scrapy部署分布式爬虫
首先需要下载redis数据库和Redis数据可的可视化工具,将redis数据库设置为远程连接
- 打开该文件,修改里面的配置信息

- 修改该值为主机IP地址

关闭保护模式(将yes改为no)

- 如果电脑中服务已经存在redis服务,需要将redis服务卸载之后,重新启动,并设置为自启。
相关的redis命令如下:
a> 安装服务
redis-server --service-install redis.windows-service.conf --loglevel verbose
b> 启用服务
redis-server --service-start
c> 停止使用redis服务
redis-server --service-stop
d> 卸载redis相关服务
redis-server --service-uninstall - 服务问题解决后,接下来需要运行指令

- 接下来咱们配置MySQL数据库,首先需要安装MySQL相关程序以及服务,并且创建root用户。由于root用户只能连接localhost,所以需要通过root用户创建一个具有一定权限的新用户,用来建立远程的数据库连接。
创建新用户的相关指令以及操作:
a> 创建新用户
create user "数据库用户名称"@"%" identified by "用户密码";(一定不要忘记语句末尾的英文分号)
b> 给新用户授予权限
GRANT ALL PRIVILEGES ON *.* TO '用户名'@'host名称(即主机IP地址)';
c> 刷新权限
FLUSH PRIVILEGES;
d> 接下来进入到windows服务中重启MySQL服务即可
可以进入到Navicat中测试远程连接是否生效(下图)

测试成功之后,点击确定,创建MySQL连接
6. 修改爬虫文件
由于分布式爬虫需要部署在多台电脑上,所以起始的url就不能写在某一台电脑的start_urls中,需要指定一个redis_key这个字段用来在redis中写入爬虫文件所需要的第一个url
redis_key这个字段命名规则
redis_key = "任意的字符串:start_urls"
7. 修改settinfs文件
更换scrapy内置的调度器文件,使用scrapy-redis包中的scheduler调度器文件
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
更换scrapy内置的去重文件,使用scrapy-redis包中的dupefilter文件
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
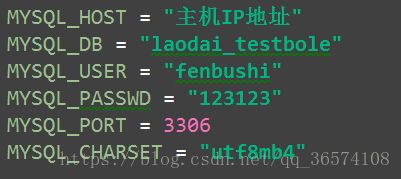
配置远程主机的连接地址
# 配置REDIS_URL = '(redis://redis数据库用户(默认是root):redis数据库连接密码(默认为空))@(redis的连接地址):(redis的端口号)'
REDIS_URL = 'redis://root:@远程主机IP地址:6379'
如果为异步存储数据库,如下图
如果为同步存储,如下图
![]()
当所有配置完成之后,拷贝文件到其它电脑上,然后点击main函数运行,此时程序所有电脑程序应处于等待状态(等待redis接收第一个url)
接下来进入到redis安装目录

接下里进入到cmd命令中输入 redis-cli.exe -h 主机IP地址

然后输入 lpush key value [value…]
使用redis_key的值替换key ,要爬取的第一个url替换value
然后回车,程序已经跑起来了!!!
存入的部分数据
