ElasticSearch详细教程-基础加实战
文章目录
- 第1章 ElasticSearch基础
-
- 1.1 简介
- 1.2 使用场景
- 1.3 ES与其他数据存储进行比较
- 1.4 ElasticSearch的特点
-
- 1.4.1 天然分片,天然集群
- 1.4.2 天然索引
- 1.5 Lucene、Nutch、ElasticSearch关系
- 第2章 ElasticSearch的安装
-
- 2.1 上传安装包
- 2.2 将ES解压到/opt/module目录下
- 2.3 在/opt/module目录下对ES重命名
- 2.4 修改ES配置文件
- 2.5 教学环境启动优化
- 2.6 分发ES
- 2.7 修改hadoop106和hadoop107上的节点名以及网络地址
- 2.8 单台启动测试,以及Linux解决常见问题
- 2.9 集群启动脚本
- 2.10 测试
- 2.11 如果启动未成功
- 第3章 Kibana的安装
-
- 3.1 上传安装包
- 3.2 将Kibana解压到/opt/module目录下
- 3.3 在/opt/module目录下对Kibana重命名
- 3.4 修改Kibana配置文件
- 3.5 启动、测试
- 第4章 ElasticSearch的基本概念
-
- 4.1 概念
-
- 4.1.1 近实时(Near Realtime / NRT)
- 4.1.2 集群(Cluster)
- 4.1.3 节点(Node)
- 4.1.4 索引(Index)
- 4.1.5 类型(Type)
- 4.1.6 文档(Document)
- 4.1.7 字段|属性(Field)
- 4.1.8分片与副本(Shards & Replicas)
- 4.2 概念之间关系图
- 4.3 ES概念和MySQL关系对比
- 第5章 ElasticSearch RestFulAPI(DSL)
-
- 5.1 全局操作
-
- 5.1.1 查询集群健康情况
- 5.1.2 查询各个节点状态
- 5.2 对索引的操作
-
- 5.2.1 查询各个索引状态
- 5.2.2 创建索引
- 5.2.3 查询某个索引的分片情况
- 5.2.4 删除索引
- 5.3 对文档进行操作
-
- 5.3.1 创建文档
- 5.3.2 根据文档id查看文档
- 5.3.3 查询所有文档
- 5.3.4 根据文档id删除文档
- 5.3.5 替换文档
- 5.3.6 根据文档id更新文档
- 5.3.7 根据条件更新文档(了解)
- 5.3.8 删除文档属性(了解)
- 5.3.9 根据条件删除文档(了解)
- 5.3.10 批处理
- 5.4 查询操作
-
- 5.4.1 搜索参数传递有2种方法
- 5.4.2 按条件查询(全部)
- 5.4.3 按分词查询(必须使用分词text类型)
- 5.4.4 按分词子属性查询
- 5.4.5 按短语查询(相当于like %短语%)
- 5.4.6 通过term精准搜索匹配(必须使用keyword类型)
- 5.4.7 fuzzy查询(容错匹配)
- 5.4.8 过滤—先匹配,再过滤
- 5.4.9 过滤—匹配和过滤同时(推荐使用)
- 5.4.10 过滤--按范围过滤
- 5.4.11 排序
- 5.4.12 分页查询
- 5.4.13 指定查询的字段
- 5.4.14 高亮
- 5.4.15 聚合
- 5.5 分词
-
- 5.5.1 查看英文单词默认分词情况
- 5.5.2 查看中文默认分词情况
- 5.5.3 中文分词器
- 5.5.4 IK分词器的安装及使用
- 5.5.5 自定义词库-本地指定
- 5.5.6 自定义词库-远程指定
- 5.6 关于mapping
-
- 5.6.1 基于中文分词搭建索引-自动定义mapping
- 5.6.2 基于中文分词搭建索引-手动定义mapping
- 5.6.3 索引数据拷贝
- 5.7 索引别名 _aliases
-
- 5.7.1 创建索引别名
- 5.7.2 查询别名列表
- 5.7.3 使用索引别名查询
- 5.7.4 删除某个索引的别名
- 5.7.5 使用场景
- 5.8 索引模板
-
- 5.8.1 创建索引模板
- 5.8.2 测试
- 5.8.3 查看系统中已有的模板清单
- 5.8.4 查看某个模板详情
- 5.8.5 使用场景
- 5.8.6 注意
- 第6章 Idea中操作ElasticSearch
-
- 6.1 在Idea中编写操作ES的工具类
- 6.2 编写建立程序到ES的连接的代码
- 6.3 向ES中插入数据
- 6.4 从ES中查询数据
第1章 ElasticSearch基础
1.1 简介
Elasticsearch是一个高度可伸缩的开源全文搜索引擎。Elasticsearch让你可以快速、实时地存储、搜索和分析大量数据,它通常作为互联网应用的内部搜索引擎,为需要复杂搜索功能的应用提供支持。
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
1.2 使用场景
-
电商搜索引擎,使用Elasticsearch存储商品与品类信息,提供搜索和搜索建议功能(全文检索)。
-
日志系统,收集、分析日志数据,可以使用Logstash (Elasticsearch/Logstash/Kibana栈的一部分)来收集,然后将这些数据提供给Elasticsearch,通过搜索和聚合计算挖掘有价值的信息,最后通过Kibana进行可视化展示。
-
价格提醒平台,在价格变动时,让用户可以收到通知。抓取供应商的价格,推入Elasticsearch,并使用其反向搜索(Percolator)功能来匹配用户的价格通知设置,找到匹配后将提醒推送给用户。
-
BI(商业智能),分析业务大数据,挖掘有价值的商务信息。可以使用Elasticsearch来存储数据,然后使用Kibana (Elasticsearch/Logstash/Kibana堆栈的一部分)构建自定义仪表板,该仪表板可以可视化显示数据。此外,还可以使用Elasticsearch聚合功能对数据执行复杂的业务智能分析。
1.3 ES与其他数据存储进行比较
| redis | mysql | elasticsearch | hbase | hadoop/hive | |
|---|---|---|---|---|---|
| 容量/容量扩展 | 低 | 中 | 较大 | 海量 | 海量 |
| 查询时效性 | 极高 | 中等 | 较高 | 中等 | 低 |
| 查询灵活性 | 较差 k-v模式 | 非常好,支持sql | 较好,关联查询较弱,但是可以全文检索,DSL语言可以处理过滤、匹配、排序、聚合等各种操作 | 较差,主要靠rowkey, scan的话性能不行,或者建立二级索引 | 非常好,支持sql |
| 写入速度 | 极快 | 中等 | 较快 | 较快 | 慢 |
| 一致性、事务 | 弱 | 强 | 弱 | 弱 | 弱 |
1.4 ElasticSearch的特点
1.4.1 天然分片,天然集群
ES把数据分成多个shard,下图中的P0-P2,多个shard可以组成一份完整的数据,这些shard可以分布在集群中的各个机器节点中。随着数据的不断增加,集群可以增加多个分片,把多个分片放到多个机子上,已达到负载均衡,横向扩展。
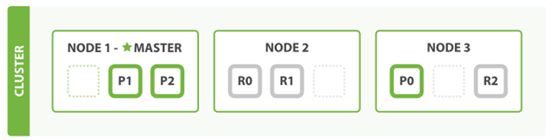
在实际运算过程中,每个查询任务提交到某一个节点,该节点必须负责将数据进行整理汇聚,再返回给客户端,也就是一个简单的节点上进行Map计算,在一个固定的节点上进行Reduces得到最终结果向客户端返回。

这种集群分片的机制造就了elasticsearch强大的数据容量及运算扩展性。
1.4.2 天然索引
ES 所有数据都是默认进行索引的,这点和MySQL正好相反,MySQL是默认不加索引,要加索引必须特别说明,ES只有不加索引才需要说明。
而ES使用的是倒排索引和MySQL的B+Tree索引不同。
-
传统关系性数据库

