CNN与LeNet的应用-数字手写体识别
一、基本介绍
(一)卷积神经网络
- 卷积层是卷积神经网络的核心基石。在图像识别里我们提到的卷积是二维卷积,即离散二维滤波器(也称作卷积核)与二维图像做卷积操作,简单的讲是二维滤波器滑动到二维图像上所有位置,并在每个位置上与该像素点及其领域像素点做内积。卷积操作被广泛应用与图像处理领域,不同卷积核可以提取不同的特征,例如边沿、线性、角等特征。在深层卷积神经网络中,通过卷积操作可以提取出图像低级到复杂的特征。
- 一个卷积神经网络由若干卷积层、Pooling层、全连接层组成。
卷积神经网络的主要组成:
卷积层(Convolutional layer),卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
采样层(Pooling),它实际上一种形式的向下采样。下采样的目的是为了降低网络训练参数及模型的过拟合程度。下采样层的池化方式通常有两种:最大值池化和均值池化。
全连接层(Full connection), 与普通神经网络一样的连接方式,一般都在最后几层。 - 卷积的计算:
这里的蓝色矩阵就是输入的图像,粉色矩阵就是卷积层的神经元,这里表示了有两个神经元(w0,w1)。绿色矩阵就是经过卷积运算后的输出矩阵,这里的步长设置为2。灰色部分为填充部分。蓝色的矩阵(输入图像)对粉色的矩阵(filter)进行矩阵内积计算并将三个内积运算的结果与偏置值b相加,计算后的值就是绿框矩阵的一个元素。
 参考文章:
参考文章:
https://blog.csdn.net/happyorg/article/details/78274066
https://cuijiahua.com/blog/2018/01/dl_3.html
(二)LeNet
- LeNet是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。
- LeNet共有7层(输入层不算在网络结构中),每层都包含不同数量的训练参数,如下图所示。
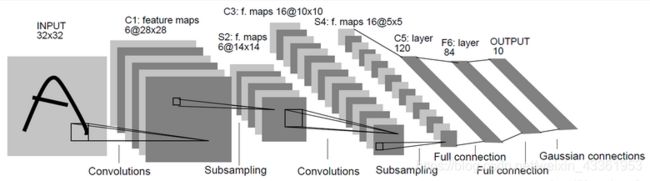 (1) 输入层为3232图像,一般限定字符最大范围为2020
(1) 输入层为3232图像,一般限定字符最大范围为2020
(2)C1:卷积层为6副28×28的特征图。C1层具有如下特点:
拓扑结构:输入层相邻节点卷积后仍然相邻
稀疏连接:每个像素仅与输入层的相邻结点相连
权值共享:同一副特征图共享相同的卷积核
C1层神经元连接数量为28 * 28* (5*5+1) * 6=122304,由于采用了权值共享,
因此待学习参数为(5 * 5+1) * 6=156。如果采用全连接策略,总参数量可达(32 * 32+1) * (28 * 28) * 6,参数数量太多。
减少了参数数量也是卷积神经网络的一个优点,每个神经元不再和上一层的所有神经元相连,而只和一小部分神经元相连,这样就减少了很多参数。
(3)S2:Pooling层将28 * 28的特征图将采样为14 * 14的图像
(4)C3:将6副28 * 28的特征图卷积为16副10 * 10的图像,卷积核为5 * 5
(5)S4:将10 * 10的特征图将采样为16副5 * 5的图像
(6)C5:将16副5 * 5的特征图卷积为长度为120的向量
(7)F6:构建84个神经元,每个神经元与C5的120个神经元全连接
具体可以参考:https://cuijiahua.com/blog/2018/01/dl_3.html
(二)分析与结果
(一)训练
- MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据。
- 下载地址:http://yann.lecun.com/exdb/mnist/
- 这次使用TensorFlow作为框架,它是Google的深度学习框架,TensorBoard可视化很方便,数据和模型并行化好,速度快。我装的是GPU版本,运行起来几秒就可以,但是GPU版本的安装可能会有问题,安装失败可以改用CPU版本,只是CPU版本运行起来速度会慢许多。
- 代码:
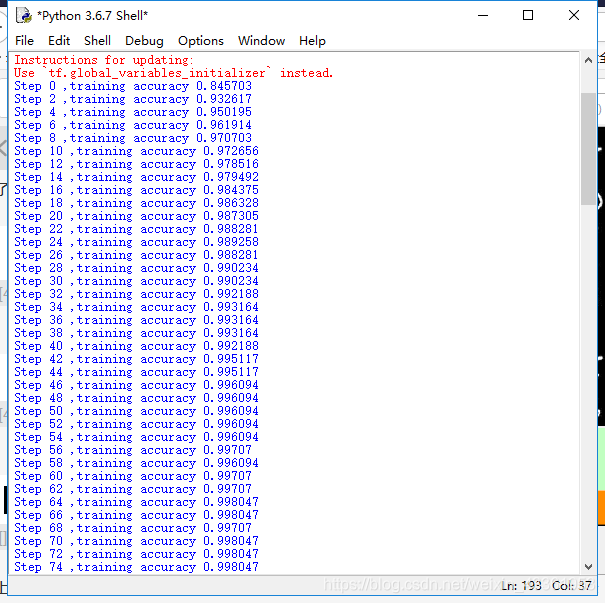
以图片形式训练,我跑起来花了一小时还没跑完,CPU大概会跑更久。
#coding:utf8
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
sess = tf.InteractiveSession()
def getTrain():
train=[[],[]] # 指定训练集的格式,一维为输入数据,一维为其标签
# 读取所有训练图像,作为训练集
train_root="mnist_train"
labels = os.listdir(train_root)
for label in labels:
imgpaths = os.listdir(os.path.join(train_root,label))
for imgname in imgpaths:
img = cv2.imread(os.path.join(train_root,label,imgname),0)
array = np.array(img).flatten() # 将二维图像平铺为一维图像
array=MaxMinNormalization(array)
train[0].append(array)
label_ = [0,0,0,0,0,0,0,0,0,0]
label_[int(label)] = 1
train[1].append(label_)
train = shuff(train)
return train
def getTest():
test=[[],[]] # 指定训练集的格式,一维为输入数据,一维为其标签
# 读取所有训练图像,作为训练集
test_root="mnist_test"
labels = os.listdir(test_root)
for label in labels:
imgpaths = os.listdir(os.path.join(test_root,label))
for imgname in imgpaths:
img = cv2.imread(os.path.join(test_root,label,imgname),0)
array = np.array(img).flatten() # 将二维图像平铺为一维图像
array=MaxMinNormalization(array)
test[0].append(array)
label_ = [0,0,0,0,0,0,0,0,0,0]
label_[int(label)] = 1
test[1].append(label_)
test = shuff(test)
return test[0],test[1]
def shuff(data):
temp=[]
for i in range(len(data[0])):
temp.append([data[0][i],data[1][i]])
import random
random.shuffle(temp)
data=[[],[]]
for tt in temp:
data[0].append(tt[0])
data[1].append(tt[1])
return data
count = 0
def getBatchNum(batch_size,maxNum):
global count
if count ==0:
count=count+batch_size
return 0,min(batch_size,maxNum)
else:
temp = count
count=count+batch_size
if min(count,maxNum)==maxNum:
count=0
return getBatchNum(batch_size,maxNum)
return temp,min(count,maxNum)
def MaxMinNormalization(x):
x = (x - np.min(x)) / (np.max(x) - np.min(x))
return x
# 1、权重初始化,偏置初始化
# 为了创建这个模型,我们需要创建大量的权重和偏置项
# 为了不在建立模型的时候反复操作,定义两个函数用于初始化
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)#正太分布的标准差设为0.1
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
# 2、卷积层和池化层也是接下来要重复使用的,因此也为它们定义创建函数
# tf.nn.conv2d是Tensorflow中的二维卷积函数,参数x是输入,w是卷积的参数
# strides代表卷积模块移动的步长,都是1代表会不遗漏地划过图片的每一个点,padding代表边界的处理方式
# padding = 'SAME',表示padding后卷积的图与原图尺寸一致,激活函数relu()
# tf.nn.max_pool是Tensorflow中的最大池化函数,这里使用2 * 2 的最大池化,即将2 * 2 的像素降为1 * 1的像素
# 最大池化会保留原像素块中灰度值最高的那一个像素,即保留最显著的特征,因为希望整体缩小图片尺寸
# ksize:池化窗口的大小,取一个四维向量,一般是[1,height,width,1]
# 因为我们不想再batch和channel上做池化,一般也是[1,stride,stride,1]
def conv2d(x, w):
return tf.nn.conv2d(x, w, strides=[1,1,1,1],padding='SAME') # 保证输出和输入是同样大小
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1],padding='SAME')
iterNum = 1000
batch_size=1024
print("load train dataset.")
