MNIST手写体识别(Tensorflow)
文章目录
- 一、Tensorflow配置与安装
- 二、卷积神经网络ConvNet
- 1.卷积层(Padding)
- 2.Pooling层
- 3.全连接层
- 三、MNIST数据集的特征
- 1.MNIST训练集的特征
- 2.MNIST测试集的预测情况
- 容易误判但是判断正确的图像
- 误判的图像
一、Tensorflow配置与安装
Python3.6.2 + Anaconda (conda 4.3.27)+ tensorflow-gpu1.8.0下测试通过
1.首先要安装CUDA,我安装的是CUDA9.0
安装完之后在命令行输入可以查看是否安装成功以及版本:
nvcc -V

2.其次是安装Anaconda
我是选择用Anaconda安装tensorflow,方便管理各种环境。(还有pip直接安装tensorflow库的办法,但是由于我的python2和python3的环境有点冲突,当时没有弄好,现在发现原来是我在给3版本的python重命名为python3的时候,只修改了名字没有修改里面的文件埋下了隐患,详情见这篇文章:两个版本的python,现在是解决了,这里还是选择用Anaconda安装tensorflow)
在 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 寻找你与你电脑系统对应的版本。下载对应安装包,按提示安装,查看版本查看是否安装成功:
conda --version

在Anaconda里建立TensorFlow的环境:
conda create -n tensorflow Python=3.6
激活TensorFlow环境:
activate TensorFlow
关闭环境:
deactivate
3.安装TensorFlow
pip install --upgrade --ignore-installed tensorflow-gpu
安装TensorFlow指定版本
pip3 install --upgrade tensorflow_gpu
(我是pip3,因为用python3安装的气自己修改了名字)
简单测试:
在TensorFlow环境里打开Python:
import tensorflow as tf
hello = tf.constant("Hello!TensorFlow")
sess = tf.Session()
print(sess.run(hello))
可以运行就说明安装成功了,或者也可以通过查看tensorflow版本查看是否安装成功。
具体有啥问题可以参考官网:
http://www.tensorfly.cn/tfdoc/get_started/os_setup.html
有一个GPU的检测

二、卷积神经网络ConvNet
背景:如果采用全连接结构,存在参数爆炸问题。如对1000 * 1000 的图像进行卷积,大约需要1000 * 1000 * 1000 * 1000个参数。 利用局部卷积替换全连接结构,可将参数降低至1000 * 1000 * 10 * 10 ≈ 100M。如果进一步采用权值共享的策略,即同一特征图卷积核、 Bias相同,将卷积参数将至10*10。为尽可能地保存信息,可 设计多个卷积特征图,将参数将至10K。
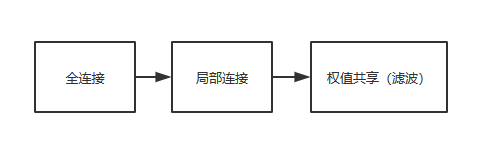
在卷积网络(ConvNet)中,基本上有三种类型的层:
1.卷积层(Convolution layer)
2.Pooling层(Pooling layer)
3.全连接层(Fully connected layer)
1.卷积层(Padding)
卷积层是为了增加特征图,每进行一次卷积操作就会多输出一张图像。
用3×3滤波器对6×6维的输入进行卷积,得到4×4输出。我们可以推广它并说如果输入是n X n并且滤波器大小是f X f,那么输出大小将是
( n − f + 1 ) X ( n − f + 1 ) (n-f + 1)X(n-f + 1) (n−f+1)X(n−f+1):
输入: n X n
滤镜尺寸: f X f
输出:(n-f + 1)X(n-f + 1)
这里主要有两个缺点:
每次我们应用卷积运算时,图像的大小都会缩小
与中心像素相比,在卷积期间存在于图像角落中的像素仅使用了几次。因此,我们不会过分关注角落,因为这会导致信息丢失
为了克服这些问题,我们可以使用额外的边框填充图像,即我们在边缘周围添加一个像素。这意味着输入将是8×8矩阵(而不是6×6矩阵)。在其上应用3×3的卷积将产生6×6矩阵,这是图像的原始形状。这就是padding出现的地方:
输入: n X n
填充: p
滤镜尺寸: f X f
输出:(n + 2p-f + 1)X(n + 2p-f + 1)
填充有两种常见的选择:
有效:表示没有填充。如果我们使用有效填充,输出将是
( n − f + 1 ) ∗ ( n − f + 1 ) (n-f + 1)*(n-f + 1) (n−f+1)∗(n−f+1)
相同:这里,我们应用填充,使输出大小与输入大小相同,即
n + 2 p − f + 1 = n n + 2p-f + 1 = n n+2p−f+1=n
因此,p =(f-1)/ 2
我们现在知道如何使用填充卷积。这样我们就不会丢失大量信息,图像也不会缩小。
一旦我们使用过滤器对整个图像进行卷积后得到输出,我们就会向这些输出添加偏置项,最后应用激活函数来生成激活。这是一个卷积网络的一层。