弊端:
1.对于传统的关系性数据库对于关键词的查询,只能逐字逐行的匹配,性能非常差。
2.匹配方式不合理,比如搜索“小密手机”,如果用like进行匹配, 根本匹配不到。但是考虑使用者的用户体验的话,除了完全匹配的记录,还应该显示一部分近似匹配的记录,至少应该匹配到“手机”。
- 倒排索引是怎么处理的
全文搜索引擎目前主流的索引技术就是倒排索引的方式。
传统的保存数据的方式都是:记录→单词
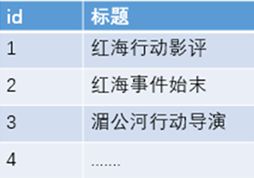
而倒排索引的保存数据的方式是:单词→记录, 基于分词技术构建倒排索引,每个记录保存数据时,都不会直接存入数据库。系统先会对数据进行分词,然后以倒排索引结构保存。如下:
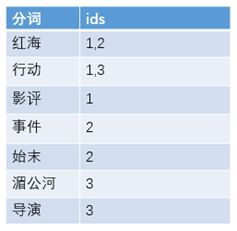
搜索“红海行动”,那么搜索引擎是如何能将两者匹配上的呢?
等到用户搜索的时候,会把搜索的关键词也进行分词,会把“红海行动”分词分成:红海和行动两个词。
这样的话,先用红海进行匹配,得到id=1和id=2的记录编号,再用行动匹配可以迅速定位id为1,3的记录。
那么全文索引通常,还会根据匹配程度进行打分,显然1号记录能匹配的次数更多。所以显示的时候以评分进行排序的话,1号记录会排到最前面。而2、3号记录也可以匹配到。
- 索引结构对比
- B+Tree
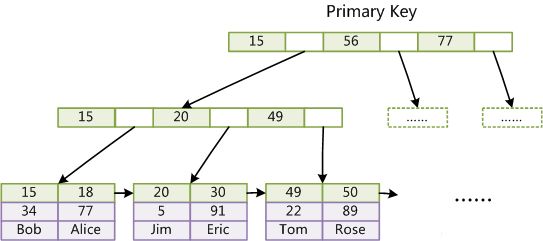
- Lucene 倒排索引结构
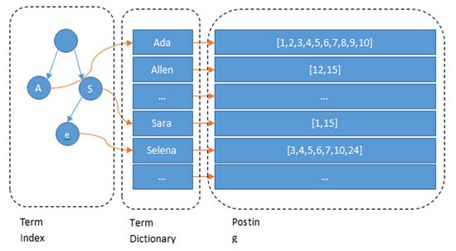
可以看到 Lucene为倒排索引(Term Dictionary)部分又增加一层Term Index结构,用于快速定位,而这Term Index是缓存在内存中的,但MySQL的B+tree不在内存中,所以整体来看ES速度更快,但同时也更消耗资源(内存、磁盘)。
1.5 Lucene、Nutch、ElasticSearch关系
-
1998年9月4日,Google公司在美国硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。
-
同时期,一位名叫Doug Cutting的美国工程师,也迷上了搜索引擎,他基于Java语言开发了一个用于文本搜索的函数库(姑且理解为软件的功能组件),叫做Lucene。Lucene是第一个提供全文文本搜索的函数库,提供了一个简单而强大的应用程序接口,是一个高性能、可伸缩的信息搜索库。作为一个成熟免费的开源项目,Lucene在Java信息检索程序库中得到了广泛的欢迎。开发者不仅能利用它构建 具体的全文检索应用,同时还能将其集成到各种系统软件中,它提供的很多API函数都能运用到各种实际应用程序中。
-
Nutch则是Doug在Lucene基础上将开源思想继续深化的成果,是一个真正的应用程序,它是建立在Lucene核心之上的Web搜索的实现,其目的旨在减少人们使用过程中的复杂度,并在花费很少的情况下配置世界一流的Web搜索引擎,实现开箱即用的特性。 站内索引和搜索推广到全球网络的搜索上,就像Google和雅虎一样。
-
ElasticSearch ,简称为ES , ES是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。

DB Engines统计的数据库排名情况, 在2016年1月, ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用
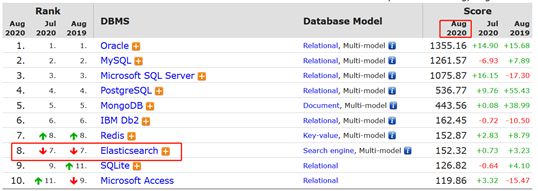
关于ES的起源,他说当年他还是一个待业工程师,跟随自己的新婚妻子来到伦敦,妻子想在伦敦学习做一名厨师,而自己则想为妻子开发一个方便搜索菜谱的应用,所以才接触到 Lucene。
直接使用 Lucene 构建搜索有很多问题,包含大量重复性的工作,所以 Shay Banon 便在 Lucene 的基础上不断地进行抽象,让 Java 程序嵌入搜索变得更容易,经过一段时间的打磨便诞生了他的第一个开源作品“Compass”,中文即“指南针”的意思。之后,他找到了一份面对高性能分布式开发环境的新工作,在工作中他渐渐发现越来越需要一个易用的、高性能、实时、分布式搜索服务,于是决定重写 Compass,将它从一个库打造成了一个独立的 server,并创建了Elasticsearch。
思考:咱们之前讲的处理分词,构建倒排索引,等等,都是这个叫Lucene的做的。那么能不能说这个Lucene就是搜索引擎呢? 还不能。Lucene只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来的应用。 好比Lucene是类似于发动机,而搜索引擎软件(ES,Solr)就是汽车。 目前市面上流行的搜索引擎软件,主流的就两款,ElasticSearch和Solr,这两款都是基于Lucene的搭建的,可以独立部署启动的搜索引擎服务软件。由于内核相同,所以两者除了服务器安装、部署、管理、集群以外,对于数据的操作,修改、添加、保存、查询等等都十分类似。就好像都是支持sql语言的两种数据库软件。只要学会其中一个另一个很容易上手。 从实际企业使用情况来看,ElasticSearch的市场份额逐步在取代Solr,国内百度、京东、新浪都是基于ElasticSearch实现的搜索功能。国外就更多了,像维基百科、GitHub、Stack Overflow等等也都是基于ES的。
第2章 ElasticSearch的安装
本课程选择的版本是elasticsearch-6.6.0
Elasticsearch官网:
https://www.elastic.co/products/elasticsearch
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-6-0
2.1 上传安装包
将/2.资料/02-工具/elasticsearch下的压缩包上传到opt/software/目录下
2.2 将ES解压到/opt/module目录下

ES是开箱即用的,即解压就可以使用
[atguigu@hadoop105 software]$ tar -zxvf elasticsearch-6.6.0.tar.gz -C /opt/module/
2.3 在/opt/module目录下对ES重命名
[atguigu@hadoop105 module]$ mv elasticsearch-6.6.0/ elasticsearch
2.4 修改ES配置文件
修改yml配置的注意事项:
每行必须顶格,不能有空格
“:”后面必须有一个空格
[atguigu@hadoop105 elasticsearch]$ cd config/
[atguigu@hadoop105 config]$ vim elasticsearch.yml
- 集群名称,同一集群名称必须相同
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: my-es
- 单个节点名称
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-1
- 把bootstrap自检程序关掉
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
- 网络部分 改为当前的ip地址 ,端口号保持默认9200就行
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: hadoop105
#
# Set a custom port for HTTP:
#
#http.port: 9200
- 自发现配置:新节点向集群报到的主机名
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: ["hadoop105", "hadoop106", "hadoop107"]
2.5 教学环境启动优化
ES是用在Java虚拟机中运行的,虚拟机默认启动占用1G内存。但是如果是装在PC机学习用,实际用不了1个G。所以可以改小一点内存;但生产环境一般128G内存是标配,这个时候需要将这个内存调大。
vim /opt/module/elasticsearch/config/jvm.options
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms512m
-Xmx512m
2.6 分发ES
[atguigu@hadoop105 module]$ xsync elasticsearch/
2.7 修改hadoop106和hadoop107上的节点名以及网络地址
hadoop106修改为:node.name: node-2 network.host: hadoop106
[atguigu@hadoop106 ~]$ cd /opt/module/elasticsearch/config/
[atguigu@hadoop106 config]$ vim elasticsearch.yml
hadoop107修改为:node.name: node-3 network.host: hadoop107
[atguigu@hadoop107 ~]$ cd /opt/module/elasticsearch/config/
[atguigu@hadoop107 config]$ vim elasticsearch.yml
2.8 单台启动测试,以及Linux解决常见问题
这时直接在hadoop105上单独启动ES,会报如下异常:
[atguigu@hadoop105 bin]$ ./elasticsearch
因为默认elasticsearch是单机访问模式,就是只能自己访问自己。但是上面我们已经设置成允许应用服务器通过网络方式访问,而且生产环境也是这种方式。这时,Elasticsearch就会因为嫌弃单机版的低端默认配置而报错,甚至无法启动。所以我们在这里就要把服务器的一些限制打开,能支持更多并发。
- 问题1:max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] elasticsearch
原因
系统允许 Elasticsearch 打开的最大文件数需要修改成65536
解决
sudo vim /etc/security/limits.conf
添加内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 65536
注意:“*” 不要省略掉
分发文件
sudo /home/atguigu/bin/xsync /etc/security/limits.conf
- 问题2:max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
原因
一个进程可以拥有的虚拟内存区域的数量。
解决
sudo vim /etc/sysctl.conf
在文件最后添加一行
vm.max_map_count=262144
即可永久修改
分发文件
-
sudo /home/atguigu/bin/xsync /etc/sysctl.conf问题3:max number of threads [1024] for user [judy2] likely too low, increase to at least [4096] (CentOS7.x 不用改)
原因
允许最大线程数修该成4096
解决
sudo vim /etc/security/limits.d/20-nproc.conf
修改如下内容
* soft nproc 1024
修改为
* soft nproc 4096
分发文件
sudo /home/atguigu/bin/xsync /etc/security/limits.d/20-nproc.conf
-
重启linux使配置生效
-
再次单独启动hadoop105上的ES
[atguigu@hadoop105 bin]$ ./elasticsearch
测试方式1:
curl http://hadoop105:9200/_cat/nodes?v
![]()
测试方式2:在浏览器中,输入http://hadoop105:9200/查看效果