train=getTrain()
print("load test dataset.")
test0,test1=getTest()
# 3、参数
# 这里的x,y_并不是特定的值,它们只是一个占位符,可以在TensorFlow运行某一计算时根据该占位符输入具体的值
# 输入图片x是一个2维的浮点数张量,这里分配给它的shape为[None, 784],784是一张展平的MNIST图片的维度
# None 表示其值的大小不定,在这里作为第1个维度值,用以指代batch的大小,means x 的数量不定
# 输出类别y_也是一个2维张量,其中每一行为一个10维的one_hot向量,用于代表某一MNIST图片的类别
x = tf.placeholder(tf.float32, [None,784], name="x-input")
y_ = tf.placeholder(tf.float32,[None,10]) # 10列
# 4、第一层卷积,它由一个卷积接一个max pooling完成
# 张量形状[5,5,1,32]代表卷积核尺寸为5 * 5,1个颜色通道,32个通道数目
w_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32]) # 每个输出通道都有一个对应的偏置量
# 我们把x变成一个4d 向量其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(灰度图的通道数为1,如果是RGB彩色图,则为3)
x_image = tf.reshape(x,[-1,28,28,1])
# 因为只有一个颜色通道,故最终尺寸为[-1,28,28,1],前面的-1代表样本数量不固定,最后的1代表颜色通道数量
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1) # 使用conv2d函数进行卷积操作,非线性处理
h_pool1 = max_pool_2x2(h_conv1) # 对卷积的输出结果进行池化操作
# 5、第二个和第一个一样,是为了构建一个更深的网络,把几个类似的堆叠起来
# 第二层中,每个5 * 5 的卷积核会得到64个特征
w_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2)# 输入的是第一层池化的结果
h_pool2 = max_pool_2x2(h_conv2)
# 6、密集连接层
# 图片尺寸减小到7 * 7,加入一个有1024个神经元的全连接层,
# 把池化层输出的张量reshape(此函数可以重新调整矩阵的行、列、维数)成一些向量,加上偏置,然后对其使用Relu激活函数
w_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1,7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1)
# 7、使用dropout,防止过度拟合
# dropout是在神经网络里面使用的方法,以此来防止过拟合
# 用一个placeholder来代表一个神经元的输出
# tf.nn.dropout操作除了可以屏蔽神经元的输出外,
# 还会自动处理神经元输出值的scale,所以用dropout的时候可以不用考虑scale
keep_prob = tf.placeholder(tf.float32, name="keep_prob")# placeholder是占位符
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 8、输出层,最后添加一个softmax层
w_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2) + b_fc2, name="y-pred")
# 9、训练和评估模型
# 损失函数是目标类别和预测类别之间的交叉熵
# 参数keep_prob控制dropout比例,然后每100次迭代输出一次日志
cross_entropy = tf.reduce_sum(-tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 预测结果与真实值的一致性,这里产生的是一个bool型的向量
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
# 将bool型转换成float型,然后求平均值,即正确的比例
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 初始化所有变量,在2017年3月2号以后,用 tf.global_variables_initializer()替代tf.initialize_all_variables()
sess.run(tf.initialize_all_variables())
# 保存最后一个模型
saver = tf.train.Saver(max_to_keep=1)
for i in range(iterNum):
