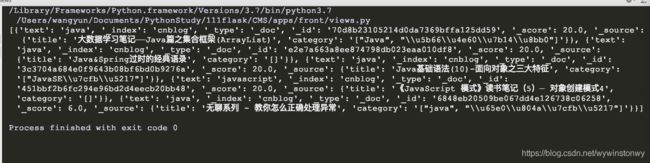
elasticsearch模糊搜索,搜索建议(suggest),自动补全
首先构建mapping,并制定字段解析器。解析器采用中文ik_max_word类型,es默认不支持,需要自己下载解析包扩展。中文解析包下载地址: https://github.com/medcl/elasticsearch-analysis-ik/releases
加载elasticsearch对应的解析包并配置到elaticsearch/plugins/ik,ik文件夹需要自己创建,创建完后将对应下载包copy到文件夹下即可,然后重启es才会生效,重启控制台会加载输出ik相关字眼的log。
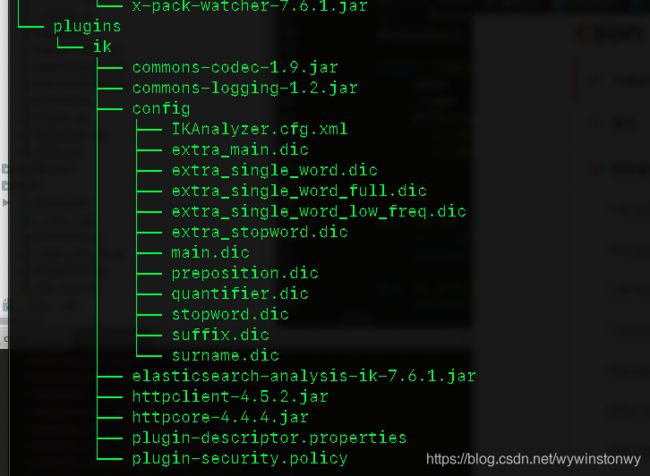
配置完es以后构建es mapping字段
首先导入相关组件并构建解析器
# -*- coding: utf-8 -*-
# @Time : 2020/4/1 8:59 AM
# @Author : wywinstonwy
# #@desc:
from datetime import datetime
from elasticsearch_dsl import Document, Date, Integer, Keyword, Text, connections,Search,Completion
from elasticsearch import Elasticsearch
from elasticsearch_dsl import analyzer, tokenizer
from elasticsearch_dsl.analysis import CustomAnalyzer as _CustomAnalyzer
# Define a default Elasticsearch client
connections.create_connection(hosts=['localhost'])
my_analyzer = analyzer('my_analyzer',
tokenizer=tokenizer('trigram', 'nGram', min_gram=2, max_gram=3),
filter=['lowercase']
)
# my_analyzer = analyzer('my_analyzer',
# tokenizer=tokenizer('ik_max_word', min_gram=2, max_gram=3),
# filter=['lowercase']
# )
class customAnalyzer(_CustomAnalyzer):
def get_analysis_definition(self):
return {}
ik_analyzer =customAnalyzer('ik_max_word',filter=['lowercase'])
其次是构建mapping字端,并指定对应解析器,suggest字端为搜索建议补全字段。
class Article(Document):
title = Text(analyzer='snowball', fields={'raw': Keyword()})
suggest =Completion(analyzer=ik_analyzer)
content = Text(analyzer='snowball')
category = Keyword()
publish_time =Date()
published_from = Date()
lines = Integer()
author_name = Keyword()
url = Keyword
objhashurl = Keyword
class Index:
name = 'cnblog'
_type ='article'
settings = {
"number_of_shards": 2,
"number_of_replicas": 1
}
def save(self, ** kwargs):
self.lines = len(self.content.split())
return super(Article, self).save(** kwargs)
def is_published(self):
return datetime.now() > self.publish_time
GET cnblog/_search
{
"query": {
"bool": {
"must": [
{
"match_all": { }
}
],
"must_not": [ ],
"should": [ ]
}
},
"from": 0,
"size": 10000,
"sort": [ ],
"aggs": { }
}
#搜索
GET cnblog/_search
{
"query": {
"fuzzy": {
"title": "java"
}
}
, "_source": ["title"]
}
#fuzzy模糊搜索
GET cnblog/_search
{
"query": {
"fuzzy": {
"title": {
"value": "jav",
"fuzziness": 2,
"prefix_length": 2
}
}
}
, "_source": "title"
}
#建议搜索补全
GET cnblog/_search
{
"suggest": {
"suggest": {
"prefix":"jaba",
"text": "jaba",
"completion": {
"field": "suggest",
"fuzzy":{
"fuzziness":1
}
}
}
}
, "_source": ["title","category"]
}
fuzziness 为编辑距离,可以设置适合的大小范围。

最后通过接口实现查询:
def suggest():
keyword ='jav'
response1 = client.search(
index='cnblog',
body={
"suggest": {
"suggest": {
"text": keyword,
"completion": {
"field": "suggest",
"fuzzy": {
"fuzziness": 1
}
}
}
}
, "_source": ["title", "category"]
}
)
return response1