NoSql概述
- NoSQL = not Only SQL
- 非关系型的数据库
为什么要使用NoSQL
- High performance - 高并发读写
- Huge Storage - 海量数据的高效率存储和访问
- High Scalability && High Availability - 高扩展性和高可用性
NoSQL数据库的四大分类
| 分类 | 相关产品 | 典型应用 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB | 内容缓存,主要用于处理大量数据的高访问负载 | 一些列键值对 | 快速查询 | 缺点存储的数据缺少结构化 |
| 列存储数据库 | Cassandra、HBase、Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存储在一起 | 查询速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文件型数据库 | CouchDB、MongoDb | Web应用(与key-value类似,value是结构化) | 一系列键值对 | 数据结构要求不严格 | 查询性能不高,而且缺乏统一的查询语句 |
| 图形(Graph)数据库 | Neo4J,InfoGrid,Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法 | 需要对整个图做计算才能得出结果,不容易做分布式的集群方案 |
NoSQL的特点
- 易扩展
- 灵活的数据模型
- 大数据量,高性能
- 高可用
Redis概念
Redis的由来
2008年,意大利的一家创业公司Merzia推出了一款基于MySQL的网站实时统计系统 LLOOGG,然而没过多久该公司的创始人 Salvatore Sanfilippo 便对MySQL 的性能感到失望,于是他决定亲自为 LLOOGG 量身定做一个 数据库,并并于 2009 年开发完成,这个数据库就是Redis。不过Salvatore Sanfilippo并不满足只将 Redis 用于LLOOGG这一款产品,而是希望更多的人使用它,于是在同一年 Salvatore Sanfilippo 将 Redis 开源发布,并开始和 Redis 的另一名主要的代码贡献者 Pieter Noordhuis 一起继续着 Redis 的开发,直到今天。SalvatoreSanfilippo自己也没有想到,短短的几年时间,Redis就拥有了庞大的用户群体。Hacker News 在 2012 ,结果显示有近 12% 的公司在使用 Redis。国内如新浪微博、街旁网、知乎网,国外如GitHub、StackOverflow、Flickr等都是Redis的用户。VMware公司从2010年开始赞助 Redis 的开发,Salvatore Sanfilippo和 Pieter Noordhuis也分别在3月和5月加入VMware,全职开发Redis。
高性能键值对数据库,支持的键值数据类型:
- 字符串类型
- 列表类型
- 有序集合类型
- 散列类型
- 集合类型
应用场景
- 缓存
- 任务队列
- 网站访问统计
- 数据过期的处理
- 应用排行榜
- 数据过期处理
- 分布式集群架构中的session分离
Redis 使用
Jedis介绍
- Jedis 是Redis官方首选的Java客户端开发包
- https://github.com/xetorthio/jedis
- 简单使用
package com.icemark.com.icemark.jedis;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* Jedis的测试
* @ author ICEMARK
*/
public class JedisDemo {
/**
* 单实例测试
*/
@Test
public void demo1() {
// 设置连接Redis的IP和端口
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 添加键值对
jedis.set("name", "李红利");
// 从Redis获取值
String name = jedis.get("name");
// 输出
System.out.println(name);
// 释放资源
jedis.close();
}
@Test
public void demo2() {
// 创建连接池对象
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
// 最大连接数
jedisPoolConfig.setMaxTotal(30);
// 最大空闲连接数
jedisPoolConfig.setMaxIdle(30);
// 创建连接池
JedisPool jedisPool = new JedisPool(jedisPoolConfig, "127.0.0.1", 6379);
