nutch分布式爬虫单击爬取教程完整版
nutch分布式爬虫单击爬取教程完整版
目录
一、环境
二、安装目录
三、爬取网站
四、爬取步骤
1. 创建新的虚拟机
2. 配置Nutch
3 . 分步爬取 (bin/nutch)
4. 安装solr-6.6.5
5. 一站式爬取(bin/crawl)
五、参考
一、环境
VMware Workstation15.5
Ubuntu16.04
JDK1.8.0_241
apache-nutch-1.14
solr-6.6.5
其他:vim,ant-1.10.5 sonar-task-2.2.jar
二、安装目录
/opt
三、爬取网站
https://news.sohu.com
https://blog.csdn.net/
https://int.bupt.edu.cn/
四、爬取步骤
- 创建新的虚拟机
VMware Workstation15.5 Ubuntu16.04 - 配置Nutch
(1)安装JDK
1)下载JDK:http://www.oracle.com/technetwork/java/javase/downloads/index.html
2)本教程下载的是jdk-8u45-linux-x64.tar.gz
3)解压JDK包:
saisai@ubuntu:/opt$ sudo tar zxvf jdk-8u241-linux-x64.tar.gz
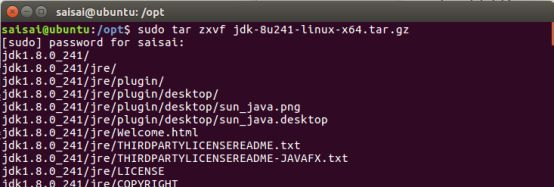
4)配置环境变量:saisai@ubuntu:/opt$ sudo vim /etc/profile
执行该命令发现报错,无vim
安装vim:
saisai@ubuntu:/opt$ sudo apt install vim

再次执行
saisai@ubuntu:/opt$ sudo vim /etc/profile
在最底部输入:(敲击i为输入,输入完后,敲Esc键,输入:wq,即可保存退出)
export JAVA_HOME=/opt/jdk1.8.0_241
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
使其生效:
saisai@ubuntu:/opt$source /etc/profile
5)查看版本:
saisai@ubuntu:/opt$java -version

JDK安装完成
(2)安装Ant
1)到网站下载Ant:http://ant.apache.org/bindownload.cgi
本教程下载的为apache-ant-1.10.5-bin.zip
解压:
saisai@ubuntu:/opt$ sudo unzip apache-ant-1.10.5-bin.zip
2)设置环境变量:
saisai@ubuntu:/opt$ sudo vim /etc/profile
export ANT_HOME=/opt/apache-ant-1.10.5
export PATH=$PATH:$ANT_HOME/bin
注:环境变量要手敲,直接复制粘贴因为编码问题可能会报如下错误:
![]()
3)查看版本:
saisai@ubuntu:/opt$ ant -version
![]()
(3)构建nutch编译环境
1)下载nutch: http://nutch.apache.org/downloads.html
版本:apache-nutch-1.14-src.zip
解压:
saisai@ubuntu:/opt$ sudo unzip apache-nutch-1.14-src.zip
2)配置http.agent.name属性,打开conf/nutch-default.xml,复制其中的http.agent.name属性,到conf/nutch-site.xml中,结果如下
![]()

3)Nutch已配置好。
编译源码:
saisai@ubuntu:/opt/apache-nutch-1.14$ ant
Note:执行这条命令会出现的错误:
1)Trying to override old definition of task javac
[taskdef] Could not load definitions from resource org/sonar/ant/antlib.xml. It could not be found.
ivy-probe-antlib:
ivy-download:
[taskdef] Could not load definitions from resource org/sonar/ant/antlib.xml. It could not be found.

