深度学习论文翻译 -- Densely Connected Convolutional Networks
本文翻译论文为深度学习经典模型之一:DenseNet
论文链接:https://arxiv.org/pdf/1608.06993.pdf
摘要:最近的研究表明,如果在卷积网络的输入与输出之间添加短连接(shorter connections),那么可以使得网络变得更深、更准,并且可以更有效的训练。本文,我们围绕短连接思想,提出密集卷积网络(DenseNet):前向传播中,每一层都与其前面的所有层连接。传统的L层卷积网络有L个连接(每层都有一个连接),而我们的网络有L(L+1)/2个连接。对于网络的每一层,前面所有层的网络都作为该层的输入,那么本身的特征图作为后续所有层的输入。DenseNet具有几个明显的优势:缓解梯度消失问题,加强特征传播,特征重利用,极大地减少了参数量。我们在四种数据集(CIFAR-10,CIFAR-100,SVHN and ImageNet)上评估模型,获得很好的效果,并且计算复杂度低。代码以及预训练模型https://github.com/liuzhuang13/DenseNet.
1、Introduction
卷积网络已经成为视觉目标识别领域的主流方法。虽然20年前被提出,但是网络结构和计算机硬件限制了它的兴起。LeNet5包含5层,VGG19包含19层,最近的高速网络(Highway Networks)和ResNet均超过了100层。
随着CNN不断的加深,新的问题出现:当输入和梯度在层间流动的时候,可能在到达网络的最后之前(或者一开始)就会消失。最近的很多工作都在解决这个问题。ResNet和Highway Networks通过恒等连接解决层间信息的流动。训练过程中,通过对ResNet随机进行深度缩减,信息和梯度可以更好的流动。FractalNets重复的将不同数量并行序列的卷积块合并,得到名义上的深度网络,并且保留了很多快捷连接。尽管上述网络在结构和训练方式上有一定的差别,但是他们有个共同的特点:都在层与层之间创建了短连接。
本文中,我们提出一种网络结构,它将short path细化为一种简单的连接模式:保证层间信息流动的最大化,我们将所有的层与其它层连接(但得保证具有相同大小的特征图)。为了保留前向传播的特性,每一层将前面的层作为输入,并且将其自己的特征图传递到后面的层。图1给出了这种设计模式。更为关键的是,与ResNet对比,其它层传入该层的方式并不是求和的方式,相反我们将前几层的特征进行连接(concatenating)。因此,第L层具有l个输入(前面所有层的连接组合)。它本身的特征图传递到所有后面的L-l层。所以,L层的网络具有L(L+1)/2个连接,而不是像传统网络具有L个连接。由于其特有的连接模式,称之为Dense Convolutional Network(DenseNet)。
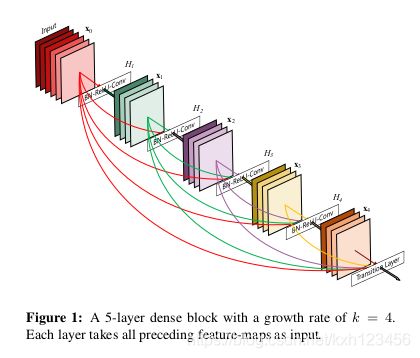
DenseNet这种密集连接的方式,虽然直觉上可能参数很多,但是事实却比传统网络参数更少,因为不需要重新学习多余的特征图信息。传统的前向结构可以看作一个状态(state),它们在层之间传递。每一层都会读取前面网络层的状态,并传递给下一层。转态改变的同时,也会保存传递的信息。ResNet通过额外的恒等连接保存传递的信息。最近,ResNet的变体表明:很多层对于网络的贡献很少,并且可以被随机的丢弃。这使得ResNet的状态类似于RNN,但是ResNet的参数很多(由于每一层都有自己的权重)。我们提出的DenseNet网络使得要加到网络的信息和要保存的信息是有差别的。DenseNet的网络结构是很窄的(例如每一层有12个卷积核),仅仅将少部分的特征图添加到信息收集器(collective knowledge),保持其它的信息不变,最终分类器根据所有的网络特征图进行分类预测。