// 定义jedis
Jedis jedis = null;
try {
// 从线程池中获取jedis对象
jedis = jedisPool.getResource();
// 往Redis中存值
jedis.set("name", "小明");
// 从Redis中取值
String name = jedis.get("name");
// 输出
System.out.println(name);
} catch(Exception e) {
e.printStackTrace();
} finally {
if (jedis != null) {
jedis.close();
}
if (jedisPool != null) {
jedisPool.close();
}
}
}
}
Redis的数据结构
五种数据类型:
- 字符串(String)
- 哈希 (hash)
- 字符串列表(list)
- 字符串集合(set)
- 有序字符串集合(sorted set)
Key定义的注意点:
- 不要过长(最好不要超过1024,也不要太短,这样的话会降低key的可读性)
- 不要过短
- 统一的命名规范
字符串存储
注意点:
- 二进制安全的,存入和获取的数据相同
- Value最多可以容纳的数据长度是512M
存储String的常用命令:
- 赋值
- 取值
- 删除
- 数值增减
- 扩展命令
| 方法 | 作用 | 介绍 | 返回值 |
|---|---|---|---|
| String set(String key, Object value) | 赋值 | 往Redis数据中放字符串 | "OK" |
| Object get(String key) | 取值 | 根据value获取,从Redis中取值 | Redis对应的value |
| Long del(String key) | 删除 | 根据value,删除数据 | 1 |
| Long incr(String key) | 增1 | 如果Redis的key不存在的话,Redis默认会把你调用函数是传递的key添加进去默认值为0,然后加1,最终结果为1,如果存在则 根据key,给整数型的value加1 | 加1后的vlue |
| Long decr(String key) | 减1 | 如果Redis的key不存在的话,Redis默认会把你调用函数是传递的key添加进去默认值为0,然后减1,最终结果为-1,如果存在则 根据key,给整数型的value减1 | 减少后的value |
| Long incrBy(String key, int num) | 增加指定值num | 如果Redis的key不存在的话,Redis默认会把你调用函数是传递的key添加进去默认值为0,然后加num,最终结果为num,如果存在则 根据key,给整数型的value加num | 加num后value |
| Long decrBy(String key, num) | 减少指定num | 如果Redis的key不存在的话,Redis默认会把你调用函数是传递的key添加进去默认值为0,然后减-num,最终结果为-num,如果存在则 根据key,给整数型的value减num | 减num后的value |
| Long append(String value, String str) | 追加 | 根据value,给指定value后面追加str | 追加后的字符串的长度 |
Hash存储
- String key 和 String Value的map容器
- 每一个hash可以存储4294967295个键值对
| 方法 | 作用 | 介绍 | 返回值 |
|---|---|---|---|
| String hset(String key, String field, value) | 添加hash数据 | 往Redis里面添加hash数据 | "OK" |
| String hget(String key, String field) | 获取数据 | 根据value获取,指定字段对应的值 | value |
| String hmset(String value, Map map) | 添加map | 添加一个map的hash数据 | "OK" |
| List hmget(String key, String field1, String field2, ... ) | 获取多个属性 | 根据key和传入的字段,获取多个值 | 返回一个List |
| Long hdel(String key, String field) | 删除某个字段属性 | 根据key,删除某个列表中的某个属性 | 返回删除字段个数 |
| Long del(String key) | 删除hash数据 | 根据key,删除整个hash数据 | 1 |
| Map hgetAll(String key) | 获取hash的所有数据 | 根据key获取所有字段和对应的数据 | Map |