解决办法:
下载sonar-ant-task-2.2.jar
移动到/opt/apache-nutch-1.14/lib下:
saisai@ubuntu:/opt$ sudo mv sonar-ant-task-2.2.jar /opt/apache-nutch-1.14/lib
打开apache-nutch-1.14/build.xml,修改为如下内容(大约在956行):

2)出现如下错误:
BUILD FAILED
/opt/apache-nutch-1.14/build.xml:71: Directory /opt/apache-nutch-1.14/build creation was not successful for an unknown reason
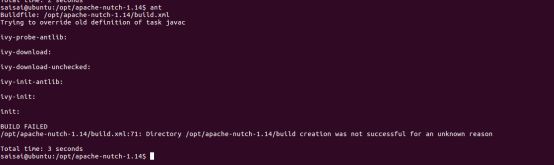
解决方法:
切换到root
切换完后查看ant -version,发现没安装,再执行一次source /etc/profile即可
重新编译ant

验证nutch安装(bin/nutch) 在(/opt/apache-nutch-1.14/runtime/local)下执行命令
3)卡住不动

解决办法:
这里耗时较久,先耐心等待,10分钟左右
若长时间无反应,可按Ctrl+C,
然后清除上次编译结果,重新编译:root@ubuntu:/opt/apache-nutch-1.14# ant clean
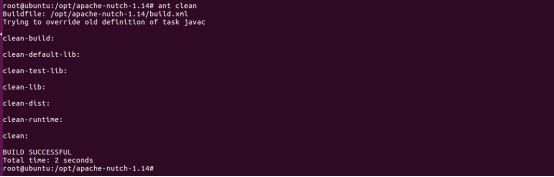
4)报如下错误:
BUILD FAILED
/opt/apache-nutch-1.14/build.xml:522: impossible to resolve dependencies:
resolve failed - see output for details
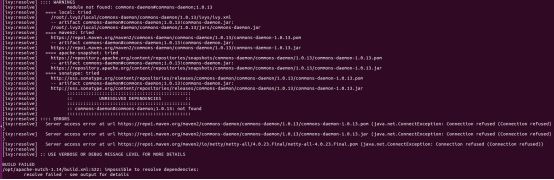
解决方法:
打开/ivy/ivysettings.xml,修改下图划线处,将http改为https即可
root@ubuntu:/opt/apache-nutch-1.14# sudo vim ivy/ivysettings.xml

构建成功

(4)验证Nutch安装
编译完成后/opt/apache-nutch-1.14下会多出一个文件夹runtime,里面有两个文件夹deploy local

进入/opt/apache-nutch-1.14/runtime/local运行命令:
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch
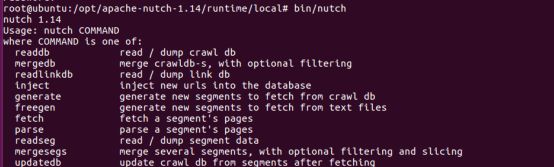
3 . 分步爬取 (bin/nutch)
以下操作 在(/opt/apache-nutch-1.14/runtime/local)下执行
(1)配置爬取属性
该步骤在2.(3)已完成
(2)配置URL种子列表
1)创建URL种子列表
在/opt/apache-nutch-1.14/runtime/local下创建文件夹urls:
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# mkdir -p urls
![]()
在/opt/apache-nutch-1.14/runtime/local/urls下创建文件seed.txt:
root@ubuntu:/opt/apache-nutch-1.14/runtime/local/urls# touch seed.txt
在seed.txt输入以下网站:
root@ubuntu:/opt/apache-nutch-1.14/runtime/local/urls# sudo vim seed.txt
https://news.sohu.com
https://blog.csdn.net/
https://int.bupt.edu.cn/
2)配置正则表达式过滤器
编辑文件/opt/apache-nutch-1.14/runtime/local/conf/regex-urlfilter
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# sudo vim conf/regex-urlfilter.txt
注释掉如下的正则表达式:
# accept anything else
# +.
添加如下正则表达式:
+^https?/news.sohu.com/
+^https?/blog.csdn.net/
+^https?/int.bupt.edu.cn/
(3)分步爬取:准备
1)引导注入
准备好URL种子列表之后,可以进行nutch爬取的引导注入
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch inject
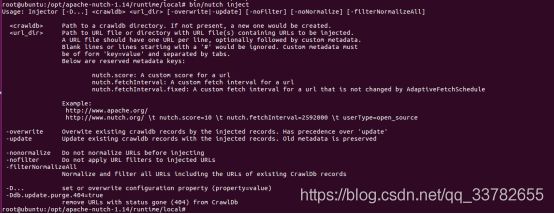
2)执行URL种子注入
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch inject crawl/crawldb urls

