(AWSRN arxiv2019)轻量化。Lightweight Image Super-Resolution with Adaptive Weighted Learning Network
文章链接:https://arxiv.org/abs/1904.02358
一、简介
These SR networks generally suffer from the problem of a heavy burden on computational resources with large model sizes which limits their wide real-world applications
越深的模型往往可以产生更好的效果,但是模型太大会导致消耗过多的计算资源,从而限制了其在实际生活中的广泛使用。所以设计轻量化的SISR模型最近得到了广泛的关注。
减少模型参数的两种方法:1、构造更浅层的网络 2、递归的共享参数
However, the numbers of computational operations (Multi-Adds) of these networks are still very large [9].
网络的加法数量太大,也会影响性能。
二、相关工作
Squeeze-and-Excitation 会产生额外的参数和计算开销,所以本文设计了不需要额外模块而自动计算参数的单元。
三、方法
整体结构:
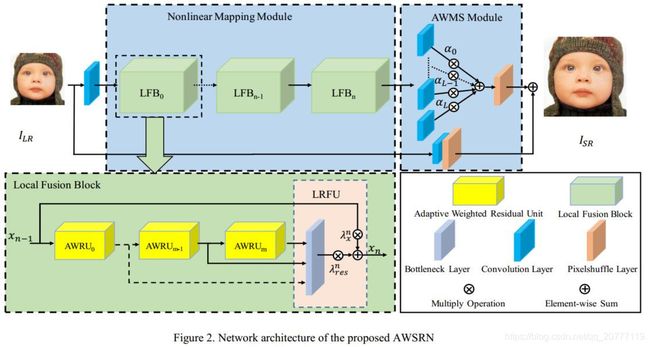

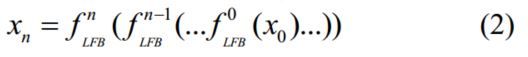
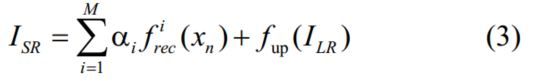
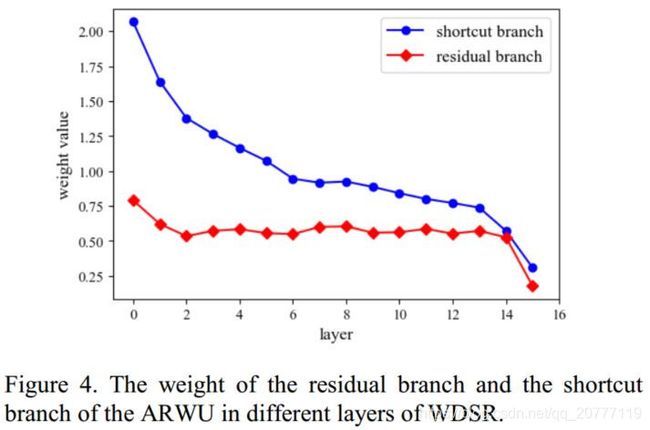
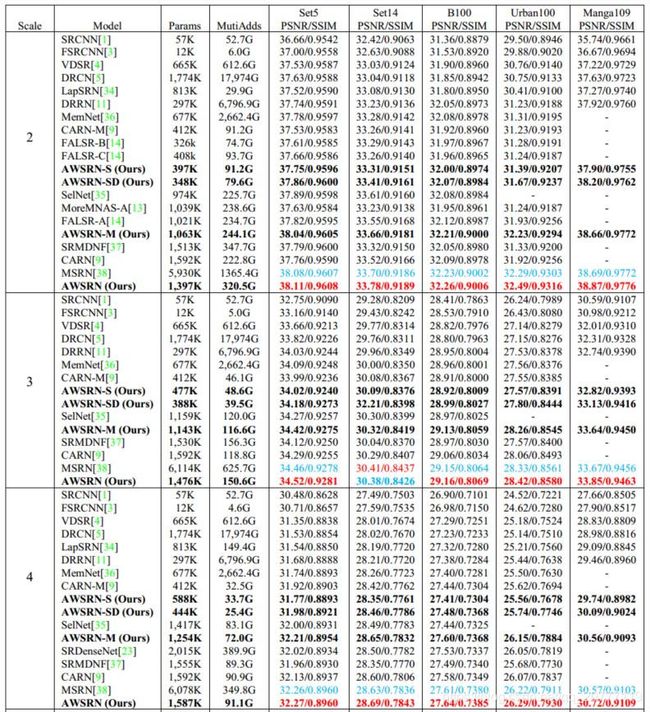
最终的SR是由公式(3)得出。多尺度重建模块乘以相对应的参数,我就好奇他是怎么个自适应法
#LFB模块的代码,同样,所为的自适应参数部分设置为常数1
class LFB(nn.Module):
def __init__(
self, n_feats, kernel_size, block_feats, wn, act=nn.ReLU(True)):
super(LFB, self).__init__()
self.b0 = AWRU(n_feats, kernel_size, block_feats, wn=wn, act=act)
self.b1 = AWRU(n_feats, kernel_size, block_feats, wn=wn, act=act)
self.b2 = AWRU(n_feats, kernel_size, block_feats, wn=wn, act=act)
self.b3 = AWRU(n_feats, kernel_size, block_feats, wn=wn, act=act)
self.reduction = wn(nn.Conv2d(n_feats*4, n_feats, 3, padding=3//2))
self.res_scale = Scale(1)#自适应参数部分初始化设置为常数1,然后通过nn.parameter来自动更新
self.x_scale = Scale(1)
def forward(self, x):
x0 = self.b0(x)
x1 = self.b1(x0)
x2 = self.b2(x1)
x3 = self.b3(x2)
res = self.reduction(torch.cat([x0, x1, x2, x3],dim=1))
return self.res_scale(res) + self.x_scale(x)
#AWMS模块
class AWMS(nn.Module):
def __init__(
self, args, scale, n_feats, kernel_size, wn):
super(AWMS, self).__init__()