| Set hkeys(String key) | 获取所有字段 | 根据key,获取所有字段 | Set |
| List hvals(String key) | 获取所有字段对应的内容 | 根据key,获取所有字段对应的内容 | List |
| Long hincrBy(String key, String field, int num) | 给某个字段加num | 根据key,给指定字段加num | 加num后的字段对应的值 |
| Long hdel(String key, String... field) | 删除字段对应内容 | 根据key,删除指定字段对应的内容 | 如果有内容不为null返回1, 否则0 |
List存储
- ArrayList使用数组方式
- LinkedList使用双向连接方式
- 双向链表中增加数据
- 双向链表中删除数据
常用的命令:
- 两端添加
- 查看列表
- 两端弹出
- 获取列表元素个数
- 扩展命令
| 方法 | 作用 | 介绍 | 返回值 |
|---|---|---|---|
| Long lpush(String key, String... strings) | 往Redis中放list | 添加列表类型的数据,数据是从尾端插入数据 | 列表中的数据的数量 |
| Long rpush(String key, String... strings) | 往Redis存放list | 添加列表类型的数据,数据是从头端插入数据 | 列表中的数据的数量 |
| List lrange(String key, long start, long end) | 查看列表中的所有数据 | 根据key,查询所有的数据,end 为负数时表示从start到倒数第几个元素 | 返回list |
| Long lrem(String key, long count, String value) | 删除指定元素的个数 | 删除list中指定值得个数, 如果count为正数从数组的开始查找,查找count个值为value的元素并删除,如果count为负数,则从数组的尾部开始查找,查找-count个值为value的元素,并删除。 | 返回删除元素的个数 |
| Long linsert(String key, BinaryClient.LIST_POSITION.AFTER /BinaryClient.LIST_POSITION.BEFORE) | 在指定元素前/后插入元素 | 在指定元素后面插入元素 | |
| String lpoplpush(String key1, String key2) | 把key1中首元素弹出压入key2中首位 | 将key1对应的list中的第一个元素弹出,压入key2对应的list中的首位 | 返回弹出的元素 |
-
rpoplpush的使用场景
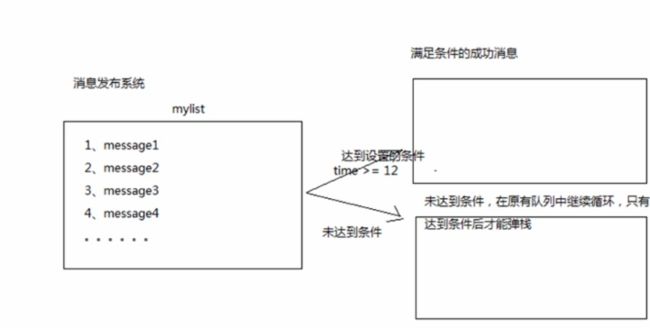 image
image
存储Set
- 和List类型不同的是,Set集合中不允许出现重复的元素
- Set可包含的最大元素数量是4294967295
常用命令: - 添加/删除元素
- 获得集合中的元素
- 集合中的差集运算
- 集合中的交集运算
- 集合中的并集运算
- 扩展命
| 方法 | 作用 | 介绍 | 返回值 |
|---|---|---|---|
| Long sadd(String key, String... vlaue) | 添加集合 | 向Redis中添加集合,如果集合中已经存在元素则添加不成功,返回值为0 | 返回添加集合中元素的个数 |
| Set |
查看集合元素 | 根据key查看对应集合中的所有元素 | 返回Set |
| Long scard(String key) | 查看集合元素的个数 | 根据key查看对应集合元素的数量 | 返回集合元素数量 |
| Long srem(String key, String... members) | 删除指定元素 | 根据key删除对应集合的指定元素 | 返回删除元素的数量 |
| Set |
获取两个集合的差集 | 差集的结果和key的先后有关系,比如key1为第一个参数则交集结果key2中没有key1中的元素 | 返回Set |
| Set |
获取两个集合的并集 | 获取两个元素的交集 | 返回Set |
| Boolean sismember(String key, String value) | 判断集合中是否包含某元素 | 查看结合中是否包含指定元素 | 返回Boolean |
| Set |
交集 | 求多个集合的交集 | 返回Set |
| String srandmember(String key) | 随机获取元素 | 根据key,随机获取集合中的一个元素 | 返回值String类型 |
| Long sunionstore(String deskey, String... key) | 将多个集合的并集存储到一个新集合中 | 将多个集合的并集存储到一个新的结合中 | 返回存储的个数 |
