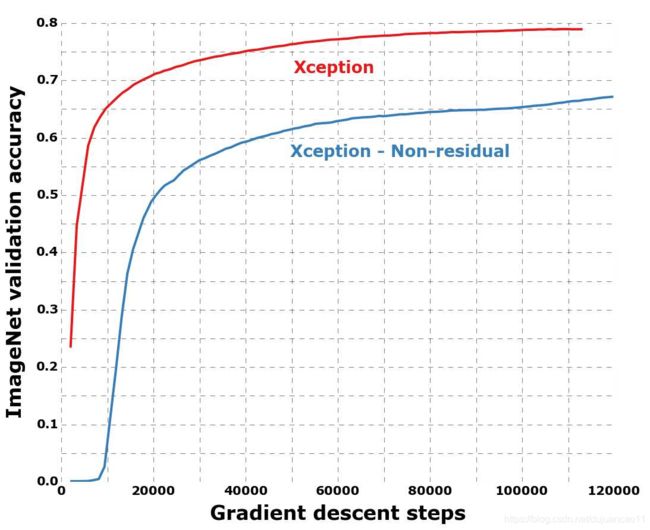
为了量化Xception架构中残余连接的好处,我们在ImageNet上对不包含任何残余连接的修改版本进行了基准测试。结果如图9所示。在速度和最终分类性能方面,残余连接在帮助收敛方面显然是必不可少的。然而,我们将注意到,使用与剩余模型相同的优化配置对非剩余模型进行基准测试可能是不仁慈的,更好的优化配置可能产生更有竞争力的结果。
另外,让我们注意到这个结果仅仅显示了剩余连接对于这个特定架构的重要性,并且剩余连接对于构建深度可分离的卷积堆的模型并不是必需的。在非残留vggstyle模型中,所有卷积层都替换为深度可分离卷积(深度乘子为1),在参数计数相等的情况下优于InceptionV3。
4.7 点态曲后中间激活的效应
图10 可分离卷积层的深度和点态操作的不同激活的训练轮廓。
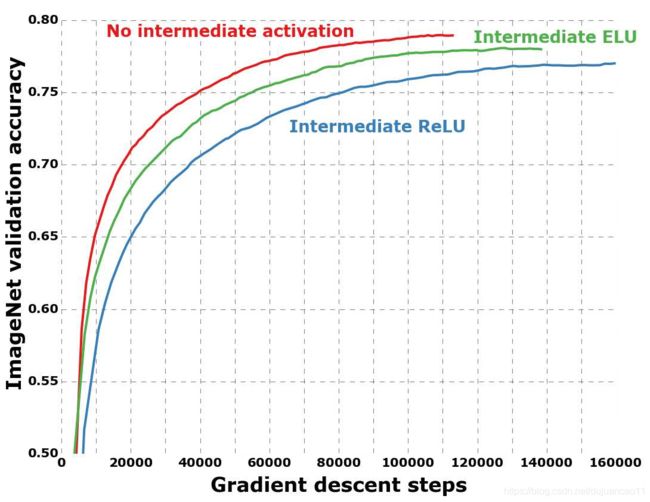
我们之前提到过,深度可分离卷积和Inception模块之间的类比表明,深度可分离卷积应该潜在地包括深度和点态操作之间的非线性。在目前报道的实验中,没有包含这样的非线性。然而,我们也通过实验测试了ReLU或ELU[3]作为中间非线性。在ImageNet上的结果如图10所示,结果表明,没有任何非线性会导致更快的收敛速度和更好的最终性能。
这是一个值得注意的观察,因为Szegedy等人在Inception模块的[21]中报告了相反的结果。可能的中间特征空间的深度空间运算应用至关重要有用的非线性:深功能空间(如发现《Inception》里的模块)非线性是有用的,但对于浅的(例如1通道深功能空间通过卷积切除可分)它变得有害,可能由于信息的损失。
5. 未来的发展方向
我们先前注意到在规则卷积和深度可分离卷积之间存在一个离散谱,由用于执行空间卷积的独立信道空间段的数量参数化。Inception模块是这个范围中的一点。在经验计算中,我们证明了Xception,即深度可分离卷积,可能比正则启始模有更大的优势。然而,没有理由相信深度上的可分离卷积是最佳的。可能是频谱上位于规则先启模块和深度可分离卷积之间的中间点具有进一步的优势。这个问题留待以后研究。
6. 结论
我们展示了卷积和深度可分离卷积如何位于离散谱的两个极端,先启模块是两者之间的一个中间点。这一观察结果促使我们提出用深度可分离的卷积来代替神经计算机视觉结构中的初始模块。我们提出了一种基于此思想的新架构,名为Xception,它的参数计数与Inception V3相似。与Inception V3相比,Xception在ImageNet数据集的分类性能上有小的提升,而在JFT数据集上有大的提升。我们期望深度可分离卷积成为未来卷积神经网络架构设计的基石,因为它们提供了与Inception模块相似的特性,但也像常规卷积层一样易于使用。
References
[1] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen,C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghe-
mawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia,R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Man ´ e,
R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster,J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Van-
houcke, V. Vasudevan, F. Vi ´ egas, O. Vinyals, P. Warden,M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng. Tensor-
Flow: Large-scale machine learning on heterogeneous sys-tems, 2015. Software available from tensorflow.org.