ES天然就是集群状态,就算是只有一个节点,也会当做集群处理,
默认节点name=主机名,cluster_name=my_es
2.9 集群启动脚本
在/home/atguigu/bin目录下创建es.sh,并授予执行权限
根据自己的配置进行修改
#!/bin/bash
es_home=/opt/module/elasticsearch
kibana_home=//opt/module/kibana
case $1 in
"start") {
for i in hadoop105 hadoop106 hadoop107
do
echo "==============$i上ES启动=============="
ssh $i "source /etc/profile.d/my_env.sh;${es_home}/bin/elasticsearch >/dev/null 2>&1 &"
done
nohup ${kibana_home}/bin/kibana >${kibana_home}/logs/kibana.log 2>&1 &
};;
"stop") {
ps -ef|grep ${kibana_home} |grep -v grep|awk '{print $2}'|xargs kill
for i in hadoop105 hadoop106 hadoop107
do
echo "==============$i上ES停止=============="
ssh $i "ps -ef|grep $es_home |grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1
done
};;
esac
2.10 测试
测试方式1:curl http://hadoop105:9200/_cat/nodes?v

测试方式2:在浏览器中,输入http://hadoop106:9200/查看效果
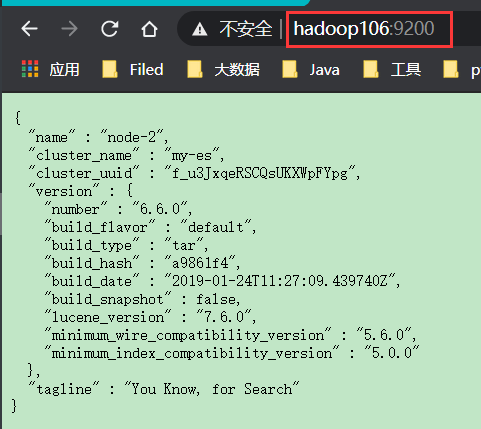
2.11 如果启动未成功
如果启动未成功,请去查看相关日志
vim /opt/module/elasticsearch/logs/my-es.log
第3章 Kibana的安装
Elasticsearch提供了一套全面和强大的REST API,我们可以通过这套API与ES集群进行交互。例如:
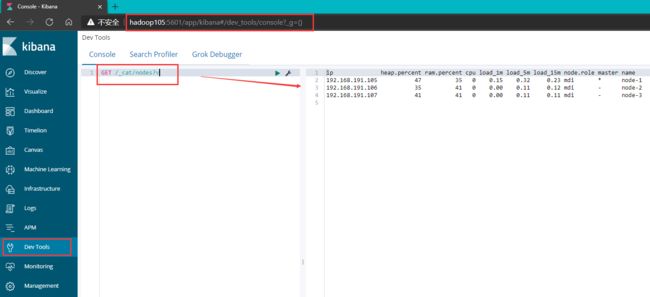
我们可以通过 API: GET /_cat/nodes?v获取ES集群节点情况,要想访问这个API,我们需要使用curl命令工具来访问Elasticsearch服务
curl http://hadoop105:9200/_cat/nodes?v
也可以使用任何其他HTTP/REST调试工具,例如POSTMAN。
Kibana 是为 Elasticsearch设计的开源分析和可视化平台。你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图表的形式展现出来。
3.1 上传安装包
将/2.资料/02-工具/elasticsearch下的压缩包上传到opt/software/目录下
3.2 将Kibana解压到/opt/module目录下
[atguigu@hadoop105 software]$ tar -zxvf kibana-6.6.0-linux-x86_64.tar.gz -C /opt/module/
3.3 在/opt/module目录下对Kibana重命名
[atguigu@hadoop105 module]$ mv kibana-6.6.0-linux-x86_64/ kibana
3.4 修改Kibana配置文件
[atguigu@hadoop105 kibana]$ cd config/
[atguigu@hadoop105 config]$ vim kibana.yml
- 授权远程访问
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "0.0.0.0"
- 指定ElasticSearch地址(可以指定多个,多个地之间用逗号分隔)
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://hadoop105:9200","http://hadoop106:9200","http://hadoop107:9200"]
3.5 启动、测试
Kibana本身只是一个工具,不需要分发,不涉及集群,访问并发量也不会很大
- 启动Kinana
[atguigu@hadoop105 kibana]$ bin/kibana
成功后,提示如下
log [13:51:31.423] [info][listening] Server running at http://0.0.0.0:5601
-
浏览器访问http://hadoop105:5601/
-

在6.7版本之后,支持中文国际化
- 最终集群脚本
在es.sh中,对ES和Kibana同时进行操作
在/opt/module/kibana目录下执行mkdir logs
#!/bin/bash
es_home=/opt/module/elasticsearch
kibana_home=//opt/module/kibana
case $1 in
"start") {
for i in hadoop105 hadoop106 hadoop107
do
echo "==============$i上ES启动=============="
ssh $i "source /etc/profile.d/my_env.sh;${es_home}/bin/elasticsearch >/dev/null 2>&1 &"
done
nohup ${kibana_home}/bin/kibana >${kibana_home}/logs/kibana.log 2>&1 &
};;
"stop") {
ps -ef|grep ${kibana_home} |grep -v grep|awk '{print $2}'|xargs kill
for i in hadoop105 hadoop106 hadoop107
do
echo "==============$i上ES停止=============="
ssh $i "ps -ef|grep $es_home |grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1
done
};;
esac
第4章 ElasticSearch的基本概念
4.1 概念
Elasticsearch有几个核心概念,先理解这些概念将有助于掌握Elasticsearch。
4.1.1 近实时(Near Realtime / NRT)
Elasticsearch是一个近实时的搜索平台,从生成文档索引到文档成为可搜索,有一个轻微的延迟(通常是一秒钟)。
4.1.2 集群(Cluster)
ES 默认就是集群状态,整个集群是一份完整、互备的数据。
集群是一个或多个节点(服务器)的集合。集群中的节点一起存储数据,对外提供搜索功能。集群由一个唯一的名称标识,该名称默认是“elasticsearch”。集群名称很重要,节点都是通过集群名称加入集群。
集群不要重名,取名一般要有明确意义,否则会引起混乱。例如,开发、测试和生产集群的名称可以使用logging-dev、logging-test和logging-prod。
集群节点数不受限制,可以只有一个节点。
4.1.3 节点(Node)
节点是一个服务器,属于某个集群。节点存储数据,参与集群的索引和搜索功能。与集群一样,节点也是通过名称来标识的。默认情况下,启动时会分配给节点一个UUID(全局惟一标识符)作为名称。如有需要,可以给节点取名,通常取名时应考虑能方便识别和管理。
默认情况下,节点加入名为elasticsearch的集群,通过设置节点的集群名,可加入指定集群。
4.1.4 索引(Index)
索引是具有某种特征的文档集合,相当于一本书的目录。例如,可以为客户数据建立索引,为订单数据建立另一个索引。索引由名称标识(必须全部为小写),可以使用该名称,对索引中的文档进行建立索引、搜索、更新和删除等操作。一个集群中,索引数量不受限制。
类似于rdbms的database(5.x), 对于用户来说是一个逻辑数据库,虽然物理上会被分多个shard存放,也可能存放在多个node中。 6.x 7.x index相当于table
4.1.5 类型(Type)
类似于rdbms的table,但是与其说像table,其实更像面向对象中的class , 同一Json的格式的数据集合。(6.x只允许建一个,7.0被废弃,造成index实际相当于table级)
4.1.6 文档(Document)
文档是可以建立索引的基本信息单元,相当于书的具体章节。
例如,可以为单个客户创建一个文档,为单个订单创建另一个文档。文档用JSON (JavaScript对象表示法)表示。在索引中,理论上可以存储任意数量的文档。
类似于rdbms的 row、面向对象里的object
4.1.7 字段|属性(Field)
相当于字段、属性
4.1.8分片与副本(Shards & Replicas)
索引可能存储大量数据,数据量可能超过单个节点的硬件限制。
例如,一个索引包含10亿个文档,将占用1TB的磁盘空间,单个节点的磁盘放不下。
Elasticsearch提供了索引分片功能,创建索引时,可以定义所需的分片数量。每个分片本身都是一个功能齐全,独立的“索引”,可以托管在集群中的任何节点上。
分片之所以重要,主要有2个原因:
n 允许水平切分内容,以便内容可以存储到普通的服务器中
n 允许跨分片操作(如查询时,查询多个分片),提高性能/吞吐量
分片如何部署、如何跨片搜索完全由Elasticsearch管理,对外是透明的。
网络环境随时可能出现故障,如果某个分片/节点由于某种原因离线或消失,那么使用故障转移机制是非常有用的,强烈建议使用这种机制。为此,Elasticsearch允许为分片创建副本。
副本之所以重要,主要有2个原因:
n 在分片/节点失败时提供高可用性。因此,原分片与副本不应放在同一个节点上。
n 扩展吞吐量,因为可以在所有副本上并行执行搜索。
总而言之,索引可以分片,索引分片可以创建副本。复制后,每个索引将具有主分片与副本分片。
创建索引时,可以为每个索引定义分片和副本的数量。之后,还可以随时动态更改副本数量。您可以使用_shrink和_split api更改现有索引的分片数量,但动态修改副本数量相当麻烦,最好还是预先计划好分片数量。
默认情况下,Elasticsearch中的每个索引分配一个主分片和一个副本(7.X之前,默认是5片,副本是0。7.X默认改为1片,副本为1)。如果集群中有两个节点,就可以将索引主分片部署在一个节点,副本分片放在另一个节点,提高可用性。
4.2 概念之间关系图

