1. 技术背景—FaceBook页面加载技术
试想这样一个场景,一个经常访问的网站,每次打开它的页面都要要花费6秒;同时另外一个网站提供了相似的服务,但响应时间只需3 秒,那么你会如何选择呢?数据表明,如果用户打开一个网站,等待3~4 秒还没有任何反应,他们会变得急躁,焦虑,抱怨,甚至关闭网页并且不再访问,这是非常糟糕的情况。所以,网页加载的速度十分重要,尤其对于拥有遍布全球的5亿用户的Facebook(全球最大的社交服务网站)这样的大型网站,有着大量并发请求、海量数据等客观情况,速度就成了必须攻克的难题之一。
2010年初的时候,Facebook 的前端性能研究小组开始了他们的优化项目,经过了六个月的努力,成功的将个人空间主页面加载耗时由原来的5 秒减少为现在的2.5 秒。这是一个非常了不起的成就,也给用户来带来了很好的体验。在优化项目中,工程师提出了一种新的页面加载技术,称之为Bigpipe。目前淘宝和Facebook面临的问题非常相似:海量数据和页面过大,如果可以在详情页、列表页中使用bigpipe,或者在webx中集成bigpipe,将会带来明显的页面加载速度提升。
2. 相关介绍
2.1 网站前端优化的重要性
《高性能网站建设指南》一书中指出,只有10%~20%的最终用户响应时间是花费在从Web服务器获取HTML文档并传送到浏览器中的。如果希望能够有效地减少页面的响应时间,就必须关注剩余的80%~90%的最终用户体验。做个比较,如果对后台业务逻辑进行优化,效率提高了50%,但最终的页面响应时间只减少了5%~10%,因为它所占的比重较少。如果对前端进行性能优化,效率提升50%,则会使最终页面响应时间减少40%~45%。这是多么可观的数字!另外,前端的性能优化一般比业务逻辑的优化更加容易。所以,前端优化投入小,见效快,性价比极高,需要投入更多的关注。
2.2 BigPipe与AJAX
Web2.0的重要特征是网页显示大量动态内容,即web2.0注重网页与用户的交互。其核心技术是AJAX,如今所有主流网站都或多或少使用AJAX。与AJAX类似,BigPipe实现了分块儿的概念,使页面能够分步输出,即每次输出一部分网页内容。接下来讨论BigPipe与AJAX的区别。
简单的说,BigPipe比AJAX有三个好处:
1. AJAX 的核心是XMLHttpRequest,客户端需要异步的向服务器端发送请求,然后将传送过来的内容动态添加到网页上。如此实现存在一些缺陷,即发送往返请求需要耗费时间,而BigPipe技术使浏览器并不需要发送XMLHttpRequest请求,这样就节省时间损耗。
2. 使用AJAX时,浏览器和服务器的工作顺序执行。服务器必须等待浏览器的请求,这样就会造成服务器的空闲。浏览器工作时,服务器在等待,而服务器工作时,浏览器在等待,这也是一种性能的浪费。使用BigPipe,浏览器和服务器可以并行同时工作,服务器不需要等待浏览器的请求,而是一直处于加载页面内容的工作阶段,这就会使效率得到更大的提高。
3. 减少浏览器发送到请求。对一个5亿用户的网站来说,减少了使用AJAX额外带来的请求,会减少服务器的负载,同样会带来很大的性能提升。
基于以上三点,Facebook 在进行页面优化时采用了BigPipe技术。目前淘宝主搜索结果页中,需要加载类目,相关搜索,宝贝列表,广告等内容,前端这里使用php的curl的批处理来并发的访问引擎获取相应的数据,并进行分步输出。这种模式还是与bigpipe有些不同,这点后面会讲到。一般来讲,在页面比较大,而且比较复杂,样式表和脚本比较多的情况下,使用BigPipe来优化输出页面是比较合适的。另外非常重要的一点,BigPipe并不改变浏览器的结构与网络协议,仅使用JS就可以实现,用户不需要做任何的设置,就会看到明显的访问时间缩短。
3. 目前的问题
接下来讨论现有的瓶颈。面对网页越来越大的情况,尤其是大量的css文件和js文件需要加载,传统的页面加载模型很难满足这样的需求,直接结果就是页面加载速度变慢,这绝不是我们希望看到的。目前的技术实现中,用户提出页面访问请求后,页面的完整加载流程如下:
1. 用户访问网页,浏览器发送一个HTTP请求到网络服务器。
2. 服务器解析这个请求,然后从存储层取数据,接着生成一个html文件内容,并在一个HTTP Response中把它传送给客户端。
3. HTTP response在网络中传输。
4. 浏览器解析这个Response ,创建一个DOM树,然后下载所需的CSS和JS文件。
5. 下载完CSS 文件后,浏览器解析他们并且应用在相应的内容上。
6. 下载完JS 后,浏览器解析和执行他们
 图1
图1
完整流程见图1。图中左侧表示服务器,右侧表示浏览器。浏览器先发送请求,然后服务器进行查找数据,生成页面,返回html代码,最后浏览器进行渲染页面。这种模式有非常明显的缺陷:流程中的操作有着严格的顺序,如果前面的一个操作没有执行结束,后面的操作就不能执行,即操作之间是不能重叠。这样就造成性能的瓶颈:服务器生成一个页面的内容时,浏览器是空闲的,显示空白内容;而当浏览器加载渲染页面内容时,服务器又是空闲的,时间与性能的浪费由此产生。
 图2
图2
考虑图2中现有的服务模型,横轴表示花费的时间。黄色表示在服务器的生成页面内容的时间,白色表示网络传输时间,蓝色表示在浏览器渲染页面的时间。可以看出,现有的模式造成很大的时间浪费。考虑图3中的情况,图中绿色表示服务器从春储层取查数据花费的时间,在海量数据下,当执行一条很费时的查询语句时(如下图右侧),服务器就就阻塞在那里没有其他操作,而浏览器更是得不到任何反馈。这会造成非常不友好的用户体验,用户不知道什么原因使他们等待很长时间。
 图3
图3
4. BigPipe思想与原理
面对上述问题,我们看下BigPipe的解决办法。BigPipe提出分块的概念,即根据页面内容位置的不同,将整个页面分成不同的块儿—称为pagelet。该技术的设计者Changhao Jiang是研究电子电路的博士,可能从微机上得到了启发,将众多pagelet加载的不同阶段像流水线一样在浏览器和服务器上执行,这样就做到了浏览器和服务器的并行化,从而达到重叠服务器端运行时间和浏览器端运行时间的目的。使用BigPipe不仅可以节省时间,使加载的时间缩短,而且可以同过pagelet的分步输出,使一部分的页面内容更快的输出,从而获得更好的用户体验。BigPipe中,用户提出页面访问请求后,页面的完整加载流程如下:
1. Request parsing:服务器解析和检查http request
2. Datafetching:服务器从存储层获取数据
3. Markup generation:服务器生成html 标记
4. Network transport : 网络传输response
5. CSS downloading:浏览器下载CSS
6. DOM tree construction and CSS styling:浏览器生成DOM 树,并且使用CSS
7. JavaScript downloading: 浏览器下载页面引用的JS文件
8. JavaScript execution: 浏览器执行页面JS代码
这个8 个流程几乎与上文中提到现有的模式没有区别,但这整个流程只是一个pagelet 的完整流程,而多个pagelet 的不同操作阶段就可以像流水线一样进行执行了。
 图4
图4
图4 中,可以看出BigPipe对原有的模式进行的改进。浏览器发送访问请求,然后浏览器分步返回不同的pagelet的内容,具体实现将在后面介绍。考虑图5中的改进,BigPipe 打破了原有的顺序执行,将页面分成不同的pagelet ,如此一来,所有的pagelet 的执行时间累加起来还是原有的时间。但是, 通过叠加不同pagelet 的不同阶段的执行时间,使总的运行时间大大减少,这就是Bigpipe减少页面加载时间的秘密。
FaceBook的页面被分成了很多不同的pagelets,如图:
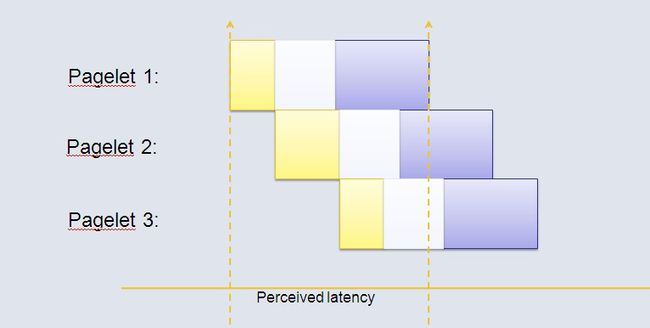 图5
图5
5. BigPipe实现原理