除了更少的参数量,DenseNet的另一个优势:改善了网络之间信息和梯度的流动,使得网络更容易训练。每一层都可以直接与损失函数传回的梯度有联系以及原始的输入信息,形成了隐含的深度监督。这有助于提升网络训练。更进一步,我们观察到,密集连接具有正则化的作用,在小的数据集上具有缓解过拟合的作用。
2、Related Work
自神经网络出现以来,网络结构的探索是其重要的一部分。神经网络的再次兴起,刺激了网络结构领域的研究。不断增加网络层 的现代神经网络详细论述了不同的网络结构的差别,并且刺激了不同连接模式的探索,以及使用现代神经网络的思想思考早期的研究内容。
上世纪80年代提出的一种级联的结构与我们提出的DenseNet结构类似。前人使用MLP进行网络训练。最近,[40]提出添加BN的全连接级联网络。尽管在小数据集上有效,但是这种方法仅仅能够扩展到几百个参数的网络。在[9,23,31,41]中,在有跳跃连接的CNN网络中使用多层次特征,对不同的视觉任务有较好的效果。[1]推导出新的网络(cross layer connections)与我们的类似。
Highway网络是第一个提出超过100层的端到端训练的网络。使用带有门单元的分支路径,Highway网络可以优化超过100层的网络。假定分支路径(bypassing paths)是降低网络训练难度的重要原因。该观点被ResNet认可,因为恒等连接被认为是一种分支路径。ResNet在不同的分支任务中都有非常好的表现。最近,随机深度网络的提出使得1202层的ResNet可以被训练。训练过程中,随机深度通过随机丢弃层来训练深度残差网络。实验表明,深度残差网络中很多特征是冗余的,很多层其实是不必要的。我们的文章部分借鉴了这个概念。ResNet使用预激活(pre-activation)的方式促进1000层的网络训练。
另一个使网络更优的方法是增加宽度(with the help of skip connections)。比如,GoogLeNet使用Inception模块,将不同数量的卷积核拼接在一起。事实上,仅仅提高ResNet每一层的卷积核数量也是很有效的。FractalNet使用宽的网络结构,也能取得较好的效果。
不同于提升网络的深度和宽度,DenseNet通过特征的重用来提高网络的潜力,得到浓缩的模型(容易训练并且很高的参数效率)。将不同层学习的特征图连接,提高了每一层输入的变化以及效率。这是ResNet和DenseNet最大的区别。与Inception网络相比,也是将不同的特征组合,但是DenseNet更简单,更有效。
其它引人注目的网络结构,取得很好的效果。比如,NIN网络在卷积层中引入微型多层感知机(MLP),提取更加复杂的特征。在DSN(Deeply Supervised Network)中,内部层直接被辅助分类器监督训练,可以保证前几层网络可以接受到有效的梯度回传信息。Ladder Networks在autoencoders引入侧连接(lateral connections),在半监督学习任务中取得不错的精度。在[39]中,DFNS通过结合不同基础网络的中间层,有效的保证信息的流动。
3、DenseNet
考虑输入到卷积网络的单张图![]() ,网络包含L层,每一层包含一个非线性变换
,网络包含L层,每一层包含一个非线性变换![]() ,l 表示层。
,l 表示层。![]() 包含基本的操作:BN,Pooling,ReLU以及Conv。第 l 层的输出是
包含基本的操作:BN,Pooling,ReLU以及Conv。第 l 层的输出是![]() 。
。