卷积层的符号摘要:
f [l] =滤波器大小
p [l] =填充
s [l] =步幅
n [c] [l] =过滤器数量
在我们的例子中,输入(6×6×3)是[0],滤波器(3×3×3)是权重w [1]。来自第1层的这些激活充当第2层的输入,依此类推。显然,在卷积神经网络的情况下参数的数量与图像的大小无关。它主要取决于过滤器的大小。假设我们有10个滤波器,每个滤波器的形状为3 X 3 X 3.该层中的参数数量是多少?
每个滤波器的参数数量= 3 * 3 * 3 = 27
每个过滤器都有一个偏差项,因此每个过滤器的总参数= 28
由于有10个过滤器,该层的总参数= 28 * 10 = 280
无论图像有多大,参数仅取决于滤镜的大小。
2.Pooling层
Pooling层主要用于减小输入的大小,从而加速计算。也就是将高分辨率的图像转换为低分辨率的图像。
 图片来源:http://cs231n.github.io/convolutional-networks/
图片来源:http://cs231n.github.io/convolutional-networks/
原版的LeNet的Pooling是平均采样,现在是Maxpooling,更多Pooling方法参考链接
max pooling 的操作:整个图片被不重叠的分割成若干个同样大小的小块(pooling size)。每个小块内只取最大的数字,再舍弃其他节点后,保持原有的平面结构得出 output。
Max pooling 的主要功能是 downsampling(降采样),却不会损坏识别结果。 这意味着卷积后的 Feature Map 中有对于识别物体不必要的冗余信息。 那么我们就反过来思考,这些 “冗余” 信息是如何产生的。
直觉上,我们为了探测到某个特定形状的存在,用一个 filter (滤波器)对整个图片进行逐步扫描。但只有出现了该特定形状的区域所卷积获得的输出才是真正有用的,用该 filter 卷积其他区域得出的数值就可能对该形状是否存在的判定影响较小。 比如下图中,我们还是考虑探测 “横折” 这个形状。 卷积后得到 3x3 的 Feature Map 中,真正有用的就是数字为 3 的那个节点,其余数值对于这个任务而言都是无关的。 所以用 3x3 的 Max pooling 后,并没有对 “横折” 的探测产生影响。 试想在这里例子中如果不使用 Max pooling,而让网络自己去学习。 网络也会去学习与 Max pooling 近似效果的权重。因为是近似效果,增加了更多的 parameters 的代价,却还不如直接进行 Max pooling。

3.全连接层
在CNN的训练架构中,全连接层的学习和BP完全一致。
BP网是一种前馈多层(一般都选用3层)网络。理论已经证明一个三 层网络可以无限近似任意连续函数。
 计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。每个神经元的激活值表示对应字符的相应强度, 最大值则为对应的识别结果。
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。每个神经元的激活值表示对应字符的相应强度, 最大值则为对应的识别结果。
最后的Output层也属于全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。
可以看下这篇文章:LeNet-5详解
三、MNIST数据集的特征
1.MNIST训练集的特征
“0”的手写体的训练集的特征: 比较标准,虽然“0”的形状有的有些扭曲,但是大多数“”0都闭合而且大小宽瘦适合。
“1”的手写体的训练集: 涵盖了一些印刷体“1”的写法,可以避免误判为数字“7”,而且有些“1”有旋转角度(<=45度)

“2”的手写体的训练集: “2”多种花式,比较容易和数字“4”和数字“6”混淆
“3”的手写体的训练集: “3”中规中矩,与其他数字有较大的区分度,人眼观察比较不容易误判成其他数字