这张图可以展示出ES各组件之间的关系,整张表是一个Cluster,横行是Nodes,竖列是Indices,深绿色方块是Primary Shards,浅绿色方块是Replica Shards。
至于单个Host上的Node数目问题,在硬件资源有限的情况下,一般的做法是一个Host只运行一个ES进程,也就是一个Node。例外情况是,由于ES内存配置上的特殊要求(JVM Heap不能超过32G),如果你的Host特别NB(16 Core CPU + 128G RAM + SSD 这种),完全可以在单个Host上运行多个ES进程以避免硬件资源的浪费。
4.3 ES概念和MySQL关系对比
| MySQL | ES5.X | ES6.X | ES7.X |
|---|---|---|---|
| Database | Index | ||
| Table | Type | Index(Type成了摆设) | Index(Type被移除掉) |
| Row | Document | Document | |
| Column | Field | Field |
假设有如下实体
public class Movie {
String id;
String name;
Double doubanScore;
List<Actor> actorList;
}
public class Actor{
String id;
String name;
}
这两个对象如果放在关系型数据库保存,会被拆成2张表,但是ElasticSearch是用一个json来表示一个document。类似豆瓣某个电影详情页 https://movie.douban.com/
保存到ES中应该是
{
"id":"1",
"name":"operation red sea",
"doubanScore":"8.5",
"actorList":[
{"id":"1","name":"zhangyi"},
{"id":"2","name":"haiqing"},
{"id":"3","name":"zhanghanyu"}
]
}
第5章 ElasticSearch RestFulAPI(DSL)
DSL全称 Domain Specific language,即特定领域专用语言
5.1 全局操作
5.1.1 查询集群健康情况
API:GET /_cat/health?v ?v表示显示头信息
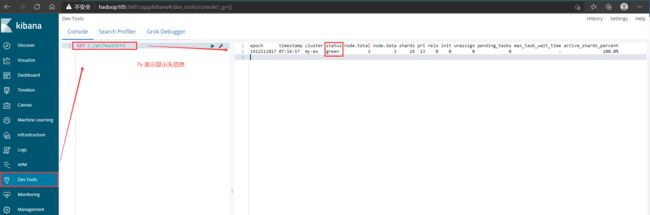
集群的健康状态有红、黄、绿三个状态:
n 绿 – 一切正常(集群功能齐全)
n 黄 – 所有数据可用,但有些副本尚未分配(集群功能完全)
n 红 – 有些数据不可用(集群部分功能)
5.1.2 查询各个节点状态
API:GET /_cat/nodes?v

5.2 对索引的操作
5.2.1 查询各个索引状态
API:GET /_cat/indices?v

ES中会默认存在一些索引
| health | green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
|---|---|
| status | 是否能使用 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主节点几个分片 |
| rep | 从节点几个(副本数) |
| docs.count | 文档数 |
| docs.deleted | 文档被删了多少 |
| store.size | 整体占空间大小 |
| pri.store.size | 主节点占空间大小 |
5.2.2 创建索引
API:PUT 索引名?pretty
PUT movie_index?pretty

使用PUT创建名为“movie_index”的索引。末尾追加pretty,可以漂亮地打印JSON响应(如果有的话)。红色警告说在7.x分片数会由默认的5改为1,我们忽略即可
索引名命名要求:
-
仅可能为小写字母,不能下划线开头
-
不能包括 , /, *, ?, ", <, >, |, 空格, 逗号, #
-
7.0版本之前可以使用冒号:,但不建议使用并在7.0版本之后不再支持
-
不能以这些字符 -, _, + 开头
-
不能包括 . 或 …
-
长度不能超过 255 个字符
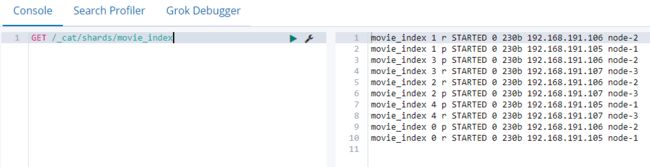
5.2.3 查询某个索引的分片情况
API:GET /_cat/shards/索引名
GET /_cat/shards/movie_index
默认5个分片,1个副本。所以看到一共有10个分片,5个主,每一个主分片对应一个副本,注意:同一个分片的主和副本肯定不在同一个节点上
5.2.4 删除索引
API:DELETE /索引名
DELETE /movie_index

5.3 对文档进行操作
5.3.1 创建文档
现在向索引movie_index中放入文档,文档ID分别为1,2,3
API: PUT /索引名/类型名/文档id
注意:文档id和文档中的属性”id”不是一回事
PUT /movie_index/movie/1
{ "id":100,
"name":"operation red sea",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"zhang yi"},
{"id":2,"name":"hai qing"},
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/2
{
"id":200,
"name":"operation meigong river",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/3
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"zhang san feng"}
]
}
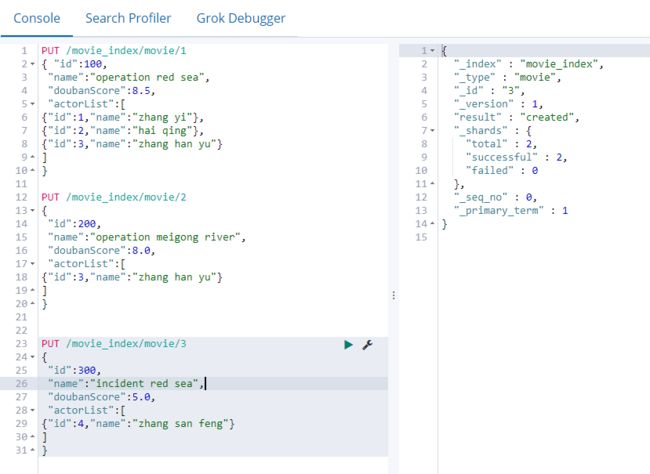
注意,Elasticsearch并不要求,先要有索引,才能将文档编入索引。创建文档时,如果指定索引不存在,将自动创建。默认创建的索引分片是5,副本是1,我们创建的文档会在其中的某一个分片上存一份,副本上存一份,所以看到的响应_shards-total:2
5.3.2 根据文档id查看文档
API:GET /索引名/类型名/文档id
GET /movie_index/movie/1?pretty

这里有一个字段found为真,表示找到了一个ID为1的文档,另一个字段_source,该字段返回完整JSON文档。
5.3.3 查询所有文档
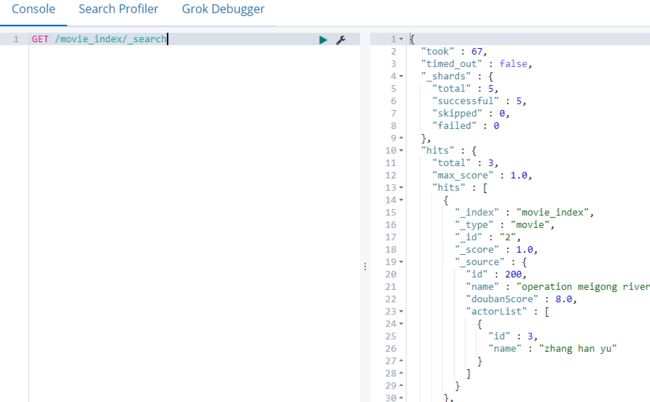
API:GET /索引名/_search
Kinana中默认显示10条,可以通过size控制
GET /movie_index/_search
{
"size":10
}
took:执行查询花费的时间毫秒数
_shards=>total:搜索了多少个分片(当前表示搜索了全部5个分片)
5.3.4 根据文档id删除文档
API: DELETE /索引名/类型名/文档id
DELETE /movie_index/movie/3

注意:删除索引和删除文档的区别?
-
删除索引是会立即释放空间的,不存在所谓的“标记”逻辑。
-
删除文档的时候,是将新文档写入,同时将旧文档标记为已删除。 磁盘空间是否释放取决于新旧文档是否在同一个segment file里面,因此ES后台的segment merge在合并segment file的过程中有可能触发旧文档的物理删除。
-
也可以手动执行POST /_forcemerge进行合并触发
5.3.5 替换文档
- PUT(幂等性操作)
当我们通过执行PUT /索引名/类型名/文档id命令的添加时候,如果文档id已经存在,那么再次执行上面的命令,ElasticSearch将替换现有文档。
PUT /movie_index/movie/3
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"zhang cuishan"}
]
}
文档id3已经存在,会替换原来的文档内容

- POST(非幂等性操作)
创建文档时,ID部分是可选的。如果没有指定,Elasticsearch将生成一个随机ID,然后使用它来引用文档。
POST /movie_index/movie/
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"zhang cuishan"}
]
}