| Long sinterstore(String deskey, String... key) | 将多个集合的交集存储到一个新集合中 | 将多个集合的存储到一个新的结合中 | 返回存储的个数 |
| Long sdiffstore(String deskey, String... key) | 将多个集合的交集存储到一个新集合中 | 将多个集合的并集存储到一个新的结合中 | 返回存储的个数 |
redis:0>sadd myset 1 2 3
"3"
redis:0>scard myset
"3"
redis:0>sadd myset a b c
"3"
redis:0>scard myset
"6"
redis:0>sadd myset 2
"0"
redis:0>srem myset a
"1"
redis:0>scard myset
"5"
redis:0>smembers myset
1) "2"
2) "b"
3) "1"
4) "3"
5) "c"
redis:0>sadd mya1 a b c
"3"
redis:0>sadd myb1 a c 1 2 3
"5"
redis:0>sdiff mya1 myb1
1) "b"
redis:0>sdiff myb1 mya1
1) "1"
2) "2"
3) "3"
redis:0>sunion mya1 myb1
1) "c"
2) "b"
3) "2"
4) "3"
5) "1"
6) "a"
redis:0>sismember mya1 b
"1"
redis:0>sismember mya1 x
"0
redis:0>sinter mya1 myb1
1) "a"
2) "c"
redis:0>srandmember mya1\
"c"
redis:0>srandmember mya1
"a"
redis:0>sinterstore myinter mya1 myb1
"5"
- 使用场景
- 跟踪一些唯一性数据
- 用于维护数据对象之间的关联关系
存储Sorted-Set
- Sorted-Set和Set的区别
Redis 可以根据sort来给set排序,所以Sorted—Set存储的数据是有序的
- Sorted-Set中的成员在集合中的位置是有序的
常用命令
- 添加元素
- 获得元素
- 删除元素
- 范围查询
- 扩展命令
| 方法 | 作用 | 介绍 | 返回值 | |
|---|---|---|---|---|
| Long zadd(String key, double score, String value) | 添加分数集合 | 添加分数集合,如果再次添加已经存在的元素,如果分数不同,只更新分数,不更新元素值,返回值为0 | 返回类型添加集合的元素数量 | 返回元素数量 |
| Long zcard(String key) | 获取元素的数量 | 根据key获取元素的数量 | 返回元素数量 | |
| Long zrem(String key, String... members) | 删除元素 | 删除指定多个元素 | 返回值为删除元素数量 | |
| Set |
获取所有元素 | 根据key,获取指定元素的数量 | 返回Set | |
| Set |
获取分和元素 | 获取集合中的指定分和元素,根据分数从小到大排序 | 返回Set |
|
| Set |
获取分和元素 | 获取集合中的指定分和元素,根据分数从大到小排序 | 返回Set |
|
| Long zremrangeByRank(String key, long start, long end) | 删除元素 | 删除集合中前四个元素 | 返回删除个数 | |
| Long zremrangeByScore(String key, double mix, double max) | 删除指定范围元素 | 根据分的范围来删除在start< score < end 范围内的元素 | 返回删除元素的个数 | |
| Set |
获取指定范围的元素 | 根据分的范围来获取在mix< score < max范围内的元素 | 返回Set |
|
| Double zincrby(String key, double score, member) | 各指定元素分加指定值 | 给集合中指定元素对应的分加指定值 | 返回加值后的值 | |
| long zcount(String key, double mix, double max) | 统计指定范围中元素的个数 | 统计在分范围mix< score < max 范围内的元素的个数 | 返回元素数量 |
- 使用场景
- 如大型在线游戏积分排行榜
- 构建索引数据
key的常用操作
| 方法 | 作用 | 介绍 | 返回值 |
|---|---|---|---|
| Set |
获取keys | 获取keys,当parttern为星号,时表示获取所有的key, 匹配所有my开头的key,传入参数为"my" + 星号, | Set |