了解了BigPipe 的核心思想后,我们讨论它的实现原理。当浏览器访问服务器时,服务器接受请求并对其进行检查。如果请求有效,服务器端不做任何的查询,而是立刻返回一个http response给浏览器,内容是一段html代码,包括html
标签和 标签的一部分。标签包括BigPipe的js文件和css文件,这个js文件用来解析后面接收的http response,因为后面传输的内容都为js脚本。未封闭的标签中,是显示页面的逻辑结构和pagelet 的占位符的模板,例如:
<
body
>
<
div
>
div
>
<
div
>
div
>
<
div
>
div
>
<
div
>
<
div
>
<
div
id
=”hotnews”
>
div
>
<
div
id
=”societynews”
>
div
>
<
div
id
=”financialnews”
>
div
>
<
div
id
=”ITnews”
>
div
>
<
div
id
=”sportsnews”
>
div
>
div
>
<
div
>
div
>
div
>
<
div
>
div
>
<
script type
=
”text
/
javascript”>
big_pipe.onPageletArrive(
{id:”pagelet_composer”,
content:”
<
HTML
>
”,
css:”[..]“,
js:”[..]“,
…}
);
<
/
script>
虽然每个pagelet都有要加载的js 文件,但是所有的js文件都是在最后加载,这样有利于加快页面加载速度。客户端,当通过调用“onPageletArrive(json)”函数,第一次影响传输的JS脚本中的函数解析了传入的json数据,接着下载需要的CSS,然后把html内容显示到响应的div标签位置上。多个pagelets 的CSS文件可以同时下载,CSS 下载完成的pagelet先显示。
在BigPipe中,js被给予了比CSS和content更低的优先级。这样, 只有当所有的pagelets都显示了,BigPipe才开始去下载JS文件。所有的JS 文件都下载完成后,Pagelets的JS初始化代码开始执行,按照下载完成时间的先后顺序。在这个高度并行的系统中,几个的pagelet 所要执行的不同的阶段可以同时执行。例如,浏览器可以给两个pagelets下载CSS 资源,同时浏览器可以渲染另外一个pagelet 的内容,同时服务器仍然在为另一个pagelet生成html源码。从用户的角度看来,页面是逐步呈现的。初始的页面显示的更快,可以有效减短用户感觉到的延迟。
6. BigPipe实现问题讨论
6.1 服务器端的并行化
理想情况下,服务器端的实现是并行处理不同的pagelet 的内容,这样可以提升性能。服务器并发处理多个pagelet的内容时,一个pagelet内容生成好了,立刻将其flush给浏览器。但是PHP是不支持线程,所以服务器无法利用多线程的概念去并发的加载多个pagelet 的内容。对于小型网站来说,使用串行的加载pagelet的内容就已经可以达到优化的要求了。对于大型网站,为了达到更快的速度,服务器端可以选择并发的独立不同的pagelet 的内容,具体实现有以下几种方式:
1. java 多线程。后台逻辑使用java,可以使用java的多线程机制去同时加载不同的pagelet 的内容,加载完成后加页面内容返回给浏览器。在最后的引用部分可以看到网上用java多线程实现的例子。
2. 使用PHP实现。PHP不支持线程,无法像java使用多线程的机制来并发处理不同pagelet的内容。但是,Facebook 和淘宝主搜索的业务逻辑是用PHP实现的,所以我们必须考虑如何在PHP下完成并发处理。PHP 扩展中有curl 模块,可以在该模块中curl_multi_fetch()函数进行批处理请求,把本来应该串行的请求访问并发的执行。可以这样写:
do
{
$mrc
=
curl_multi_exec(
$mh
,
$active
);
}
while
(
$mrc
==