5.3.6 根据文档id更新文档
除了创建和替换文档外,ES还可以更新文档中的某一个字段内容。注意,Elasticsearch实际上并没有在底层执行就地更新,而是先删除旧文档,再添加新文档。
API:
POST /索引名/类型名/文档id/_update?pretty
{
"doc": { "字段名": "新的字段值" } doc固定写法
}
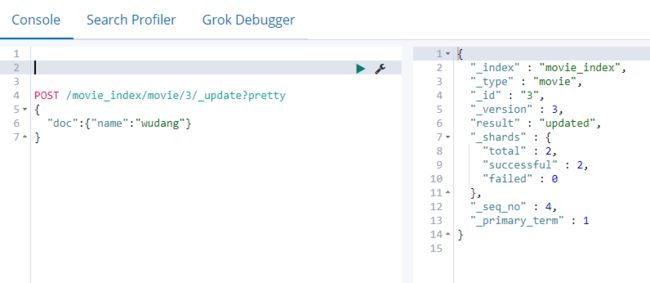
需求:把文档ID为3中的name字段更改为“wudang”:
POST /movie_index/movie/3/_update?pretty
{
"doc": {"name":"wudang"}
}
5.3.7 根据条件更新文档(了解)
POST /movie_index/_update_by_query
{
"query": {
"match":{
"actorList.id":1
}
},
"script": {
"lang": "painless",
"source":"for(int i=0;i
}
}
5.3.8 删除文档属性(了解)
POST /movie_index/movie/1/_update
{
"script" : "ctx._source.remove('name')"
}
5.3.9 根据条件删除文档(了解)
POST /movie_index /_delete_by_query
{
"query": {
"match_all": {}
}
}
5.3.10 批处理
除了对单个文档执行创建、更新和删除之外,ElasticSearch还提供了使用_bulk API批量执行上述操作的能力。
API: POST /索引名/类型名/_bulk?pretty _bulk表示批量操作
注意:Kibana要求批量操作的json内容写在同一行
需求1:在索引中批量创建两个文档
POST /movie_index/movie/_bulk
{"index":{"_id":66}}
{"id":300,"name":"incident red sea","doubanScore":5.0,"actorList":[{"id":4,"name":"zhang cuishan"}]}
{"index":{"_id":88}}
{"id":300,"name":"incident red sea","doubanScore":5.0,"actorList":[{"id":4,"name":"zhang cuishan"}]}
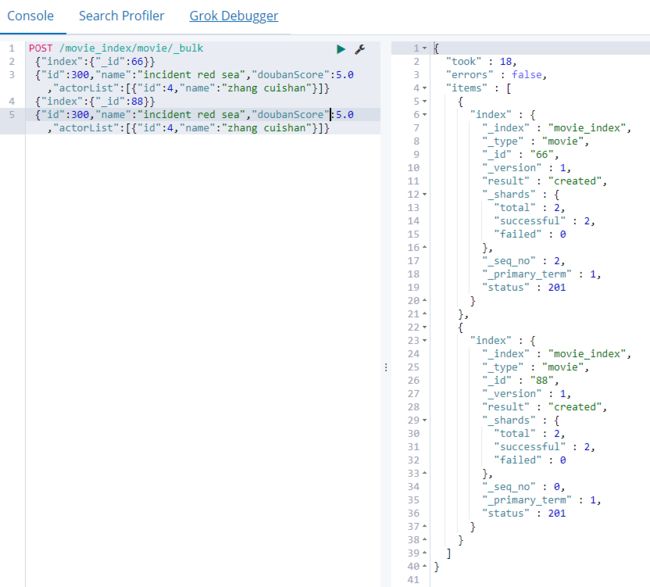
需求2:在一个批量操作中,先更新第一个文档(ID为66),再删除第二个文档(ID为88)
POST /movie_index/movie/_bulk
{“update”:{"_id":“66”}}
{“doc”: { “name”: “wudangshanshang” } }
{“delete”:{"_id":“88”}}

5.4 查询操作
5.4.1 搜索参数传递有2种方法
- URI发送搜索参数查询所有数据
GET /索引名/_search?q=* &pretty
例如:GET /movie_index/_search?q=_id:66
这种方式不太适合复杂查询场景,了解
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-search.html
- 请求体(request body)发送搜索参数查询所有数据
GET /movie_index/_search
{
"query": {
"match_all": {}
}
}
5.4.2 按条件查询(全部)
GET movie_index/movie/_search
{
"query":{
"match_all": {}
}
}
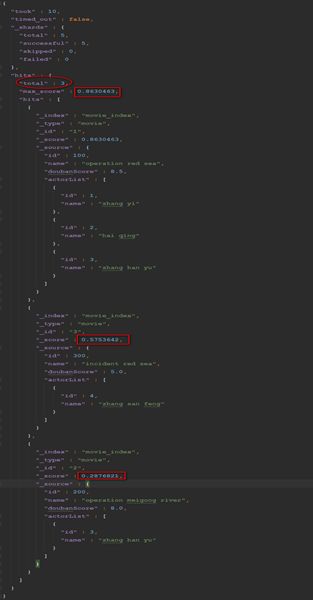
5.4.3 按分词查询(必须使用分词text类型)
测试前:将movie_index索引中的数据恢复到初始的3条
GET movie_index/movie/_search
{
"query":{
"match": {"name":"operation red sea"}
}
}
ES中,name属性会进行分词,底层以倒排索引的形式进行存储,对查询的内容也会进行分词,然后和文档的name属性内容进行匹配,所以命中3次,不过命中的分值不同。
注意:ES底层在保存字符串数据的时候,会有两种类型text和keyword
text:分词
keyword:不分词
5.4.4 按分词子属性查询
GET movie_index/movie/_search
{
"query":{
"match": {"actorList.name":"zhang han yu"}
}
}
返回3条件结果
5.4.5 按短语查询(相当于like %短语%)
按短语查询,不再利用分词技术,直接用短语在原始数据中匹配
GET movie_index/movie/_search
{
"query":{
"match_phrase": {"actorList.name":"zhang han yu"}
}
}
返回2条结果,把演员名包含zhang han yu的查询出来
5.4.6 通过term精准搜索匹配(必须使用keyword类型)
GET movie_index/movie/_search
{
"query":{
"term":{
"actorList.name.keyword":"zhang han yu"
}
}
}
返回2条结果,把演员中完全匹配zhang han yu的查询出来
5.4.7 fuzzy查询(容错匹配)
校正匹配分词,当一个单词都无法准确匹配,ES通过一种算法对非常接近的单词也给与一定的评分,能够查询出来,但是消耗更多的性能,对中文来讲,实现不是特别好。
GET movie_index/movie/_search
{
"query":{
"fuzzy": {"name":"rad"}
}
}
返回2个结果,会把incident red sea和operation red sea匹配上
5.4.8 过滤—先匹配,再过滤
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red"}
},
"post_filter":{
"term": {
"actorList.id": 3
}
}
}
5.4.9 过滤—匹配和过滤同时(推荐使用)
GET movie_index/movie/_search
{
"query": {
"bool": {
"must": [
{"match": {
"name": "red"
}}
],
"filter": [
{"term": { "actorList.id": "1"}},
{"term": {"actorList.id": "3"}}
]
}
}
}
5.4.10 过滤–按范围过滤
GET movie_index/movie/_search
{
"query": {
"range": {
"doubanScore": {
"gte": 6,
"lte": 8.5
}
}
}
}
关于范围操作符:
| gt | 大于 |
|---|---|
| lt | 小于 |
| gte | 大于等于 great than or equals |
| lte | 小于等于 less than or equals |
5.4.11 排序
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
},
"sort":
{
"doubanScore": {
"order": "desc"
}
}
}
5.4.12 分页查询
from参数(基于0)指定从哪个文档序号开始,size参数指定返回多少个文档,这两个参数对于搜索结果分页非常有用。注意,如果没有指定from,则默认值为0。
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
5.4.13 指定查询的字段
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"_source": ["name", "doubanScore"]
}
只显示name和doubanScore字段
5.4.14 高亮
对命中的词进行高亮显示
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
},
"highlight": {
"fields": {"name":{} }
}
}
5.4.15 聚合
聚合提供了对数据进行分组、统计的能力,类似于SQL中Group By和SQL聚合函数。在ElasticSearch中,可以同时返回搜索结果及其聚合计算结果,这是非常强大和高效的。
需求1:取出每个演员共参演了多少部电影
GET movie_index/movie/_search
{
"aggs": {
"myAGG": {
"terms": {
"field": "actorList.name.keyword"
}
}
}
}
aggs:表示聚合
myAGG:给聚合取的名字,
trems:表示分组,相当于groupBy
field:指定分组字段
需求2:每个演员参演电影的平均分是多少,并按评分排序
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor_id": {
"terms": {
"field": "actorList.name.keyword" ,
"order": {
"avg_score": "desc"
}
},
"aggs": {
"avg_score":{
"avg": {
"field": "doubanScore"
}
}
}
}
}
}
思考:聚合时为何要加 .keyword后缀?
.keyword 是某个字符串字段,专门储存不分词格式的副本,在某些场景中只允许只用不分词的格式,比如过滤filter比如聚合aggs, 所以字段要加上.keyword的后缀。
5.5 分词
5.5.1 查看英文单词默认分词情况
GET _analyze
{
"text":"hello world"
}
按照空格对单词进行切分
5.5.2 查看中文默认分词情况
GET _analyze
{
"text":"小米手机"
}
按照每个汉字进行切分
5.5.3 中文分词器
通过上面的查询,我们可以看到ES本身自带的中文分词,就是单纯把中文一个字一个字的分开,根本没有词汇的概念。但是实际应用中,用户都是以词汇为条件,进行查询匹配的,如果能够把文章以词汇为单位切分开,那么与用户的查询条件能够更贴切的匹配上,查询速度也更加快速。
常见的一些开源分词器对比,我们使用IK分词器
| 分词器 | 优势 | 劣势 |
|---|---|---|
| Smart Chinese Analysis | 官方插件 | 中文分词效果惨不忍睹 |
| IKAnalyzer | 简单易用,支持自定义词典和远程词典 | 词库需要自行维护,不支持词性识别 |
| 结巴分词 | 新词识别功能 | 不支持词性识别 |
| Ansj中文分词 | 分词精准度不错,支持词性识别 | 对标hanlp词库略少,学习成本高 |
| Hanlp | 目前词库最完善,支持的特性非常多 | 需要更优的分词效果,学习成本高 |
5.5.4 IK分词器的安装及使用
- 下载地址
https://github.com/medcl/elasticsearch-analysis-ik
-
将/2.资料/02-工具/elasticsearch相关上传到/opt/software
-
解压zip文件
[atguigu@hadoop105 software]$ unzip elasticsearch-analysis-ik-6.6.0.zip -d /opt/module/elasticsearch/plugins/ik
注意
使用unzip进行解压
-d指定解压后的目录
必须放到ES的plugins目录下,并在plugins目录下创建单独的目录
-
查看/opt/module/elasticsearch/plugins/ik/conf下的文件,分词就是将所有词汇分好放到文件中
-
分发
xsync /opt/module/elasticsearch/plugins/ik
- 重启ES
[atguigu@hadoop105 elasticsearch]$ es.sh stop
[atguigu@hadoop105 elasticsearch]$ es.sh start
-
测试使用
-
默认分词器
GET movie_index/_analyze
{
"text": "我是中国人"
}
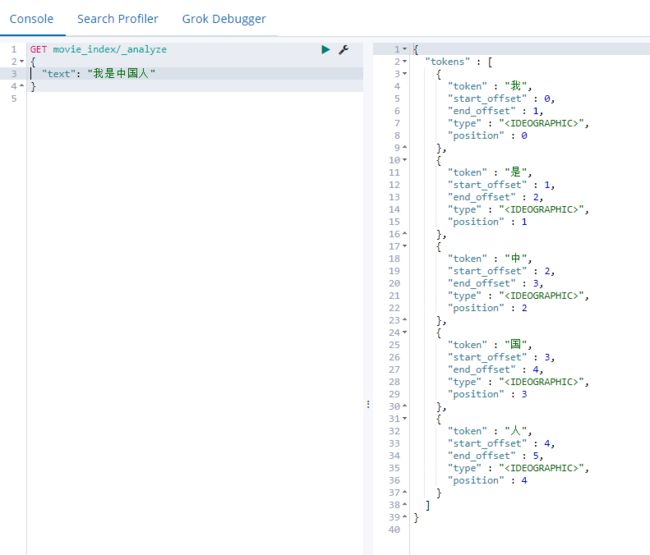
- ik_smart分词方式
GET movie_index/_analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}