ResNets. 传统的卷积网络的前向传播中,第 l 层的输出是第(l+1)的输入,形式:![]() 。ResNet添加了边路的恒等映射变换:
。ResNet添加了边路的恒等映射变换:
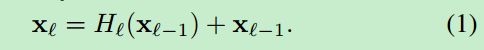
ResNet的优势是可以使得梯度可以通过恒等映射函数传递到网络前几层。但是,恒等映射函数通过相加的方式与![]() 结合,这可能阻碍信息在网络中流动。
结合,这可能阻碍信息在网络中流动。
Dense Connetivity. 为了进一步提高信息在网络之间的流动,我们提出了一种不同的连接模式:我们将任何一层都与后续的每一层进行连接。图1给出了一个模块的结构。因此,![]() 层接受前面所有层的特征图,
层接受前面所有层的特征图,![]() ,作为输入:
,作为输入:
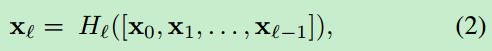
这里,![]() 是第0,...,l-1层产生的特征图。由于其密集连接,我们称之为DenseNet,我们将多个输入连接为一个tensor。
是第0,...,l-1层产生的特征图。由于其密集连接,我们称之为DenseNet,我们将多个输入连接为一个tensor。
Composite Function. 受[12]启发,我们将![]() 定义为包含三个连续操作的复合函数:BN+ReLU+Conv(3x3)。
定义为包含三个连续操作的复合函数:BN+ReLU+Conv(3x3)。
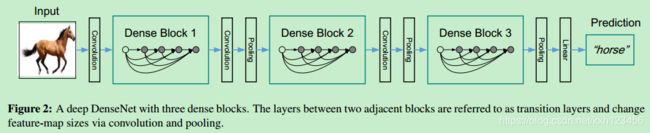
Pooling Layers. 当特征图的大小改变时,方程(2)中的连接操作不可执行。但是,卷积网络的一个核心操作(pooling)可以改变特征图的尺寸。为了使用下采样,我们将网络分为多个dense blocks,见图2。我们将相邻层之间称为转换层(transition layers),执行卷积核池化操作。转换层结构:BN+1x1Conv+2x2AveragePooling。

Growth Rate. 如果每一个![]() 产生k个特征图,那么下一层
产生k个特征图,那么下一层![]() 的输入具有
的输入具有![]() 个特征图,
个特征图,![]() 是输入层特征图数量。ResNet与DenseNet的重要差别:DenseNet网络非常的窄,比如k=12(那么Dense Block每一层产生k个特征图)。我们称k为增长率。Section4表明,一个小的k值就能获得较好的网络性能。DenseNet的一种解释:dense block每一层都可以获取前面所有特征图,并放入网络的"collective knowledge"。我们可以将特征图视为网络的全局状态。每一层添加k个特征图到这个状态。增长率k决定了每一层有多少新信息贡献到这种全局状态。全局状态(global state)一旦确定,网络的任何一部分都可以获取,然而,传统网络没有具备这种重用的特性。
是输入层特征图数量。ResNet与DenseNet的重要差别:DenseNet网络非常的窄,比如k=12(那么Dense Block每一层产生k个特征图)。我们称k为增长率。Section4表明,一个小的k值就能获得较好的网络性能。DenseNet的一种解释:dense block每一层都可以获取前面所有特征图,并放入网络的"collective knowledge"。我们可以将特征图视为网络的全局状态。每一层添加k个特征图到这个状态。增长率k决定了每一层有多少新信息贡献到这种全局状态。全局状态(global state)一旦确定,网络的任何一部分都可以获取,然而,传统网络没有具备这种重用的特性。