3)验证注入结果
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#ll crawl
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#ll crawl/crawldb/
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#ll crawl/crawldb/current/
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#ll crawl/crawldb/current/part-r-00000/
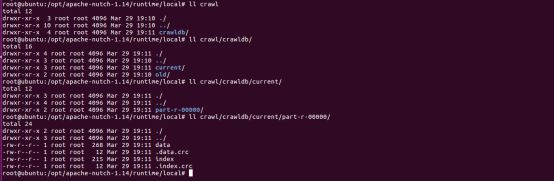
4)验证数据库中的数据
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#bin/nutch readdb crawl/crawldb -dump crawldb-dump
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#ll crawldb-dump/

root@ubuntu:/opt/apache-nutch-1.14/runtime/local#cat crawldb-dump/part-00000
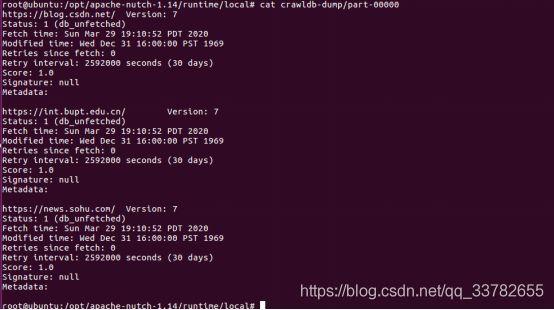
3个初始种子URL存在于数据库中
(4)分步爬取:三次抓取
第一次抓取
1)生成抓取列表
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#bin/nutch generate crawl/crawldb crawl/segments
查看段目录:
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#ll crawl
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#ll crawl/segments/
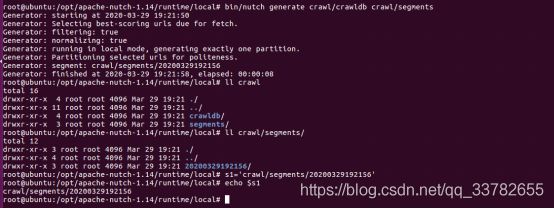
2)为所有要抓取的页面生成了一个抓取列表。抓取列表位于新创建的段目录(segment directory)内。段目录是按创建时间命名的,将这个段名保存到 shell 变量 s1 中,以方便后续使用:
由上图可看出,段目录为20200329192156
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#s1=‘crawl/segments/20200329192156’
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#echo $s1
![]()
3)执行抓取任务
将环境变量中存储的段名作为参数传递给 fetch 命令
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch fetch $s1

4)执行解析任务
抓取到的页面需要进行解析才能存储到数据库中
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch parse $s1

3个抓取到的页面解析完成
5)更新crawldb数据库
将抓取到的结果更新到crawldb数据库
将 crawldb 目录和段名作为参数传递给 updatedb 命令
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch updatedb crawl/crawldb $s1

更新完成,现在 crawldb 数据库中含有所有最初的种子 URL 列表页面更新后的信息,以及从初始 URL 页面中新发现的链接信息。
6)readdb命令简单查看数据库中的内容
通过readdb 命令简单查看下数据库中的内容(如果使用已存在的目录作为输出目录,需要先将其删除,否则报错
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# rm -rf crawldb-dump/
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch readdb crawl/crawldb crawldb-dump
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#ll crawldb-dump/
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#cat crawldb-dump/
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#cat crawldb-dump/part-00000
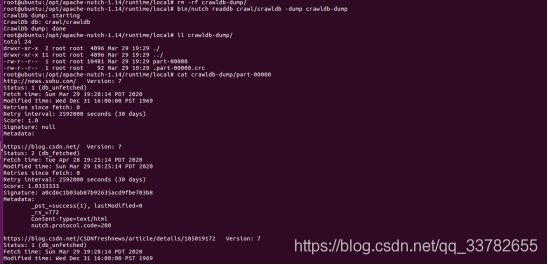
7)使用readdb的-stats选项查看数据库的统计信息
root@ubuntu:/opt/apache-nutch-1.14/runtime/local#bin/nutch readdb crawl/crawldb -stats

