python利用pandas库求数据日期的差
1、问题描述:有两个文件,一个文件是会员注册信息。包含会员注册卡号、会员的出生年月、性别(0表示女士、1表示男士)、会员入会登记时间。另一个文件是消费记录。包含会员卡号、会员消费产生的时间、商品编码、销售数量、商品售价、消费金额、商品名称、此次消费的会员积分、 收银机号、单据号(相同的单据号可能不是同一笔消费产生)、柜组编码、柜组名称。现在要得到仅在16年注册的会员,到第一次消费所花的时间。数据格式如底部!
下载两个Excel文件数据的地址!
2、问题分析:注册文件中包含近20万条信息,并不是每条信息都完整。只要注册卡号和注册时间存在都做处理。消费文件中包含近100万条,要是消费时间缺失,时间差记为无穷大(用‘inf’表示)。所以需要考虑信息缺失的问题!
3、代码如下:
import pandas as pd
excel_ori = pd.read_excel(io = 'vip_table.xlsx') #读入会员注册信息
vip = excel_ori.values #除了第一行(列名)外以数组的形式返回数据
excel_ori = pd.read_excel(io = 'consume_table.xlsx') #读入会员消费信息
consume = excel_ori.values
ret = [] #存储结果
t1 = '2016-01-01 00:00:00'
t2 = '2017-01-01 00:00:00'
for s in vip:
tmp_l = []
if not pd.isnull(s[3]) and (t1 <= str(s[3]).split('.')[0] < t2): #注册时间不为空,仅处理在16年注册的数据
tmp_t = []
for c_s in consume: #在消费信息文件中找到卡号为s[0]这个会员的消费记录
if s[0] == c_s[0]:
tmp_t.append(c_s)
if tmp_t: #只处理有消费记录的会员数据
tmp_t_sort = sorted(tmp_t, key=lambda x: x[1]) #消费记录按消费时间排序
tmp_l.append(s[0])
tmp_l.append(s[3])
if not pd.isnull(tmp_t_sort[0][1]): #最早消费记录的消费时间不为空
tmp_l.append(tmp_t_sort[0][1])
#有些会员的第一次消费时间比注册时间还早,去掉这些数据(出现这种情况估计是数据有问题)
if tmp_l[2] >= tmp_l[1]:
tmp_l.append(str(tmp_l[2] - tmp_l[1]).split('.')[0].split()[0]) #精确到天。不足一天,为零
else:
tmp_l.append('')
tmp_l.append('inf')
if len(tmp_l) == 4:
print("%s %s %s %s" % (tmp_l[0], tmp_l[1], tmp_l[2], tmp_l[3]))
ret.append(tmp_l)
if ret:
ret_df = pd.DataFrame(ret)
ret_df.columns = ['卡号', '会员登记时间', '第一次消费时间', '时间差']
writer = pd.ExcelWriter('ret.xlsx')
ret_df.to_excel(writer, 'page_1', index=False)
writer.save()
else:
print("ret is null!")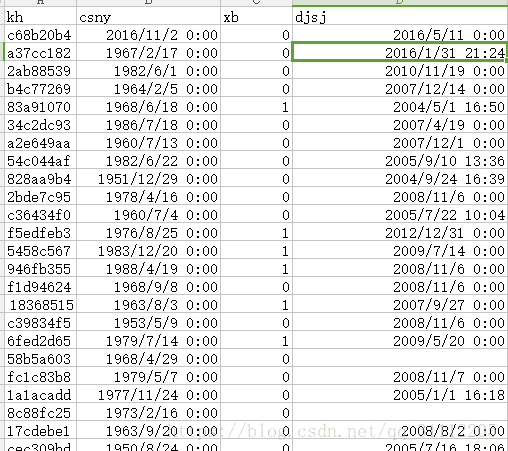 注册信息
注册信息
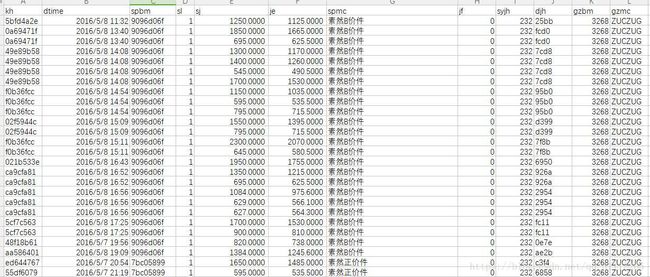 消费记录
消费记录
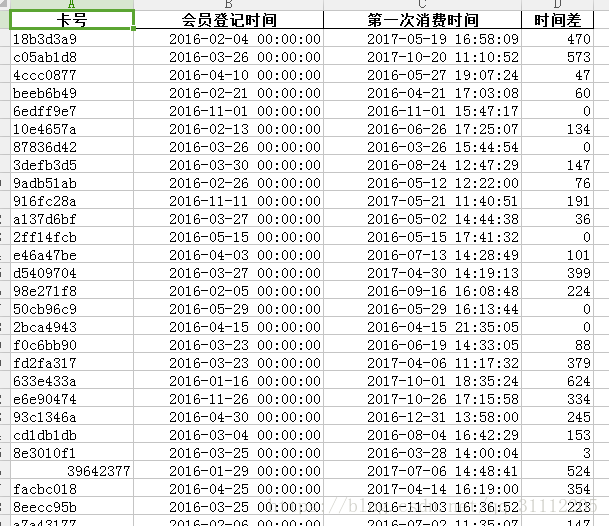 最后的结果部分截图
最后的结果部分截图