Bottleneck Layers. 尽管每一层仅仅产生k个特征图,但是每一层有很多的输入。[37, 11]表明1x1卷积可以作为瓶颈层(bottleneck layer),降低输入特征图的数量(放在3x3卷积前),这样可以提高计算效率。我们发现这种结构对于DenseNet依然有效,我们在网络中添加这样的一层:![]() ,BN-ReLU-1x1Conv-BN-ReLU-3x3Conv,称为DenseNet-B。在我们的实验中,我们让1x1Conv产生4k特征图。
,BN-ReLU-1x1Conv-BN-ReLU-3x3Conv,称为DenseNet-B。在我们的实验中,我们让1x1Conv产生4k特征图。
Compression. 为了进一步压缩模型,我们可以降低转换层(transition layers)的特征图数量。如果一个Dense Block包含m个特征图,我们让转换层(transtiate layer)产生![]() 个特征图,
个特征图,![]() 。如果
。如果![]() ,特征图数量不变。若
,特征图数量不变。若![]() ,称为DenseNet-C,论文实验中,
,称为DenseNet-C,论文实验中,![]() 。当bottleneck和transition layers同时使用,并且
。当bottleneck和transition layers同时使用,并且![]() ,那么称为DenseNet-BC。
,那么称为DenseNet-BC。
Implementation Details. 除了ImageNet数据集,其它所有数据集上,使用三个dense block,每一个具有相同的层。在流入第一个dense block的时候,添加一层卷积,输出通道为16(或者DenseNet-BC模块,大小为2k)。卷积核的大小为3x3,每一边进行零填充一个像素。两个dense block之间使用1x1conv+2x2average pooling。在最后的dense block后,添加全局平均池化和softmax 分类器。三个dense block特征图大小分别为32x32,16x16,8x8。我们使用基本的DenseNet结构,配置如下:{L=40,k=12},{L=100,k=12}以及{L=100,k=24}。对于DenseNet-BC,配置如下:{L=100, k=12},{L=250,k=24}以及{L=190,k=40}。
在ImageNet数据集上,使用4个DenseNet-BC,输入图像大小为224x224,第一层卷积包含2k个7x7卷积,滑动为2;其它层的卷积核数量根据 k 的大小而定。准确的配置如表1:

4、Experiments
我们在几个公开数据集上评测了DenseNet的效果,并且与ResNet以及其变体做了比较。
4.1、Datasets
CIFAR. 大小32x32,训练集:50000(分出5000作为验证集),测试集:10000,数据增强:镜像,随机裁剪;
SVHN(Street View House Numbers):大小32x32,训练集:73257,测试集:26032,额外的训练集:531131。不作数据增强,从训练集取出6000作为验证集。归一化方式为:每个像素除以255.
ImageNet:训练集,120万,验证集,5万;
4.2、Training
优化器:SGD
CIFAR、SVHN:batch size 64,分别训练300, 40epoch,学习率:初始0.1,在训练到50%和75%epoch,除以10,除了第一层卷积,其它卷积后面都添加dropout,大小为0.2;
ImageNet:训练90epoch,batch size:256,学习率:0.1,在30和60epoch,除以10;
4.3、Classification Results on CIFAR and SVHN
使用不同的深度,L,以及增长率k。主要的结果见表2.