for j in range(int(len(train[1])/batch_size)):
imagesNum=getBatchNum(batch_size,len(train[1]))
batch = [train[0][imagesNum[0]:imagesNum[1]],train[1][imagesNum[0]:imagesNum[1]]]
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
if i % 2 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1],keep_prob: 1.0})
print("Step %d ,training accuracy %g" % (i, train_accuracy))
print("test accuracy %f " % accuracy.eval(feed_dict={x: test0, y_:test1, keep_prob: 1.0}))
# 保存模型于文件夹
saver.save(sess,"save/model")
以包的形式训练,我跑起来花了半分钟。
import tensorflow as tf
import numpy as np # 习惯加上这句,但这边没有用到
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)
sess = tf.InteractiveSession()
# 1、权重初始化,偏置初始化
# 为了创建这个模型,我们需要创建大量的权重和偏置项
# 为了不在建立模型的时候反复操作,定义两个函数用于初始化
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)#正太分布的标准差设为0.1
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
# 2、卷积层和池化层也是接下来要重复使用的,因此也为它们定义创建函数
# tf.nn.conv2d是Tensorflow中的二维卷积函数,参数x是输入,w是卷积的参数
# strides代表卷积模块移动的步长,都是1代表会不遗漏地划过图片的每一个点,padding代表边界的处理方式
# padding = 'SAME',表示padding后卷积的图与原图尺寸一致,激活函数relu()
# tf.nn.max_pool是Tensorflow中的最大池化函数,这里使用2 * 2 的最大池化,即将2 * 2 的像素降为1 * 1的像素
# 最大池化会保留原像素块中灰度值最高的那一个像素,即保留最显著的特征,因为希望整体缩小图片尺寸
# ksize:池化窗口的大小,取一个四维向量,一般是[1,height,width,1]
# 因为我们不想再batch和channel上做池化,一般也是[1,stride,stride,1]
def conv2d(x, w):
return tf.nn.conv2d(x, w, strides=[1,1,1,1],padding='SAME') # 保证输出和输入是同样大小
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1],padding='SAME')
# 3、参数
# 这里的x,y_并不是特定的值,它们只是一个占位符,可以在TensorFlow运行某一计算时根据该占位符输入具体的值
# 输入图片x是一个2维的浮点数张量,这里分配给它的shape为[None, 784],784是一张展平的MNIST图片的维度
# None 表示其值的大小不定,在这里作为第1个维度值,用以指代batch的大小,means x 的数量不定
# 输出类别y_也是一个2维张量,其中每一行为一个10维的one_hot向量,用于代表某一MNIST图片的类别
x = tf.placeholder(tf.float32, [None,784], name="x-input")
y_ = tf.placeholder(tf.float32,[None,10]) # 10列
# 4、第一层卷积,它由一个卷积接一个max pooling完成
# 张量形状[5,5,1,32]代表卷积核尺寸为5 * 5,1个颜色通道,32个通道数目
w_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32]) # 每个输出通道都有一个对应的偏置量
# 我们把x变成一个4d 向量其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(灰度图的通道数为1,如果是RGB彩色图,则为3)
x_image = tf.reshape(x,[-1,28,28,1])
# 因为只有一个颜色通道,故最终尺寸为[-1,28,28,1],前面的-1代表样本数量不固定,最后的1代表颜色通道数量
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1) # 使用conv2d函数进行卷积操作,非线性处理