可以查看到crawldb中有37个URL,其中有3个状态为status 2(db_fetched),即最初的种子列表中的3个URL已抓取完毕。
第二次抓取
第一次抓取结束后,查看数据库的状态信息,发现有34个URL未完成抓取,再次执行抓取过程。抓取前1000的页面。
1)生成抓取列表,保存变量s2
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch generate crawl/crawldb crawl/segments -topN 1000
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# s2=‘crawl/segments/20200329193329’
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# echo $s2

2)执行抓取
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch fetch $s2
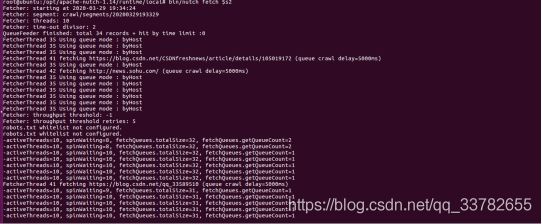
3)执行解析
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch parse $s2

4)更新数据库
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch updatedb crawl/crawldb $s2

5)查看数据库状态
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch readdb crawl/crawldb -stats
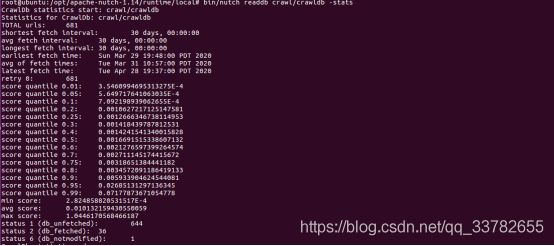
抓取了36个URL,1个处于status 3状态,再次抓取
第三次抓取
1)生成抓取列表,保存变量s3
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch generate crawl/crawldb crawl/segments -topN 1000
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# ll crawl/segments/
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# s3=‘crawl/segments/20200329194159’
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# echo $s3

2)执行抓取
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch fetch $s3
3)执行解析
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch parse $s3
4)更新数据库
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch updatedb crawl/crawldb KaTeX parse error: Expected 'EOF', got '#' at position 68: …4/runtime/local#̲ bin/nutch read…s2,更新数据库即可
反转结果:

(7)分步爬取:为Apache Solr建立索引
在执行这一步之前,应安装好solr,安装solr放在4. 安装solr-6.6.5
使用index命令为Apache Solr建立索引
建立索引: 将 Solr server URL 以 Java 参数 -D key=value 的形式传递给 index 命令:
-Dsolr.server.url=http://localhost:8983/solr/nutch
执行命令: root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch index -Dsolr.server.url=http://localhost:8983/solr/nutch crawl/crawldb -linkdb \ crawl/linkdb -dir crawl/segments/ -filter -normalize -deleteGone
(以上是一条命令,注意空格)
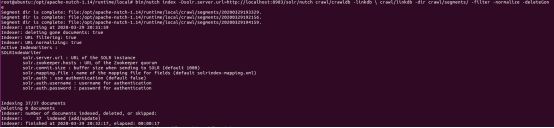
(8)执行搜索
索引建立完成后,可通过如下链接在浏览器中进行搜素
http://localhost:8983/solr/#/nutch/query
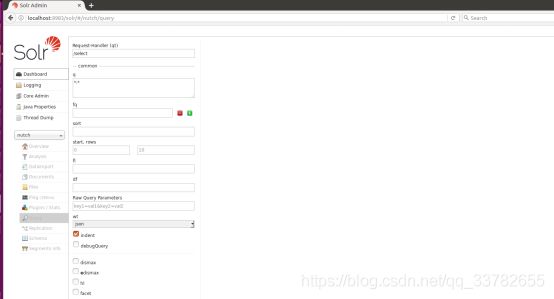
点击下面的执行查询按钮:


5)清理solr
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch clean crawl/crawldb -Dsolr.server.url=http://localhost:8983/solr/nutch
- 安装solr-6.6.5
1)下载:http://archive.apache.org/dist/lucene/solr/
下载版本:solr-6.6.5.tgz
2)解压 :saisai@ubuntu:/opt$ sudo tar zxvf solr-6.6.5.tgz
3)建立符号链接saisai@ubuntu:/opt$ sudo ln -s solr-6.6.5 solr

4)配置环境变量
saisai@ubuntu:/opt$ cd solr
saisai@ubuntu:/opt/solr$ sudo vim /etc/profile
配置如下:
export SOLR_INSTALL=/opt/solr
export PATH= S O L R I N S T A L L / b i n : SOLR_INSTALL/bin: SOLRINSTALL/bin:PATH
保存配置:saisai@ubuntu:/opt/solr$ source /etc/profile
5)查看
saisai@ubuntu:/opt/solr$ solr -version

6)为一个新nutch solr core创建资源
saisai@ubuntu:/opt/solr/server/solr/configsets/
saisai@ubuntu:/opt/solr/server/solr/configsets$ sudo cp -r basic_configs nutch
7)复制nutch schema.xml 到 S O L R I N S T A L L / s e r v e r / s o l r / c o n f i g s e t s / n u t c h / c o n f 目 录 中 s a i s a i @ u b u n t u : / o p t / s o l r / s e r v e r / s o l r / c o n f i g s e t s {SOLR_INSTALL}/server/solr/configsets/nutch/conf 目录中 saisai@ubuntu:/opt/solr/server/solr/configsets SOLRINSTALL/server/solr/configsets/nutch/conf目录中saisai@ubuntu:/opt/solr/server/solr/configsets sudo cp /opt/apache-nutch-1.14/conf/schema.xml $SOLR_INSTALL/server/solr/configsets/nutch/conf

8)确保 S O L R I N S T A L L / s e r v e r / s o l r / c o n f i g s e t s / n u t c h / c o n f / 目 录 内 没 有 m a n a g e d − s c h e m a 文 件 : s a i s a i @ u b u n t u : / o p t / s o l r / s e r v e r / s o l r / c o n f i g s e t s SOLR_INSTALL/server/solr/configsets/nutch/conf/ 目录内没有 managed-schema 文件: saisai@ubuntu:/opt/solr/server/solr/configsets SOLRINSTALL/server/solr/configsets/nutch/conf/目录内没有managed−schema文件:saisai@ubuntu:/opt/solr/server/solr/configsets sudo rm $SOLR_INSTALL/server/solr/configsets/nutch/conf/managed-schema
移除后再次查看:

managed-schema 文件已被移除
9)启动solr服务器
saisai@ubuntu:/opt/solr$ solr start
执行命令后报如下错误:
Exception in thread “main” java.nio.file.AccessDeniedException: /opt/solr/server/logs

解决办法:
转到root模式 :saisai@ubuntu:/opt/solr$ su
再次执行:
![]()
成功启动
10)创建nutch core
root@ubuntu:/opt/solr# bin/solr create -c nutch -d server/solr/configsets/nutch/conf/ -force

11)验证
打开浏览器,通过如下链接访问 Solr:
http://localhost:8983/solr/#/

5. 一站式爬取(bin/crawl)
crawl 脚本集成了分步执行的各个步骤,在一个可执行脚本中执行各步骤的命令。
即在爬取过程中反复执行如下过程:
inject->generate->fetch->parse->updatedb
对于非全网的小规模爬取,完全可以使用 crawl 命令完成整个任务。
(1)查看命令
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/crawl

最后一个参数 迭代次数是一个数字,用于指定执行爬取过程的迭代次数。数字越大执行爬取过程次数越多,抓取 URL页面也就越多,抓取深度和广度更加庞大,耗费的资源和时间呈几何数量增长。
因此在测试环境中不宜设得过大,2~3 次就可以了。
(2)准备测试环境
为了有一个干净的测试环境,指定新的 testcrawl 目录。
root@ubuntu:/opt# cd solr/server/solr/configsets
root@ubuntu:/opt/solr/server/solr/configsets# cp -r nutch crawl
root@ubuntu:/opt/solr/server/solr/configsets# ll