[2] F. Chollet. Keras. https://github.com/fchollet/keras, 2015.
[3] D.-A. Clevert, T. Unterthiner, and S. Hochreiter. Fast andaccurate deep network learning by exponential linear units(elus). arXiv preprint arXiv:1511.07289, 2015.
[4] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385,
2015.
[5] G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network, 2015.
[6] A. Howard. Mobilenets: Efficient convolutional neural net-works for mobile vision applications. Forthcoming.
[7] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift.
In Proceedings of The 32nd International Conference on Machine Learning, pages 448–456, 2015.
[8] J. Jin, A. Dundar, and E. Culurciello. Flattened convolutional neural networks for feedforward acceleration. arXiv preprint
arXiv:1412.5474, 2014.
[9] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In
Advances in neural information processing systems, pages1097–1105, 2012.
[10] Y. LeCun, L. Jackel, L. Bottou, C. Cortes, J. S. Denker,H. Drucker, I. Guyon, U. Muller, E. Sackinger, P. Simard,
et al. Learning algorithms for classification: A comparison on handwritten digit recognition. Neural networks: the statistical
mechanics perspective, 261:276, 1995.
[11] M. Lin, Q. Chen, and S. Yan. Network in network. arXiv preprint arXiv:1312.4400, 2013.
[12] F. Mamalet and C. Garcia. Simplifying ConvNets for Fast Learning. In International Conference on Artificial Neural
Networks (ICANN 2012), pages 58–65. Springer, 2012.
[13] B. T. Polyak and A. B. Juditsky. Acceleration of stochas-tic approximation by averaging. SIAM J. Control Optim.,
30(4):838–855, July 1992.
[14] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma,Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Ima-
genet large scale visual recognition challenge. 2014.
[15] L. Sifre. Rigid-motion scattering for image classification,2014. Ph.D. thesis.
[16] L. Sifre and S. Mallat. Rotation, scaling and deformation invariant scattering for texture discrimination. In 2013 IEEE
Conference on Computer Vision and Pattern Recognition,Portland, OR, USA, June 23-28, 2013, pages 1233–1240,
2013.
[17] N. Silberman and S. Guadarrama. Tf-slim, 2016.
[18] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint
arXiv:1409.1556, 2014.
[19] C. Szegedy, S. Ioffe, and V. Vanhoucke. Inception-v4,inception-resnet and the impact of residual connections on
learning. arXiv preprint arXiv:1602.07261, 2016.
[20] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov,D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper
with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015.
[21] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna.Rethinking the inception architecture for computer vision.
arXiv preprint arXiv:1512.00567, 2015.
[22] T. Tieleman and G. Hinton. Divide the gradient by a run-ning average of its recent magnitude. COURSERA: Neural
Networks for Machine Learning, 4, 2012. Accessed: 2015-11-05.
[23] V. Vanhoucke. Learning visual representations at scale. ICLR,2014.
[24] M. Wang, B. Liu, and H. Foroosh. Factorized convolutionalneural networks. arXiv preprint arXiv:1608.04337, 2016.
[25] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014,
pages 818–833. Springer, 2014.