h_pool1 = max_pool_2x2(h_conv1) # 对卷积的输出结果进行池化操作
# 5、第二个和第一个一样,是为了构建一个更深的网络,把几个类似的堆叠起来
# 第二层中,每个5 * 5 的卷积核会得到64个特征
w_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2)# 输入的是第一层池化的结果
h_pool2 = max_pool_2x2(h_conv2)
# 6、密集连接层
# 图片尺寸减小到7 * 7,加入一个有1024个神经元的全连接层,
# 把池化层输出的张量reshape(此函数可以重新调整矩阵的行、列、维数)成一些向量,加上偏置,然后对其使用Relu激活函数
w_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1,7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1)
# 7、使用dropout,防止过度拟合
# dropout是在神经网络里面使用的方法,以此来防止过拟合
# 用一个placeholder来代表一个神经元的输出
# tf.nn.dropout操作除了可以屏蔽神经元的输出外,
# 还会自动处理神经元输出值的scale,所以用dropout的时候可以不用考虑scale
keep_prob = tf.placeholder(tf.float32, name="keep_prob")# placeholder是占位符
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 8、输出层,最后添加一个softmax层
w_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2) + b_fc2, name="y-pred")
# 9、训练和评估模型
# 损失函数是目标类别和预测类别之间的交叉熵
# 参数keep_prob控制dropout比例,然后每100次迭代输出一次日志
cross_entropy = tf.reduce_sum(-tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 预测结果与真实值的一致性,这里产生的是一个bool型的向量
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
# 将bool型转换成float型,然后求平均值,即正确的比例
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 初始化所有变量,在2017年3月2号以后,用 tf.global_variables_initializer()替代tf.initialize_all_variables()
sess.run(tf.initialize_all_variables())
# 保存最后一个模型
saver = tf.train.Saver(max_to_keep=1)
for i in range(1000):
batch = mnist.train.next_batch(64)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1],keep_prob: 1.0})
print("Step %d ,training accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print("test accuracy %f " % accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
# 保存模型于文件夹
saver.save(sess,"save/model")
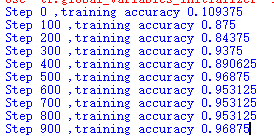
这里可以看到训练准确率达到96%。
- 数据集特点:为了测试识别的准确性,数据集中的手写数字中相同数字都会有不同的差别,有的会刻意差别较大,我从数据集中挑选了一些比较看起来容易识别错的数字,如下所示。


上面两个数字都是“0”,但是每一个写法都不是特别标准的,基本都是在0的形状基础上突出了一点或多了一笔,第一个在0的中间多了一条线,那么我猜测有可能会被识别成8,第二个突出了一部分,我猜测可能会被识别成6,但是将其进行识别发现两个结果都正确,识别效果好。


我又选取了几个比较容易识别错的手写体,发现以下几个字体因为笔画较多以及歪斜导致识别错误。
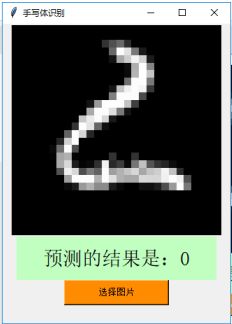

虽然训练出的准确度高,但是若是字体相对扭曲,特征不那么清晰难以识别,还是会出现识别错误的结果,我只测试了二十来个,二十个中错误率还是相对较高的,但是未必能代表整体。
(二)测试识别
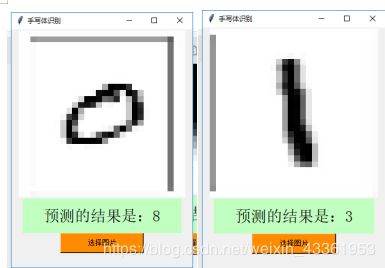