CURLM_CALL_MULTI_PERFORM);
while
(
$active
&
amp;
&
amp;
$mrc
==
CURLM_OK){
if
(curl_multi_select(
$mh
)
!=
-
1
){
do
{
$mrc
=
curl_multi_exec(
$mh
,
$active
);
}
while
(
$mrc
==
CURLM_CALL_MULTI_PERFORM);
}
}
while
(
count
(
$sockets
)) {
$read
=
$write
=
$sockets
;
$n
=
stream_select
(
$read
,
$write
,
$e
,
$timeout
);
if
(
$n
&
gt;
0
) {
foreach
(
$read
as
$r
) {
$id
=
array_search
(
$r
,
$sockets
);
$data
=
fread
(
$r
,
8192
);
if
(
strlen
(
$data
)
==
0
) {
fclose
(
$r
);
unset
(
$sockets
[
$id
]);
}
else
{
$retdata
[
$id
]
.=
$data
;
}
}
$retdata
[
$id
]
=
preg_replace
(
'
/^HTTP(.*?)\r\n\r\n/is
'
,<
em
>,
$retdata
[
$id
]);
em
>
foreach
(
$write
as
$w
) {
if
(
!
is_resource
(
$w
))
continue
;
$id
=
array_search
(
$w
,
$sockets
);
fwrite
(
$w
,
"
GET /
"
.
$url
[
$id
]
.
"
HTTP/1.0\r\nHost:
"
.
$hosts
[
$id
]
.
"
\r\n\r\n
"
);
$status
[
$id
]
=
1
;
}
}
else
{
break
;
}
}
6.2 直接调用flush函数输出
到这里,可能会有这样的疑问,为什服务器不直接把生成好的HTML内容分部flush()返回给客户端,而是使用json 格式传递,然后用js解析呢?这不是多此一举么?实际上,这也是目前主搜索前端使用的方法。我们看看使用BigPipe方式的两大好处:
(1) 如果直接调用flush()函数输出html 源码,当模块较多的情况,模块间必须按顺序加载,在html 前面的模块必须先加载完,后面的才能加载,这样也就没办法每个模块同时显示一些内容。例如下面的html:
上面3 个div分别代表3个模块,如果直接分部输出html ,服务器端必须先加载完毕div1模块中的内容并flush 出去后,才能继续加载div2的内容,如果flush 顺序不一样,输出的html 结构肯定就会出问题,这样就导致前台页面没办法同时显示3 个loading。因为这样flush必须要有先后顺序。而如果采用JS的话,可以前台显示3 个loading,而且不需要关心到底哪个模块先加载完,这样还能发挥后台多线程处理数据的优势。
(2) 使用JS这种方式可以是页面结构更加清晰,管理更加方便。同时做到了页面逻辑结构和数据解耦,首先返回的是页面的结构,接着不断地返回js脚本,然后动态添加页面内容,而不是所有完整的html源码一起输出,增加了可维护性。
6.3 访问者是爬虫或者访问者浏览器禁止使用JS的情况
我们知道BigPipe使用js 脚本加载页面,那么当用户在浏览器里设置禁止使用js脚本(虽然人数很少),就会造成加载页面失败,这同样是非常不好的用户体验。对搜索引擎的爬虫来讲,同样会遇到类似的问题。解决办法是当用户发送访问请求时,服务器端检测user-agent和客户端是否支持js脚本。如果user-agent显示是一个搜索引擎爬虫或者客户端不支持js,就不使用BigPipe ,而用原有的模式,从而解决问题。
6.4 对SEO的影响