- ik_max_word分词方式
GET movie_index/_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
5.5.5 自定义词库-本地指定
有的时候,词库提供的词并不包含项目中使用到的一些专业术语或者新兴网络用语,需要我们对词库进行补充。具体步骤
- 没有使用自定义词库前
GET movie_index/_analyze
{
"analyzer": "ik_smart",
"text": "蓝瘦香菇"
}
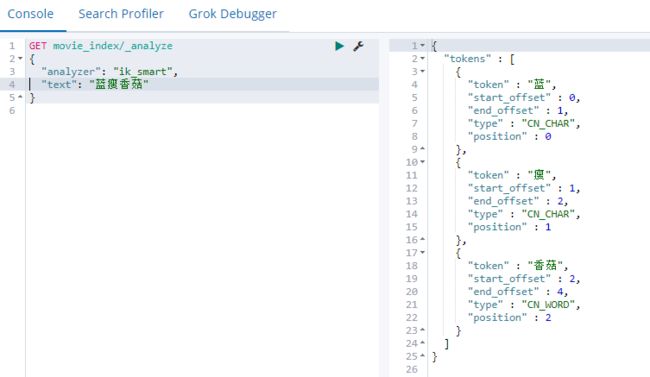
- 通过配置本地目录直接指定自定义词库
n 修改/opt/module/elasticsearch/plugins/ik/config/中的IKAnalyzer.cfg.xmlcd
DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">./myword.txtentry>
<entry key="ext_stopwords">entry>
properties>
名词概念:停止词,是由英文单词:stopword翻译过来的,原来在英语里面会遇到很多a,the,or等使用频率很多的字或词,常为冠词、介词、副词或连词等。 如果搜索引擎要将这些词都索引的话,那么几乎每个网站都会被索引,也就是说工作量巨大。可以毫不夸张的说句,只要是个英文网站都会用到a或者是the。那么这些英文的词跟我们中文有什么关系呢? 在中文网站里面其实也存在大量的stopword,我们称它为停止词。比如,我们前面这句话,“在”、“里面”、“也”、“的”、“它”、“为”这些词都是停止词。这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎开发人员都将这一类词语全部忽略掉。如果我们的网站上存在大量这样的词语,那么相当于浪费了很多资源。原本可以添加一个关键词,排名就可以上升一名的,为什么不留着添加为关键词呢?停止词对SEO的意义不是越多越好,而是尽量的减少为宜。
- 在/opt/module/elasticsearch/plugins/ik/config/当前目录下创建myword.txt
[atguigu@hadoop105 config]$ vim myword.txt
蓝瘦
蓝瘦香菇
- 分发配置文件以及myword.txt
xsync /opt/module/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
xsync /opt/module/elasticsearch/plugins/ik/config/myword.txt
- 重启ES服务
es.sh stop
es.sh start
- 测试分词效果

5.5.6 自定义词库-远程指定
- 远程配置一般是如下流程,我们这里简易通过nginx模拟
n 修改/opt/module/elasticsearch/plugins/ik/config/中的IKAnalyzer.cfg.xml
DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="remote_ext_dict">http://hadoop105/fenci/myword.txtentry>
properties>
注意:将本地配置注释掉
n 分发配置文件
xsync /opt/module/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
n 在nginx.conf文件中配置静态资源路径
[atguigu@hadoop105 conf]$ pwd
/opt/module/nginx/conf
[atguigu@hadoop105 conf]$ vim nginx.conf
location /fenci{
root es;
}
- 在/opt/module/nginx/目录下创建es/fenci目录,并在es/fenci目录下创建myword.txt
[atguigu@hadoop105 fenci]$ pwd
/opt/module/nginx/es/fenci
[atguigu@hadoop105 es]$ vim myword.txt
蓝瘦
蓝瘦香菇
- 启动nginx
/opt/module/nginx/sbin/nginx
- 测试nginx是否能够访问
- 重启ES服务
es.sh stop
es.sh start
- 测试分词效果
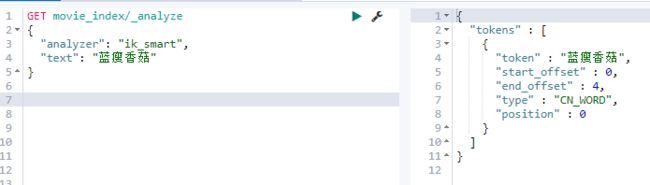

更新完成后,ES只会对新增的数据用新词分词。历史数据是不会重新分词的。如果想要历史数据重新分词。需要执行:
POST movies_index_chn/_update_by_query?conflicts=proceed
5.6 关于mapping
之前说Type可以理解为关系型数据库的Table,那每个字段的数据类型是如何定义的呢?
实际上每个Type中的字段是什么数据类型,由mapping定义,如果我们在创建Index的时候,没有设定mapping,系统会自动根据一条数据的格式来推断出该数据对应的字段类型,具体推断类型如下:
-
true/false → boolean
-
1020 → long
-
20.1 → float
-
“2018-02-01” → date
-
“hello world” → text +keyword
默认只有text会进行分词,keyword是不会分词的字符串。mapping除了自动定义,还可以手动定义,但是只能对新加的、没有数据的字段进行定义,一旦有了数据就无法再做修改了。
5.6.1 基于中文分词搭建索引-自动定义mapping
- 直接创建Document
这个时候index不存在,建立文档的时候自动创建index,同时mapping会自动定义
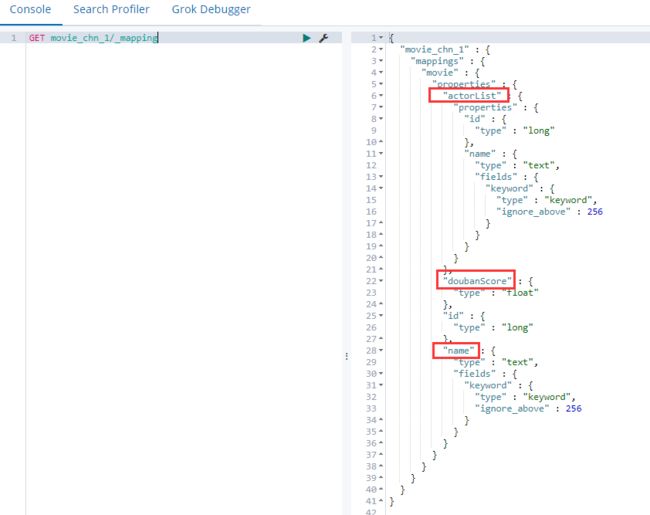
- 查看自动定义的mapping
PUT /movie_chn_1/movie/1
{ "id":1,
"name":"红海行动",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"张译"},
{"id":2,"name":"海清"},
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn_1/movie/2
{
"id":2,
"name":"湄公河行动",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn_1/movie/3
{
"id":3,
"name":"红海事件",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"张三丰"}
]
}
- 查询测试
GET /movie_chn_1/movie/_search
{
"query": {
"match": {
"name": "海行"
}
}
}
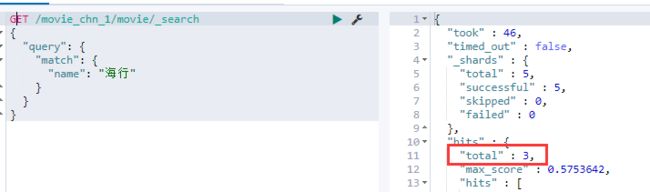
- 分析结论
上面查询“海行”命中了三条记录,是因为我们在定义的Index的时候,没有指定分词器,使用的是默认的分词器,对中文是按照每个汉字进行分词的。
5.6.2 基于中文分词搭建索引-手动定义mapping
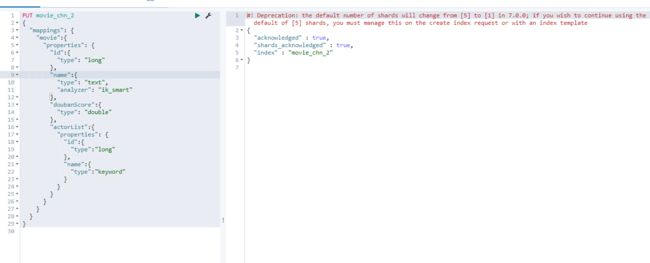
- 定义Index,指定mapping
PUT movie_chn_2
{
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text",
"analyzer": "ik_smart"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
- 向Index中放入Document
PUT /movie_chn_2/movie/1
{ "id":1,
"name":"红海行动",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"张译"},
{"id":2,"name":"海清"},
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn_2/movie/2
{
"id":2,
"name":"湄公河行动",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn_2/movie/3
{
"id":3,
"name":"红海事件",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"张三丰"}
]
}
- 查看手动定义的mapping