做一次删除操作,清理环境
root@ubuntu:/opt/solr/server/solr/configsets# cd $SOLR_INSTALL
root@ubuntu:/opt/solr# solr delete -c crawl

(3)创建core
为 solr 创建一个不同的 core, 名称为 crawl
root@ubuntu:/opt/solr# bin/solr create -c crawl -d server/solr/configsets/crawl/conf/ -force
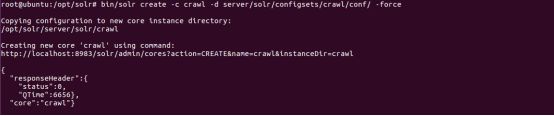
查询
访问链接 http://localhost:8983/solr/#/crawl/query 执行查询任务,返回空,因为新创建的 crawl core还没有建立索引。

(4)运行crawl脚本
依然使用之前定义的种子文件 urls/seed.txt,设置迭代次数 为 3 。
1)执行 crawl 脚本:
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/crawl -i -D solr.server.url=http://localhost:8983/solr/crawl/ -s urls/seed.txt testcrawl 3
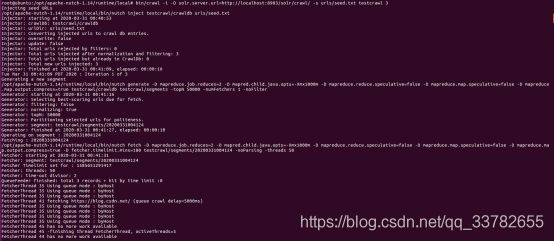
2)在抓取的过程中查询,发现已抓取一部分:

3)查看数据库目录:
可以发现,在/opt/apache-nutch-1.14/runtime/local下自动创建了数据库目录testcrawl,并在testcrawl内创建了nutch的三个数据库,如下:

(5)爬取完成
爬取过程:执行完crawl脚本命令后开始抓取,可看到一站式抓取集成了分步抓取的各个步骤:
执行注入-》生成抓取列表-》抓取-》解析-》抓取-》解析-》抓取-》解析-》更新-》反转链表-》消除重复URL-》建立索引-》结束
具体过程如下
执行注入:injector

生成抓取列表:generator

抓取:fetch
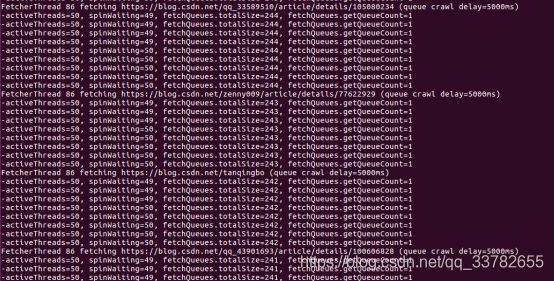
解析:parse
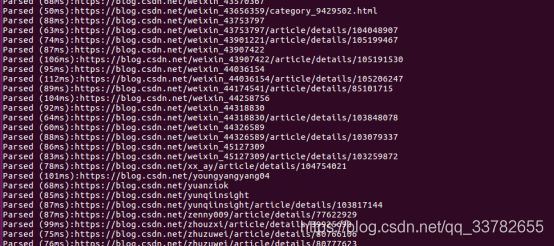
更新:update

反转链接:inversion

消除重复URL:dedup
![]()
建立索引:index

爬取结束:
![]()
抓取完成
(6)查看结果
1)查看数据库状态:
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch readdb testcrawl/crawldb -stats

可以看出抓取了603个URL页面
2)导出到testcrawl/crawldb-dump
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# bin/nutch readdb testcrawl/crawldb -dump testcrawl/crawldb-dump
3)查看
root@ubuntu:/opt/apache-nutch-1.14/runtime/local# cat testcrawl/crawldb-dump/part-00000

(7)执行搜索
在浏览器中输入:http://localhost:8983/solr/#/crawl/query

五、参考
参考: https://wiki.apache.org/nutch/NutchTutorial
https://blog.csdn.net/devalone/article/details/81736042