机器学习笔记(十二)计算学习理论
12.计算学习理论
12.1基础知识
计算学习理论(computationallearning theory)研究的是关于通过计算来进行学习的理论,即关于机器学习的理论基础,其目的是分析学习任务的困难本质,为学习算法提供理论保证,并根据分析结果指导算法设计。理论是共性的、抽象的,是基于众多个体总结出来的规律,反过来可以作为个体的理论依据。

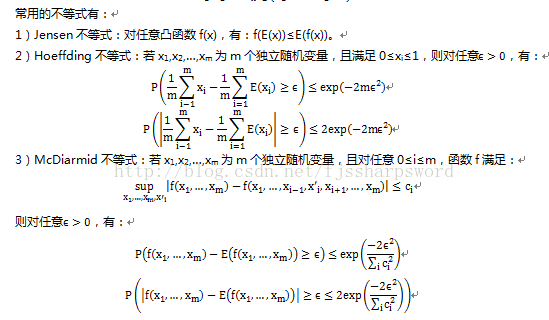
12.2PAC学习
计算学习理论中最基本的是概率近似正确(probably approximately correct,pac)学习理论。
令c表示概念(concept),是从样本空间X到标记空间Y的映射,它决定示例x的真实标记y,若对任何样例(x,y)有c(x)=y成立,则称c为目标概念;所有学得的目标概念所构成的集合称为概念类(concept class),用C表示。
给定学习算法A,其所考虑的所有可能概念的集合称为假设空间(hypothesis space),用符号H表示。学习算法事先并不知道概念类的真实存在,因此H和C通常是不同的。学习算法会把自认为可能的目标概念集中起来构成H,对h∈H,由于并不能确定它是否真是目标概念,因此成为假设(hypothesis)。假设h也是从样本空间X到标记空间Y的映射。
若目标概念c∈H,则H中存在假设能将所有示例按与真实标记一致的方式完全分开,称该问题对学习算法A是可分的(separable),也称为一致性(consistent);若c∉H,则H中不存在任何假设能将所有示例完全正确分开,称该问题对学习算法A是不可分的(non-separable),也称不一致性(non-consistent)。
给定训练集D,期望基于学习算法A学得的模型所对应的假设h尽可能接近目标概念c。由于机器学习过程受到众多因素制约,包括样本数量的有限性、采样的偶然性,因此只能接近目标概念,而不能精确,希望以比较大的把握学得比较好的模型,也就是说,以较大的概率学得误差满足预设上限的模型,也就是PAC定义的来由,使概率上近似正确。
如上,PAC学习给出了一个抽象地刻画机器学习能力的框架,基于这个框架能对很多重要问题进行理论探讨,如研究某任务在什么样的条件下可学得较好的模型?某算法在什么样条件下可进行有效的学习?需多少训练样例才能获得较好的模型?
PAC学习中一个关键因素是假设空间H的复杂度。H包含了学习算法A所有可能输出的假设,若在PAC学习中假设空间与概念类完全相同,即H=C,称为恰PAC可学习(properly PAC Learnable);直观上理解,意味着学习算法的能力与学习任务恰好匹配。然后,这种让所有候选假设都来自概念类的要求并不切实际,因为现实中对概念类C通常是一无所知。因此,重要的研究假设空间与概念类不同的情形,即H≠C。一般而言,H越大,其包含任意目标概念的可能性越大,但从中找到某个具体目标概念的难度也越大。|H|有限时,称H为有限假设空间,否则称为无限假设空间。
12.3有限假设空间
1)可分情形
可分情形是说目标概念c属于假设空间H,即c∈H。给定包含m个样例的训练集D,如何找出满足误差参数的假设呢?
既然D中样例标记都是由目标概念c赋予的,并且c存在于假设空间H中,那么任何在训练集D上出现标记错误的假设肯定不是目标概念c。如此,只需保留与D一致的假设,剔除与D不一致的假设即可。
如训练集D足够大,则可不断借助D中的样例剔除不一致的假设,直到H中仅剩下一个假设为止,这个假设就是目标概念c。通常情形下,由于训练集规模有限,假设空间H中可能存在不止一个与D一致的等效假设,对这些等效假设,无法根据D来对它们的优劣进行进一步区分。


12.4VC维
现实学习任务所面临的通常是无限假设空间,例如实数域中的所有区间、Rd空间中的所有线性超平面。要对这类学习任务的可学习性进行研究,通过考虑假设空间的VC(Vapnik-Chervonenkis dimension)维来度量假设空间的复杂度。先引入增长函数(growth function)、对分(dichotomy)和打散(shattering)。






12.5Rademacher复杂度
上文推出基于VC维的泛化误差界是分布无关、数据独立的,即对任何数据分布都成立,使基于VC维的可学习性分析结果具有一定的普适性;但从另一方面来说,由于没有考虑数据自身,基于VC维得到的泛化误差界通常比较松,尤其是与学习问题相差甚远的不好分布。
Rademacher复杂度(Rademachercomplexity)是另一种刻画假设空间复杂度的途径。和VC维不同的是,它在一定程度上考虑了数据分布。




12.6稳定性
基于VC维和Rademacher复杂度来推导泛化误差界,所得结果与具体算法无关,对所有学习算法适用,是通用性算法可学习性的刻画。学习理论的意义就在于从个体中总结出一般规律,从而应用于实际。与算法无关的学习理论,固然可以脱离具体学习算法设计而考虑学习问题本身的性质,但若要获得与算法有关的分析结果,则需另辟蹊径;稳定性(stability)分析就是分析算法相关的。
算法的稳定性考察的是算法在输入发生变化时,输出是否也随之发生变化。学习算法的输入是训练集,先定义两种训练集的变化。
给定D={ z1=(x1,y1),z2= (x2,y2),…, zm= (xm,ym)},xi∈X是来自分布D的独立同分布示例,yi∈{-1,+1}。对假设空间H:X->{-1,+1}和学习算法A,令AD∈H表示基于训练集D从假设空间H中学得的假设,考虑下面两种变化:
1)D\i表示移除D中第i个样例得到的集合D\i={z1, z2,…, zi-1, zi+1,…, zm};
2)Di表示替换D中第i个样例得到的集合Di={z1, z2,…, zi-1, z*i ,zi+1,…,zm};
其中z*i={x*i, y*i},x*i服从分布D并独立于训练集。
损失函数Loss(AD(x),y):YxY->R+刻画了假设AD的预测标记AD(x)与真实标记y之间的差别,记为Loss(AD,z)。下面定义关于假设AD的几种损失:
1)泛化损失:Loss(A,D)=E x ∈X,z=(x,y)[ Loss(A D,z)]。