- 查询测试
GET /movie_chn_2/movie/_search
{
"query": {
"match": {
"name": "海行"
}
}
}
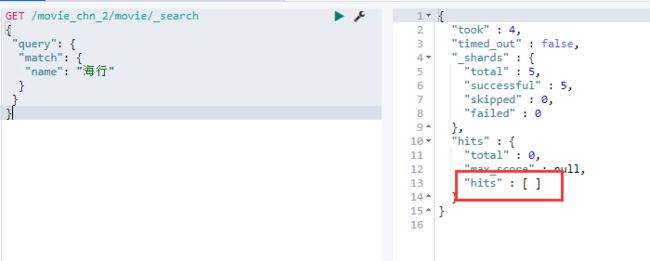
- 分析结论
上面查询没有命中任何记录,是因为我们在创建Index的时候,指定使用ik分词器进行分词
5.6.3 索引数据拷贝
ElasticSearch虽然强大,但是却不能动态修改mapping到时候我们有时候需要修改结构的时候不得不重新创建索引;
ElasticSearch为我们提供了一个reindex的命令,就是会将一个索引的快照数据copy到另一个索引,默认情况下存在相同的_id会进行覆盖(一般不会发生,除非是将两个索引的数据copy到一个索引中),可以使用POST _reindex命令将索引快照进行copy
POST _reindex
{
"source": {
"index": "my_index_name"
},
"dest": {
"index": "my_index_name_new"
}
}
5.7 索引别名 _aliases
索引别名就像一个快捷方式或软连接,可以指向一个或多个索引,也可以给任何一个需要索引名的API来使用。
5.7.1 创建索引别名
-
创建Index的时候声明
PUT 索引名 { "aliases": { "索引别名": {} } } #创建索引的时候,手动mapping,并指定别名 PUT movie_chn_3 { "aliases": { "movie_chn_3_aliase": {} }, "mappings": { "movie":{ "properties": { "id":{ "type": "long" }, "name":{ "type": "text", "analyzer": "ik_smart" }, "doubanScore":{ "type": "double" }, "actorList":{ "properties": { "id":{ "type":"long" }, "name":{ "type":"keyword" } } } } } } } -
为已存在的索引增加别名
POST _aliases
{
"actions": [
{ "add":{ "index": "索引名", "alias": "索引别名" }}
]
}
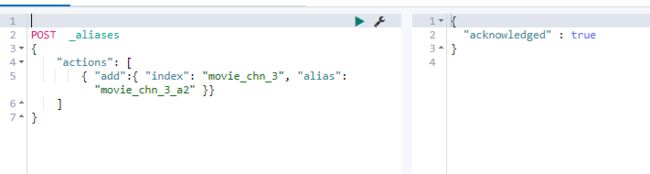
#给movie_chn_3添加别名
POST _aliases
{
"actions": [
{ "add":{ "index": "movie_chn_3", "alias": "movie_chn_3_a2" }}
]
}
5.7.2 查询别名列表
GET _cat/aliases?v
![]()
5.7.3 使用索引别名查询
与使用普通索引没有区别
GET 索引别名/_search

5.7.4 删除某个索引的别名
POST _aliases
{
"actions": [
{ "remove": { "index": "索引名", "alias": "索引别名" }}
]
}

5.7.5 使用场景
- 给多个索引分组 (例如, last_three_months)
POST _aliases
{
"actions": [
{ "add": { "index": "movie_chn_1", "alias": "movie_chn_query" }},
{ "add": { "index": "movie_chn_2", "alias": "movie_chn_query" }}
]
}
GET movie_chn_query/_search
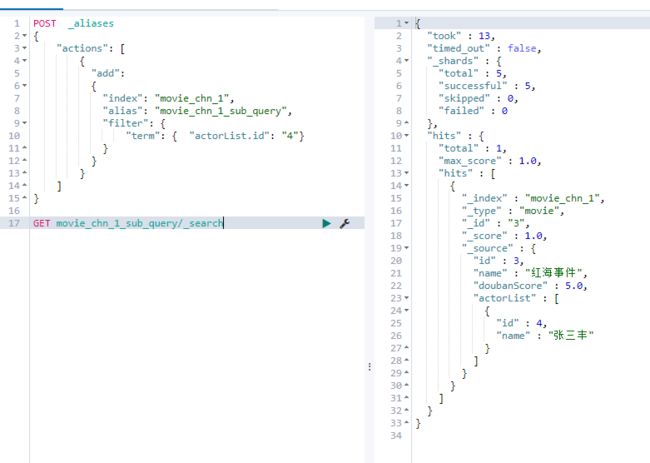
- 给索引的一个子集创建视图
相当于给Index加了一些过滤条件,缩小查询范围
POST _aliases
{
"actions": [
{
"add":
{
"index": "movie_chn_1",
"alias": "movie_chn_1_sub_query",
"filter": {
"term": { "actorList.id": "4"}
}
}
}
]
}
GET movie_chn_1_sub_query/_search
- 在运行的集群中可以无缝的从一个索引切换到另一个索引
POST /_aliases
{
"actions": [
{ "remove": { "index": "movie_chn_1", "alias": "movie_chn_query" }},
{ "remove": { "index": "movie_chn_2", "alias": "movie_chn_query" }},
{ "add": { "index": "movie_chn_3", "alias": "movie_chn_query" }}
]
}
整个操作都是原子的,不用担心数据丢失或者重复的问题
5.8 索引模板
索引模板(Index Template),顾名思义就是创建索引的模具,其中可以定义一系列规则来帮助我们构建符合特定业务需求的索引的mappings和settings,通过使用索引模板可以让我们的索引具备可预知的一致性。
5.8.1 创建索引模板
PUT _template/template_movie2020
{
"index_patterns": ["movie_test*"],
"settings": {
"number_of_shards": 1
},
"aliases" : {
"{index}-query": {},
"movie_test-query":{}
},
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "keyword"
},
"movie_name": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
}
其中 “index_patterns”: [“movie_test*”]的含义就是凡是往movie_test开头的索引写入数据时,如果索引不存在,那么ES会根据此模板自动建立索引。
在 “aliases” 中用{index}表示,获得真正的创建的索引名。aliases中会创建两个别名,一个是根据当前索引创建的,另一个是全局固定的别名。
5.8.2 测试
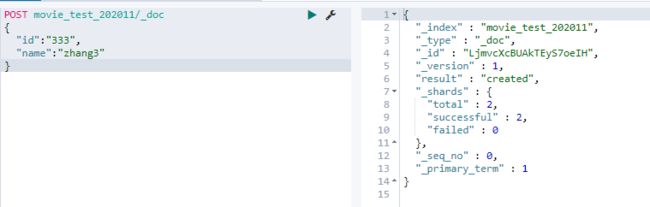
- 向索引中添加数据
POST movie_test_202011/_doc
{
"id":"333",
"name":"zhang3"
}
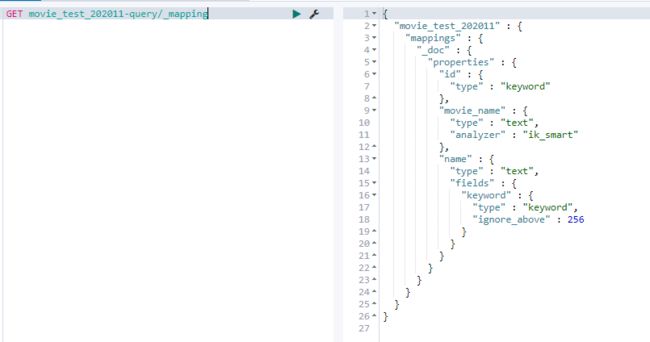
- 查询Index的mapping,就是使用我们的索引模板创建的
GET movie_test_202011-query/_mapping
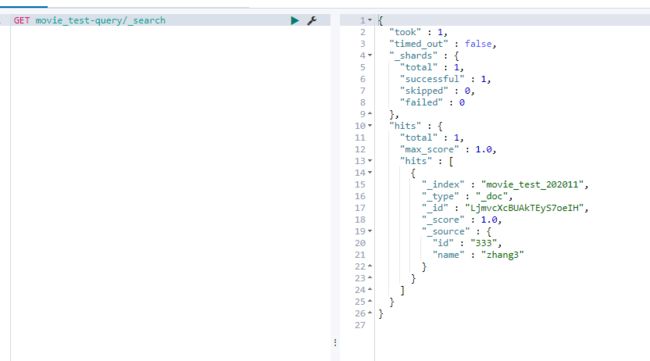
- 根据模板中取的别名查询数据
GET movie_test-query/_search
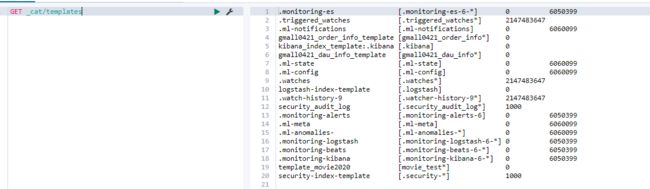
5.8.3 查看系统中已有的模板清单
GET _cat/templates
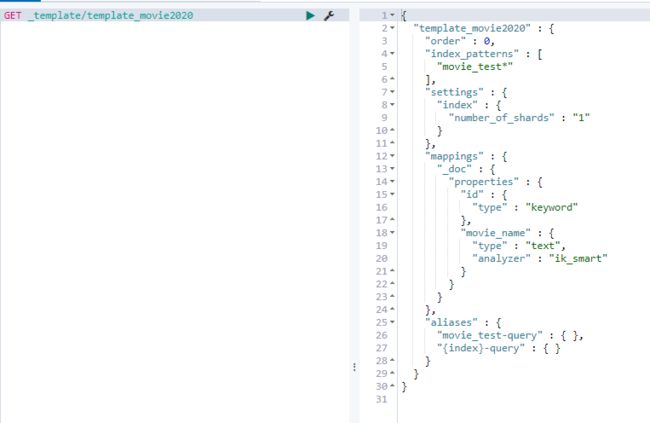
5.8.4 查看某个模板详情
GET _template/template_movie2020
或者
GET _template/template_movie*
5.8.5 使用场景
-
分割索引
分割索引就是根据时间间隔把一个业务索引切分成多个索引。
比如 把order_info 变成 order_info_20200101,order_info_20200102 ……
这样做的好处有两个:
- 结构变化的灵活性
因为ES不允许对数据结构进行修改。但是实际使用中索引的结构和配置难免变化,那么只要对下一个间隔的索引进行修改,原来的索引维持原状。这样就有了一定的灵活性。
要想实现这个效果,我们只需要在需要变化的索引那天将模板重新建立即可。
- 查询范围优化
因为一般情况并不会查询全部时间周期的数据,那么通过切分索引,物理上减少了扫描数据的范围,也是对性能的优化。
5.8.6 注意
使用索引模板,一般在向索引中插入第一条数据创建索引,如果ES中的Shard特别多,有可能创建索引会变慢,如果延迟不能接受,可以不使用模板,使用定时脚本在头一天提前建立第二天的索引。
第6章 Idea中操作ElasticSearch
6.1 在Idea中编写操作ES的工具类
(1) 在Idea中创建新的Mavan模块,gmall0421-realtime