out_feats = scale*scale*args.n_colors
self.tail_k3 = wn(nn.Conv2d(n_feats, out_feats, 3, padding=3//2, dilation=1))
self.tail_k5 = wn(nn.Conv2d(n_feats, out_feats, 5, padding=5//2, dilation=1))
self.tail_k7 = wn(nn.Conv2d(n_feats, out_feats, 7, padding=7//2, dilation=1))
self.tail_k9 = wn(nn.Conv2d(n_feats, out_feats, 9, padding=9//2, dilation=1))
self.pixelshuffle = nn.PixelShuffle(scale)
self.scale_k3 = Scale(0.25)##
self.scale_k5 = Scale(0.25)#
self.scale_k7 = Scale(0.25)##
self.scale_k9 = Scale(0.25)##
def forward(self, x):
x0 = self.pixelshuffle(self.scale_k3(self.tail_k3(x)))
x1 = self.pixelshuffle(self.scale_k5(self.tail_k5(x)))
x2 = self.pixelshuffle(self.scale_k7(self.tail_k7(x)))
x3 = self.pixelshuffle(self.scale_k9(self.tail_k9(x)))
return x0+x1+x2+x3自适应参数部分参数初始化设置为0.25,然后通过nn.parameter来自动更新。
AWRU模块:
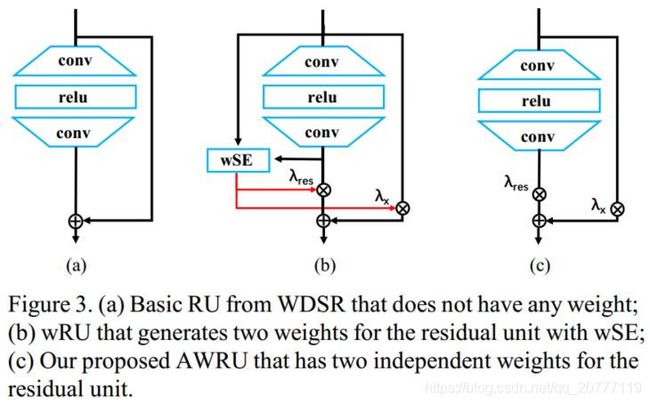
class Scale(nn.Module):
def __init__(self, init_value=1e-3):
super().__init__()
self.scale = nn.Parameter(torch.FloatTensor([init_value]))
def forward(self, input):
return input * self.scale
class AWRU(nn.Module):
def __init__(
self, n_feats, kernel_size, block_feats, wn, res_scale=1, act=nn.ReLU(True)):
super(AWRU, self).__init__()
self.res_scale = Scale(1)#不是说好自适应参数吗,为啥这里设置为1
self.x_scale = Scale(1)
body = []
body.append(
wn(nn.Conv2d(n_feats, block_feats, kernel_size, padding=kernel_size//2)))
body.append(act)
body.append(
wn(nn.Conv2d(block_feats, n_feats, kernel_size, padding=kernel_size//2)))
self.body = nn.Sequential(*body)
def forward(self, x):
res = self.res_scale(self.body(x)) + self.x_scale(x)
return res
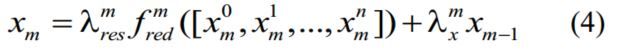
每个AWRU模块:
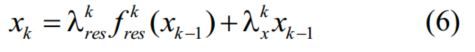
四、实验
训练集:DIV2K,Y通道
AWUR模块的初始自适应参数设置为1。每个LFB中包含4个AWUR
对于AWMS模块,设置四个尺度的,卷积核大小分别为3,5,7,9。并且将初始参数设置为0.2