这是一个必须考虑的问题,如今是搜索引擎的时代,如果网页对搜索引擎不友好,或者使搜索引擎很难识别内容,那么会降低网页在搜索引擎中的排名,直接减少网站的访问次数。在BigPipe中,页面的内容都是动态添加的,所以可能会使搜索引擎无法识别。但是正如前面所说,在服务器端首先要根据user-agent判断客户端是否是搜索引擎的爬虫,如果是的话,则转化为原有的模式,而不是动态添加。这样就解决了对搜索引擎的不友好。
6.5 融合其他技术
除了使用BigPipe,Facebook的页面加载技术还融合了其他的页面优化技术,具体如下:
6.5.1 资源文件的G-zip压缩
这是非常重要的技术,使用G-zip对css和js文件压缩可以使大小减少70%,这是多么诱人的数字!在网络传输的文件中,主要就是样式表和脚本文件。如此可以大大减小传输的内容,使页面加载速度变得更快。具体实现可以借助服务器来进行,例如Apache,使用mod_deflate模块来完成具体配置为: AddOutputFilterByType DEFLATE text/html text/css application/xjavascript
6.5.2 将js文件进行了精简
对js文件进行精简,可以从代码中移除不必要的字符,注释以及空行以减小js文件的大小,从而改善加载的页面的时间。精简js 脚本的工具可以使用JSMin,使用精简后的脚本的大小会减少20%左右。这也是一个很大的提升。
6.5.3 将css和js文件进行合并
这是前端优化的一项原则,将多个样式表和js文件进行合并,这样的话,将会减少http的请求个数。对于上亿用户的网站来说,这也会带来性能的提升,大约会减少5%左右的时间损耗。
6.5.4 使用外部JS和CSS
同样是前端优化的一项原则。纯粹就速度来言,使用内联的js和css速度要更快,因为减少了http请求。但是,使用外部的文件更有利于文件的复用,这与面向对象编程的概念很像。更为重要的是,虽然在第一次的加载速度慢一点,但css文件和js脚本是可以被浏览器缓存。即之后用户的多次访问中,使用外部的js和css将会将会更好的提升速度。
6.5.5 将样式表放在顶部
和上面内容相似,这也是一种规范,将html 内容所需的css 文件放在首部加载是非常重要的。如果放在页面尾部,虽然会使页面内容更快的加载(因为将加载css文件的时间放在最后,从而使页面内容先显示出来),但是这样的内容是没有使用样式表的,在css 文件加载进来后,浏览器会对其使用样式表,即再次改变页面的内容和样式,称之为“无样式内容的闪烁”,这对于用户来说当然是不友好的。实现的时候将css文件放在
标签中即可。6.5.6 将脚本放在底部实现“barrier”
支持页面动态内容的Js脚本对于页面的加载并没有什么作用,把它放在顶部加载只会使页面更慢的加载,这点和前面的提到的css文件刚好相反,所以可以将它放在页尾加载。是用户能看到的页面内容先加载,js文件最后加载,这样会使用户觉得页面速度更快。Bigpipe实现一个“barrier”的概念,即当所有的pagelet的内容全部加载好了之后,浏览器再向服务器发送js的http请求。可以在BigPipe.js 中将所有的pagelet 所需的js文件的路径保存下来,在判断所有的内容加载完成后统一向服务器发送请求。
7. BigPipe具体实现细节
如上文讨论的那样,具体实现如下:当用户访问该页面时,在第一个flush的Response内容中,返回大部分的HTML代码,包括完整的
var
bigPipe
=
new
bigPipe();
bigPipe.setResourceMap({
aaaaa:{
“name”: “js
/
list1.js”,
“type”: “js”,
“src”: “js
/
list1.js”
}
);
setResourceMap(json)为BigPipe 中的函数,功能是设置文件的映射。”aaaaa”应该是在服务器随即生成的五位字符串,name表示文件名称,type为文件的类型,可以是”js”或”css”,”src”为文件的路径。在下面的页面中,就可以使用”aaaaa”来替代”js/list1.js”了,减少了复杂性。接下来flush 的是每一个pagelet 的内容了,例如:
<
script type
=
”text
/
javascript” >
bigPipe.onPageletArrive({
id:”list1″,
content:”
this
is list
1
<
\
/
br> ”,
”,
css:[
"
eeeee
"
],
js:[
"
aaaaa
"
],
“resource_map”:{
aaaaa:{
“name”: “js
/
list1.js”,
“type”: “js”,
“src”: “js
/
list1.js”
} ,
“eeeee”: {
“name”: “css
/
list1.css”,
“type”: “css”
“src”: “css
/
list1.css”
}
}
});
<
/
script>
onPageletArrive(json_arrive)也是BigPipe 的函数,功能是动态添加页面的内容和加载pagelet 所需的文件,函数的参数为json格式的数据。其参数含义是:“id”用来寻找pagelet 标签;“content”是html 页面内容,在找到对应的pagelet的标签之后,将content内动态添加到html页面中;“css”为该Pagelet 所需的css文件,这里的css文件可能在之前导入过了;“js”为该pagelet所需的js文件,同样,有可能在之前的pagelet已经导入过了。在函数实现过程中,因为js文件是最后加载的,可以把这些js的路径存入到一个数组当中(去掉重复的),在最后一起加载。resource_map”为该pagelet 所单独需要加载的js和css文件,同样也是json格式的,结构与前面的setResource()中的参数一样。最后flush的是:
body
>
html
>
即为最后的标签。
8. 结论
经过上面的讨论,我们可以发现,使用BigPipe技术优化页面可以有四个好处:
1.减少页面的加载时间。
2.使页面分步输出,改善用户体验。
3.使页面结构化,提高可读性,更加便于维护。
4.每个pagelet都是相互独立的,如果有一个pagelet的内容不能加载,并不会影响其他的pagelet的内容显示。
同时,BigPipe是一项比较新的理念, 在去年六月份才由Facebook的工程师提出,应该说有很大的发展空间。BigPipe 的原理非常简单,并不会引入很多额外的负担,适用范围很广,容易上手。几乎所有的网页都可以采用BigPipe的理念去进行优化,尤其对于是有着海量数据和网页比较大的网站,将会以低成本带来高回报。一般来讲,网站越大,脚本和样式表越多,浏览器版本越旧,网络环境越差,优化的结果越可观。
9. 引用与参考资料
1. 作者的博客:http://www.facebook.com/note.php?note_id=389414033919
2. bigpipe技术的ppt:http://twork.taobao.net/books/237
3. bigpipe的java实现:http://codemonkeyism.com/facebook-bigpipe-java/
4. 一篇介绍bigpipe的文章:http://www.54chen.com/architecture/rose-pipe-http-54chen.html
5. 另一篇挺有用的文章:http://www.cnblogs.com/BearsTaR/archive/2010/06/18/facebook_html_chunk.html
6. 人人网类似bigpipe的技术–rosepipe:http://www.54chen.com/architecture/rose-open-source-portal-framework.html
7.《高性能网站建设指南》by Steve Souder, Copyright 2007 Steve Sounder, 978-0-596- 52930-7。