(二)Pytorch线性回归简单实例的实现
1.线性回归的作用
确定两种或两种以上变量的相互依赖的定量关系
2.线性回归的形式
f ( x ) = w T x + b f(x)=w^Tx+b f(x)=wTx+b
要找f(x)和x的关系,x常常是一组独立的变量 x = ( x 1 , x 2 , . . . , x k ) x=(x_1,x_2,...,x_k) x=(x1,x2,...,xk)w是模型从训练数据中学到的参数 w = ( w 1 , w 2 , . . . , w k ) w=(w_1,w_2,...,w_k) w=(w1,w2,...,wk)b也是学到的参数,叫做偏置
3.简单模型的实现
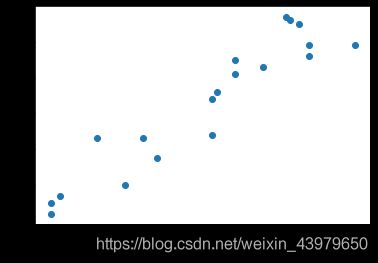
目标:给出一组点(x,y)通过线性回归预测后续走势
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from torch.autograd import Variable
# Hyper Parameters
input_size = 1
output_size = 1
num_epochs = 1000
learning_rate = 0.001
x_train = np.array([[2.3], [4.4], [3.7], [6.1], [7.3], [2.1],[5.6], [7.7], [8.7], [4.1],
[6.7], [6.1], [7.5], [2.1], [7.2],
[5.6], [5.7], [7.7], [3.1]], dtype=np.float32)
#xtrain生成矩阵数据
y_train = np.array([[3.7], [4.76], [4.], [7.1], [8.6], [3.5],[5.4], [7.6], [7.9], [5.3],
[7.3], [7.5], [8.5], [3.2], [8.7],
[6.4], [6.6], [7.9], [5.3]], dtype=np.float32)
plt.figure()
#画图散点图
plt.scatter(x_train,y_train)
plt.xlabel('x_train')
#x轴名称
plt.ylabel('y_train')
#y轴名称
#显示图片
plt.show()
首先根据给出的(x,y)的数据,画出散点图,画图通过matplotlib模块
# Linear Regression Model
class LinearRegression(nn.Module):
def __init__(self, input_size, output_size):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(input_size, output_size)
def forward(self, x):
out = self.linear(x)
return out
model = LinearRegression(input_size, output_size)
# Loss and Optimizer
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
(1)super函数
通过类class的方式定义模型结构,其中self指的是LinearRegression类实例化的本身,而不是LinearRegression类,比如
model = LinearRegression(input_size, output_size)后,self = model
具体super函数的用法,参考https://segmentfault.com/a/1190000007998627
其中MRO列表可以理解为“类和类之间的父子关系表,谁是谁的爹,爹的上面还有爹”,super函数可以理解为“找爹函数”,遇到super(A,B),找到A的爹来处理B,B是当前执行的类的实例,相当于B=A的爹,执行"B.abc",就等于执行"A的爹.abc"
比如上面这段代码里面就是model = LinearRegression(input_size, output_size)执行后的model,LinearRegression()只是类,model是它的实例
(2) init
super(LinearRegression, self).init()
这行代码的意思是通过super调用LinearRegression类的父类的构造函数(也就是nn.Module的构造函数)给当前实例self(也就是model),构造函数就是"init()"
(3)损失
Loss使用最小二乘Loss,分类问题最常用的是“交叉熵Loss”
(4)优化器
优化使用SGD优化,即随机梯度下降Stochastic Gradient Descent
具体优化器的种类和选择可以参考https://www.cnblogs.com/guoyaohua/p/8542554.html
# Train the Model
for epoch in range(num_epochs):
# Convert numpy array to torch Variable
inputs = Variable(torch.from_numpy(x_train))
targets = Variable(torch.from_numpy(y_train))
# Forward + Backward + Optimize
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if (epoch+1) % 5 == 0:#每5次epoch打印一次结果
print ('Epoch [%d/%d], Loss: %.4f'
%(epoch+1, num_epochs, loss.item()))
# Plot the graph
model.eval()
predicted = model(Variable(torch.from_numpy(x_train))).data.numpy()
plt.plot(x_train, y_train, 'ro')
plt.plot(x_train, predicted, label='predict')
plt.legend()
plt.show()
plt.savefig("/home/ubuntu/gzht/test.jpg")
(5)Numpy array类型和Torch tensor类型的转换
使用torch.from_numpy(x_train),将Numpy array类型的变量x_train转换Torch tensor类型
(6)optimizer.zero_grad()
optimizer.zero_grad() 表示把梯度置零,也就是将Loss关于weight的导数置为0,如果不进行这一步操作,那么每一次epoch都会使得梯度叠加,造成梯度爆炸。
(7)loss.backward()
backward()来源是torch.autograd.backward,使用backward()可以计算loss的梯度,代码loss.backward()执行后,loss中各个parameters的梯度得到更新,比如loss的parameter中有个变量是x,那么执行loss.backward之后,loss关于变量x的梯度就保存在x.grad中,可以通过x.grad来查看。
loss = criterion(outputs, targets)
targets = Variable(torch.from_numpy(y_train))
outputs = model(inputs)
inputs = Variable(torch.from_numpy(x_train))
所以loss的parameter归根到底应该是x_train和y_train
(7)optimizer.step()
本行代表只对loss的parameter做单步更新,所谓的更新,就是 新 p a r a m e t e r 值 = 原 p a r a m e t e r 值 − l e a r n i n g r a t e ∗ p a r a m e t e r . g r a d ( 导 数 值 ) 新parameter值=原parameter值-learning_rate*parameter.grad(导数值) 新parameter值=原parameter值−learningrate∗parameter.grad(导数值)