“4”的手写体的训练集: “4”是两笔写成的数字,在0-9中规范书写来说只有数字“4”和数字“5”是由两笔写成的,相对于其他数字应该更容易区分,但是不排除数据集里存在不少一笔写成的“4”,而且数字“4”也极其容易和数字“9”混淆,虽然很多数字“4”很不像“4”,容易看做字母“H”,但是我们的输出并没有“H”这一个分类,也没有数字和“H”相似。
 “5”的手写体的训练集: “5”和“4”一样是由两笔组成的,但是连贯起来或者一笔写成比较像字母“S”,“S”比较像数字“6”,所以有可能会误判为数字“6”。
“5”的手写体的训练集: “5”和“4”一样是由两笔组成的,但是连贯起来或者一笔写成比较像字母“S”,“S”比较像数字“6”,所以有可能会误判为数字“6”。
 “6”的手写体的训练集: 数字“6”和数字“4”比较容易辨别错误,数据集里一些“6”写的真的很想“4”,属于人眼判断其为数字“4”也说得过去的那种。但是仔细观察,数字“6”的柄明显会比数字“4”的长一些,而且该数据集也包含了很多像数字“4”的数字“6”,起到了训练的效果。而且“4”的手写体训练集里较少很像数字“6”的数字“4”,应该也可以较好的区分“6”和“4”。
“6”的手写体的训练集: 数字“6”和数字“4”比较容易辨别错误,数据集里一些“6”写的真的很想“4”,属于人眼判断其为数字“4”也说得过去的那种。但是仔细观察,数字“6”的柄明显会比数字“4”的长一些,而且该数据集也包含了很多像数字“4”的数字“6”,起到了训练的效果。而且“4”的手写体训练集里较少很像数字“6”的数字“4”,应该也可以较好的区分“6”和“4”。
 “7”的手写体的训练集: 包括了有些人书写“7”习惯加一个横杆的情况,这种写法只要不会太夸张,都不会被认作数字“9”。虽然和“1”相似,但是数字“1”实在太有特点了,不太容易别误判为“1”。
“7”的手写体的训练集: 包括了有些人书写“7”习惯加一个横杆的情况,这种写法只要不会太夸张,都不会被认作数字“9”。虽然和“1”相似,但是数字“1”实在太有特点了,不太容易别误判为“1”。

“8”的手写体的训练集: “8”写的太快常常不闭合,如果不连通的区域太大的话,可能挥别盘坐数字“6”。还有就是“8”存在一些旋转角度,不过再怎么旋转也不容易和其他数字混淆。
 “9”的手写体的训练集: 容易和“0”混淆。就算上面的圈圈不闭合也不容易和“4”混淆,因为“4”是由两笔组成的而“9”只有一笔。
“9”的手写体的训练集: 容易和“0”混淆。就算上面的圈圈不闭合也不容易和“4”混淆,因为“4”是由两笔组成的而“9”只有一笔。

2.MNIST测试集的预测情况
容易误判但是判断正确的图像
数字“0”,结果准确 :数字“0”训练集里存在不闭合的“0”
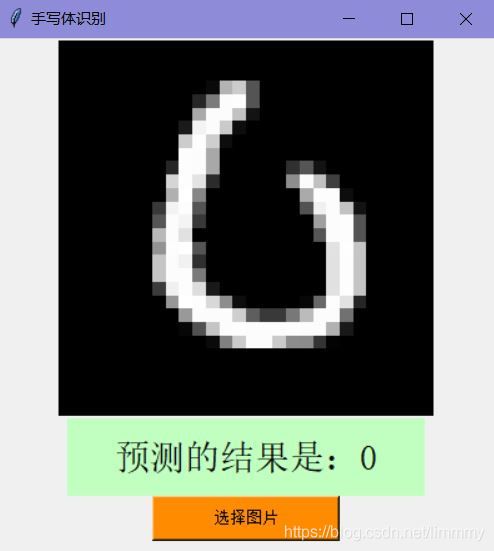
数字“0”,结果准确
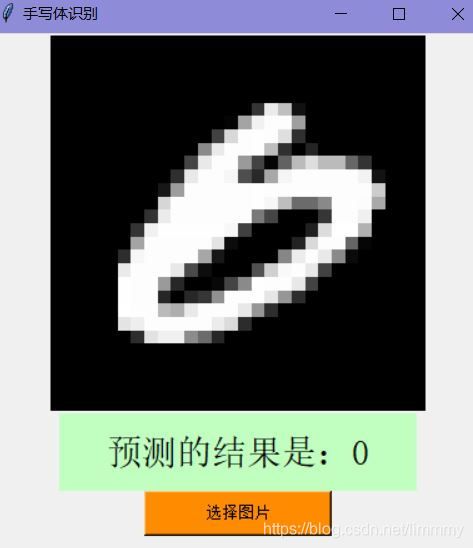
数字“2”,结果准确 数字“2”训练集里存在各式各样的花式“2”