- 白底黑字:

上面四张都是我在白纸上手写的数字,特意写得比较端正希望比较好识别,可以很容易看出分别为数字2,0,7,1(这里注意要将图片转为灰度图,否则会报错),但是识别出来的结果都是错的,我一开始猜测可能是因为分辨率太小导致图片不清晰所以识别出错,就改了分辨率重新识别,但是结果还是如上,我就又尝试找了网图进行识别,结果如下,错的还是有点离谱,那么基本只剩一个可能,和背景字体颜色相关。
- 黑底白字:找一张黑色背景图用电脑手绘数字得到图片进行测试,结果如下。
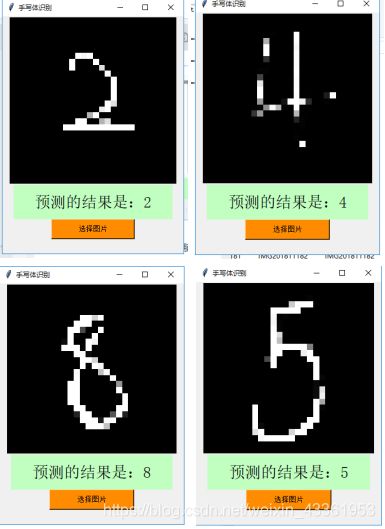
以上四个数字均识别正确,可以看到除了数字形状,识别还需要颜色对应才能达到正确的结果,并不是单靠字形就能识别。虽然识别正确,但是并不是每次识别都能成功,就比如以下图片: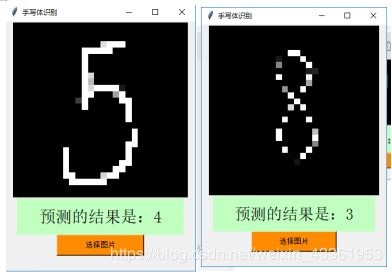
同一张图片,识别出来的结果是不同的,而且若是字体相对较细,也可能识别失败。虽然前面所训练得到的准确率有96%,但是实验整体识别出来的准确率并没有那么高,出错的机率还是比4%要大。
(三)识别脚本
import tensorflow as tf
import numpy as np
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageTk
from tkinter import filedialog
import time
def creat_windows():
win = tk.Tk() # 创建窗口
sw = win.winfo_screenwidth()
sh = win.winfo_screenheight()
ww, wh = 400, 450
x, y = (sw-ww)/2, (sh-wh)/2
win.geometry("%dx%d+%d+%d"%(ww, wh, x, y-40)) # 居中放置窗口
win.title('手写体识别') # 窗口命名
bg1_open = Image.open("timg.jpg").resize((300, 300))
bg1 = ImageTk.PhotoImage(bg1_open)
canvas = tk.Label(win, image=bg1)
canvas.pack()
var = tk.StringVar() # 创建变量文字
var.set('')
tk.Label(win, textvariable=var, bg='#C1FFC1', font=('宋体', 21), width=20, height=2).pack()
tk.Button(win, text='选择图片', width=20, height=2, bg='#FF8C00', command=lambda:main(var, canvas), font=('圆体', 10)).pack()
win.mainloop()
def main(var, canvas):
file_path = filedialog.askopenfilename()
bg1_open = Image.open(file_path).resize((28, 28))
pic = np.array(bg1_open).reshape(784,)
bg1_resize = bg1_open.resize((300, 300))
bg1 = ImageTk.PhotoImage(bg1_resize)
canvas.configure(image=bg1)
canvas.image = bg1
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
saver = tf.train.import_meta_graph('save/model.meta') # 载入模型结构
saver.restore(sess, 'save/model') # 载入模型参数
graph = tf.get_default_graph() # 加载计算图
x = graph.get_tensor_by_name("x-input:0") # 从模型中读取占位符变量
keep_prob = graph.get_tensor_by_name("keep_prob:0")
y_conv = graph.get_tensor_by_name("y-pred:0") # 关键的一句 从模型中读取占位符变量
prediction = tf.argmax(y_conv, 1)
predint = prediction.eval(feed_dict={x: [pic], keep_prob: 1.0}, session=sess) # feed_dict输入数据给placeholder占位符
answer = str(predint[0])
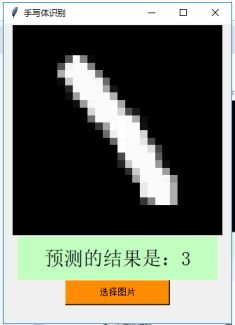
var.set("预测的结果是:" + answer)
if __name__ == "__main__":
creat_windows()