| long del(String... keys) | 删除key | 删除指定多个key | 返回删除的数量 |
| String type(String key) | 查看可以对应的值的类型 | 查看指定key对应的类型 | 返回String |
| boolean exists(String key) | 指定key是否存在 | 查看redis中是否存在指定的key,如果存在返回true,如果不存在返回false | boolean |
| String rename(String oldName, String newName) | 给key重命名 | 给指定key重命名 | 返回"OK" |
| boolean expire(String key, long time) | 给key设置有效时间 | 给指定key设置有效时间, 如果有该key,返回true,如果没有返回false | |
| long ttl(String key) | 查看有效时间 | 查看指定key的有效时间 | long |
| String flushDB() | 清空数据库 | 清空redis中的所有数据 | String |
Redis特性
- 多数据库
- Redis事务
多数据库
Redis默认提供了15个数据库,默认使用第一个数据库
| 方法 | 作用 | 介绍 | 返回值 |
|---|---|---|---|
| String select(int index) | 选择指定数据库 | 选择第几个数据库 | 返回“OK” |
| long move(String key, int index) | 当前数据库中的一条移动到另一个数据库中 | 将当前数据库中一条移动到指定数据库中 | 返回移动的数量 |
事务
| 方法 | 作用 | 介绍 | 返回值 |
|---|---|---|---|
| Transaction mutli() | 开启事务 | 开启事务,返回一个事务,用这个事务调用exec()表示提交事务 | 返回一个事务 |
回滚
首先调用mutli()开启事务,然后进行操作,如果不想要这些操作,想回到之前的状态调用discard()方法
Redis的持久化
redis 的高性能是由于所有数据存储在内存中
Redis 的持久化其实就是将内存的数据存储在硬盘上面
持久化的两种方式
- RDB方式
- AOF方式
RDB持久化
指的是在指定时间内将内存中的数据进行快照写入到磁盘
优点:
- redis数据库将会只包含一个文件,比如,要求一个小时归档最近24小时数据,并且还要一天归档最近30天的数据。一旦服务器出现故障,我们非常容易地进行恢复
- 对于灾难恢复而言,RDB是非常不错的选择,因为我们很轻松地将一个单独的文件压缩后,再将它转移到其他存储介质上,到时候恢复的时候再给他拿回来。
- 性能最大化,在开始持久化的时候,唯一要做的只是分叉出进程,之后再由子进程完成持久化的工作,这样就可以极大的避免服务器进程执行I/O操作,相对于AOF持久化来说,RDB启动服务器的效率更高
缺点: - 如果你想保证数据的高可用性、最大限度避免数据的丢失,而它不是很好的选择,因为系统一定在定时持久化之前出现宕机情况,还没有来的及往硬盘上写,数据就丢失了。
配置:
文件配置
配置文件介绍


AOF持久化
将以日志的方式记录服务器所处理的每步操作,Redis启动之初它读取该文件,来重新构建我们的数据库,来保证我们的数据库是完整的
优势:
- 这种方式可以带来更高的安全性,Redis提供了三种同步方式
- 每秒同步:是异步完成的效率也是比较高的,差的是一旦系统宕机了,这一秒的数据会丢失
- 每修改同步:可以理解为同步持久化,每次修改都会立即记录到磁盘当中
- 不同步
- 由于这种机制对于日志文件的写入操作采用的是append模式,就是添加的方式,因此在写入过程中,即使系统出现宕机现象也不会破坏我们日志中已经存在的内容,如果本次操作只写入一半数据,就出现了系统崩溃的问题,也不用担心,在Redis下一次启动之前,可以通过redis-check-aof这个工具,来帮助解决数据一致性的问题
- 如果日志过大,Redis可以自动启动重写日志机制,redis不断通过append不断将新修改的数据添加到老的磁盘当中,同时redis还创建了新的文件,用于记录此期间产生哪些修改命令被执行了,因此在重启切换的时候可以更好的去保证数据的安全性
- AOF包含一个非常清晰易于理解的日志文件,用于记录所有的修改操作,这个文件来完成数据的重建
劣势
- 对于相同的数据集而言AOF这个文件比RDB文件要大一些
- 根据同步策略的不同,在运行效率上往往要低于RDB
配置:

我们的所有数据操作日志都保存在appendonly.aof中,只要我们更改其中内容,就可以想得到我们的数据了,服务器再次启动的时候回读取该文件
无持久化
可以通过配置,使得Redis不持久化,这样Redis就是一个缓存机机制把上面配置中的的RDB模式和AOF模式全部屏蔽掉,就是无持久化.