数字“5”,结果准确 虽然这张“5”很扭曲,但是其余数字也没有和它更相近的了
 数字“3”,结果准确 虽然这张“3”很扭曲,但是其余数字也没有和它更相近的了
数字“3”,结果准确 虽然这张“3”很扭曲,但是其余数字也没有和它更相近的了

数字“6”,结果准确 这张测试图是一个很像“4”的“6”,预测准确的原因:
1.“4”和“6”的区别:数字“6”的柄明显会比数字“4”的长一些
2.“数字6”数据集也包含了很多像数字“4”的数字“6”,起到了训练的效果
3.“4”的手写体训练集里较少很像数字“6”的数字“4”,所以这张不一定会被分到“4”
 数字“9”,结果准确 一张像“4”的“9”,因为是一笔画出的数字,还是可以和两笔化成的数字“4”区分开
数字“9”,结果准确 一张像“4”的“9”,因为是一笔画出的数字,还是可以和两笔化成的数字“4”区分开

误判的图像
标签是“4”,误判为:9 “4”的顶部闭合

标签是“4”,误判为:9

标签是“5”,误判为:3

标签是“5”,误判为:8

标签是“7”,误判为:9

标签是“8”,误判为:7
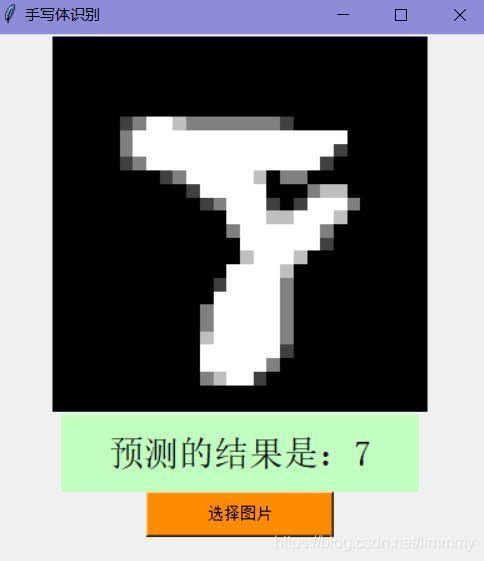 标签是“8”,误判为:7
标签是“8”,误判为:7
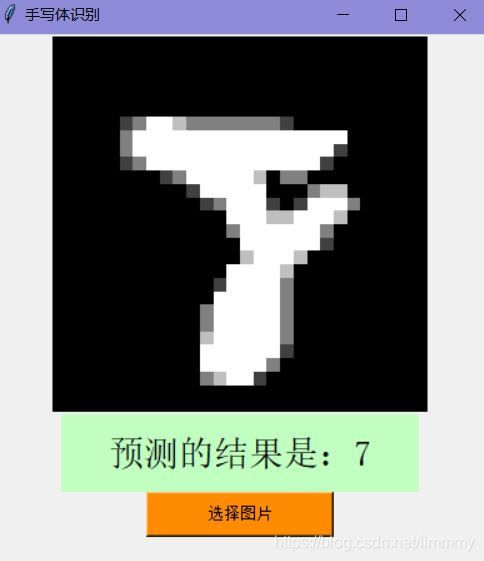
标签是“9”,误判为:0

分析:
1.尽管写的实在是不像原数字,但是和其余的数字更没有任何的相似数字,所以只能别分到正确组。
2.尽管数字“A”和数字“B”相似,但是*训练集“A”中存在一些容易混淆的情况训练了可以较好区分数字“A”和数字“B”的网络
3.尽管数字“A”和数字“B”相似,但是训练集“B”*中的图像都和原数字相似,所以数字“A”不容易被分到“B”类
4.一笔画的数字:1 2 3 6 7 8 9;二笔画的数字:4 5,相似的(9,4)一定程度上可以被区分
5.线条构成的数字:1 4 7;圆弧构成的数字:2 3 6 8 9,相似的(9,4)一定程度上可以被区分
误判的原因:
1.含有圆圈需要闭合的数字9、6和8 ,常常因为没有完全闭合被误判为:4
2.带柄的数字,柄的长度可以作为区分的标准,但是柄的长度并不符合标准
有一个难以解释的预测,数字“8”和数字“7” 数字“5”和数字“8”哪里像了