5、Discussion
表面上,DenseNet与ResNets非常相似,方程(2)和方程(1)最大的差别是输入是concatenated,而不是求和。但是,也正是这一点的差别,导致两种结构有着本质的区别。
Model Compactness. 输入concatenation的直接的结果是:任何层学习到的特征图都可以被后续的其它层使用。这使得特征可以再次利用(贯穿整个网络),模型变得更加紧凑。
图4左边两张图比较了网络参数的应用效率:

Implicit Deep Supervision. 稠密网络能够很好的训练,并且取得不错的效果,一个解释:通过短连接,损失函数可以监督每一层的训练。可以认为DenseNet呈现一种隐含的深度监督。深度监督的概念首次呈现在DSN网络中,它将分类器连接到每一个隐藏层,强迫中间层学习具有判别性的特征。
DenseNet以一种隐含的方式执行了类似的深度监督:分类器位于网络的顶端,通过转换层(transition layers),分类器可以监督所有的层。但是,DenseNet的损失函数和梯度复杂度都很低,同一个损失函数被所有层共享。
Stochastic vs. Deterministic Connection. 稠密网络和随机深度正则化的残差网络有一个有趣的联系。在随机深度中,残差网络中的层被随机丢弃,周围的层进行直接的连接。由于池化层不会被丢弃,该网络与DenseNet有着类似的连接模式:两个相同的池化层可能被连接。尽管两种方法最终是不一样的,但是DenseNet给出了相应的正则化解释。
Feature Reuse. 通过设计,DenseNet的层可以获得前面所有层的特征(尽管有时候通过转换层,Transition Layer)。我们设计了一个实验:一个训练好的网络可以重复利用特征的。我们首先在C10+上训练DenseNet,L=40,k=12。对于dense block内的每一层 l,计算平均权重(与层s连接的部分)。图5给出了所有的dense block的热量图。平均权重表示每一层对前面层的依赖程度。(l,s)位置中的红色点表示层l对前面层的使用程度非常高。从图5中可以得到如下结论:
图5解释:每个颜色方格是通过计算该层的平均权重(L1 Norm),并按照计算值的大小,给出相应的颜色;s和l分别表示一个dense block内的前层和后层;标注黑色矩形框的三列,表示两层Transition Layer以及Classification Layer;

- 所有的层会将权重传播到同一个dense block内的所有层,进行使用。这足以表明:早期提取的特征可以被同一个dense block内所有层直接使用;
- 转化层的权重也会传播到前面dense block内部的每一层,表明,transition layers使用前面层的特征;
- 第2-3个Denseblock中的层对之前Transition layer利用率很低(block2和block3的第一层都是蓝色),说明transition layer输出大量冗余特征.。这也为DenseNet-BC模块提供了证据支持,即:Compression的必要性;
- 最后的分类层虽然使用了之前dense block中的多层信息,但更偏向于使用最后几个feature map的特征,说明在网络的最后几层,某些high-level的特征可能被学习到;
6、论文核心点解析
DenseNet结构:图1是DenseNet的一个Dense Block(H1,H2,H3,H4,Transition Layer),总共5层;x1,x2,x3,x4是H对应的输出;growth rate = 4,表示每一层输出的通道数(图中,输出均是4张特征图);H的结构:BN+ReLU+Conv

图2是DenseNet的整体结构:两个Dense Block之间,称之为Transition Layers(结构:BN+1x1Conv+2x2AveragePooling)
DenseNet-B:尽管每一层产生k个feature-maps,但是每一层的输入(concatenate)维度很大。为了提升效率,使用Bottleneck layers(1x1Conv),结构为:BN+ReLU+1x1Conv-BN+ReLU+3x3Conv;论文中,1x1Conv产生4k feature-maps;
DenseNet-C:作者发现,网络很深的情况下,很多feature-maps作用并不是很大,可以丢弃一部分;因此,提出该结构,将transition layer的feature-maps(假设m个)减少,乘以系数![]() ,
,![]() ,本文设置为0.5的衰减;
,本文设置为0.5的衰减;
DenseNet-BC:同时使用BC的情况下,并且![]() ;
;
DenseNet思想:
- Feature Reuse:作者不再进行网络深度和宽度方面的研究,而是研究如何充分利用卷积特征(feature reuse);每个层都会接受其前面所有层作为额外的输入,特征图进行连接(channel concatenate),形成密集的连接方式,使得特征可以被网络的任何层利用,见图1;
- Dense Connection:密集连接方式,使得梯度更新更稳定,网络更容易训练;由于每一层都可以直达最后的误差信号,实现了隐含的 "deep supervision";
- Parameter Efficiency:使用了非常少的特征图,参数更少,并且参数的利用率很高,降低冗余信息;
- Regular:DenseNet具有正则化作用,小数据集上训练,可以缓解过拟合;
DenseNet不足:占用显存,具体可以参考:https://www.zhihu.com/question/60109389/answer/203099761
参考资源:https://www.imooc.com/article/36508