(2) 添加Scala支持
(3) 选择操作ES的java客户端
目前市面上有两类客户端
-
一类是TransportClient 为代表的ES原生客户端,不能执行原生DSL语句必须使用它的Java api方法。
-
一类是以Rest ApI为主的client,最典型的就是jest。 这种客户端可以直接使用DSL语句拼成的字符串,直接传给服务端,然后返回json字符串再解析。
两种方式各有优劣,但是最近ElasticSearch官网,宣布计划在7.0以后的版本中废除TransportClient,以RestClient为主。

所以在官方的RestClient 基础上,进行了简单包装的Jest客户端,就成了首选,而且该客户端也与SpringBoot完美集成。
(4) 导入Jest相关依赖
<dependencies>
<dependency>
<groupId>io.searchboxgroupId>
<artifactId>jestartifactId>
<version>5.3.3version>
dependency>
<dependency>
<groupId>net.java.dev.jnagroupId>
<artifactId>jnaartifactId>
<version>4.5.2version>
dependency>
<dependency>
<groupId>org.codehaus.janinogroupId>
<artifactId>commons-compilerartifactId>
<version>3.0.16version>
dependency>
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>6.6.0version>
dependency>
dependencies>
(5) 创建Scala伴生对象即工具类MyESUtil
package com.atguigu.gmall.realtime.utils
object MyESUtil {
}
6.2 编写建立程序到ES的连接的代码
object MyESUtil {
//1 声明一个JestClientFactory客户端工厂
private var factory: JestClientFactory = null;
//3 创建获取factory的方法
def getClient(): JestClient = {
if (factory == null) {
build()
}
//2 获取factory
factory.getObject
}
//4 创建JestClientFactory
def build(): Unit = {
factory = new JestClientFactory
factory.setHttpClientConfig(new HttpClientConfig
.Builder("http://hadoop105:9200")
.multiThreaded(true) //使用多线程
.maxTotalConnection(20) //最大连接数
.connTimeout(10000) //超时时间 毫秒
.readTimeout(1000) //操作超时时间
.build()
)
}
6.3 向ES中插入数据
//向ES中插入数据
def putIndex(): Unit ={
//建立连接
val jest: JestClient = getClient
//Builder中的参数,底层会转换为Json格式字符串,所以我们这里封装Document为样例类
//当然也可以直接传递json
val actorNameList = new util.ArrayList[String]()
actorNameList.add("zhangsan")
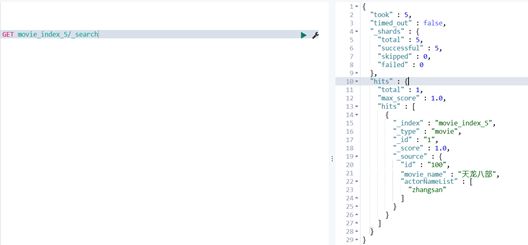
val index: Index = new Index.Builder(Movie("100","天龙八部",actorNameList))
.index("movie_index_5")
.`type`("movie")
.id("1")
.build()
//execute的参数类型为Action,Action是接口类型,不同的操作有不同的实现类,添加的实现类为Index
jest.execute(index)
//关闭连接
jest.close()
}
case class Movie(id:String ,movie_name:String, actorNameList: java.util.List[String] ){}
//测试查看效果
def main(args: Array[String]): Unit = {
putIndex()
}
构造者设计模式参考:
6.4 从ES中查询数据
//从ES中查询数据
def queryIndex(): Unit ={
//获取操作对象
val jest: JestClient = getClient
//查询常用有两个实现类 Get通过id获取单个Document,以及Search处理复杂查询
val query =
"""
|{
| "query": {
| "bool": {
| "must": [
| {"match": {
| "name": "red"
| }}
| ],
| "filter": [
| {"term": { "actorList.name.keyword": "zhang cuishan"}}
| ]
| }
| },
| "from": 0,
| "size": 20,
| "sort": [
| {
| "doubanScore": {
| "order": "desc"
| }
| }
| ],
| "highlight": {
| "fields": {
| "name": {}
| }
| }
|}
""".stripMargin
val search: Search = new Search.Builder(query)
.addIndex("movie_index")
.build()
//执行操作
val result: SearchResult = jest.execute(search)
//获取命中的结果 sourceType:对命中的数据进行封装,因为是Json,所以我们用map封装
//注意:一定得是Java的Map类型
val rsList: util.List[SearchResult#Hit[util.Map[String, Any], Void]] = result.getHits(classOf[util.Map[String,Any]])
//将Java转换为Scala集合,方便操作
import scala.collection.JavaConverters._
//获取Hit中的source部分
val list: List[util.Map[String, Any]] = rsList.asScala.map(_.source).toList
println(list.mkString("\n"))
//关闭连接
jest.close()
}
以上拼接字符串的查询操作可以用下面语句代替
//通过SearchSourceBuilder构建查询语句
val sourceBuilder: SearchSourceBuilder = new SearchSourceBuilder
val boolQueryBuilder = new BoolQueryBuilder
boolQueryBuilder.must(new MatchQueryBuilder("name","red"))
boolQueryBuilder.filter(new TermQueryBuilder("actorList.name.keyword","zhang cuishan"))
sourceBuilder.query(boolQueryBuilder)
sourceBuilder.from(0)
sourceBuilder.size(20)
sourceBuilder.sort("doubanScore",SortOrder.DESC)
sourceBuilder.highlighter(new HighlightBuilder().field("name"))
val query2 = sourceBuilder.toString
如果报日志相关错误:
在pom.xml中添加下面依赖
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-to-slf4jartifactId>
<version>2.11.0version>
dependency>