测试开发 面试题准备
目录
- [0 牛客网测试开发面经](https://www.nowcoder.com/tutorial/97/e1cb34a000db4fc78554fc6f528687bc)
- 1(c/c++内存管理)堆和栈的区别
- 2 重载和多态的区别
- 3 引用和指针的区别
- 4 单例模式和工厂模式
- 单例模式
- 简单工厂
- 5 排序算法
- 冒泡排序
- 选择排序
- 插入排序
- 希尔排序
- 归并排序
- 快速排序
- 堆排序
- 6 static用法
- 静态全局变量
- 局部静态变量
- 静态函数
- 类的静态成员
- 类的静态函数
- 7 tcp和udp区别与应用场景
- 8 数据库
- 索引
- 9 自动化测试
- 自动化测试与人工测试区别
- 10 系统测试分类和常用的测试方法
0 牛客网测试开发面经
1(c/c++内存管理)堆和栈的区别
五大内存分区
在C++中,内存分成5个区,他们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区。
- 栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。
- 堆,就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
- 自由存储区,就是那些由malloc等分配的内存块,他和堆是十分相似的,不过它是用free来结束自己的生命的。
- 全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
- 常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改,而且方法很多
明确区分堆与栈
void f(){
int* p=new int[5];
}
这条短短的一句话就包含了堆与栈,看到new,我们首先就应该想到,我们分配了一块堆内存,那么指针p呢?他分配的是一块栈内存,所以这句话的意思就是:在栈内存中存放了一个指向一块堆内存的指针p。在程序会先确定在堆中分配内存的大小,然后调用operator new分配内存,然后返回这块内存的首地址,放入栈中。
为了简单并没有释放内存,那么该怎么去释放呢?是delete p么?澳,错了,应该是delete []p。
主要的区别
1、管理方式不同;
2、空间大小不同;
3、能否产生碎片不同;
4、生长方向不同;
5、分配方式不同;
6、分配效率不同;
- 管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。
- 空间大小:一般来讲在32位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在VC6下面,默认的栈空间大小是1M(好像是,记不清楚了)。当然,我们可以修改:
打开工程,依次操作菜单如下:Project->Setting->Link,在Category 中选中Output,然后在Reserve中设定堆栈的最大值和commit。
注意:reserve最小值为4Byte;commit是保留在虚拟内存的页文件里面,它设置的较大会使栈开辟较大的值,可能增加内存的开销和启动时间。 - 碎片问题:对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出,详细的可以参考数据结构,这里我们就不再一一讨论了。
- 生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
- 分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
- 分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
2 重载和多态的区别
- 多态是建立在重写的基础之上的,是类与类之间的关系,是发生在不同的类之间的,子类重写父类的方法。实现不同的子类,不同的实现形态。
多态有3个条件:
1:继承
2:重写(重写父类继承的方法)
3:父类引用指向子类对象 - 重载是类的内部的方法构型上的不同,是发生在同一个类里面的。同一个函数名称,参数不同的多个方法,实现同一类型的功能。
3 引用和指针的区别
- 引用:一个变量的别名。打个比方,有个kid非常可爱,大名叫静静,还有个小名叫小花。其实静静和小花都是指的同一个人。
- 指针:指针本身也是一个变量,这个变量的内容可以是空(NULL),当然更可以是另一个变量的内存地址。指针就好像一把钥匙,用来打开一个抽屉,这个抽屉就是内存空间,空间的内容就是存储的数据。
区别
1、引用在被定义时就必须要被初始化,而且不可以为NULL。
指针在定义时可以不被初始化,当然还是初始化比较好,而且可以被赋值为NULL。比如:
int a;
int& b = a; // b为a的引用,在定义时应当初始化。
int *c = NULL;
c = &a; // c可以被赋值为NULL,此时c指向了a的内存地址。
2、引用不可以用const 修饰,指针可以。 这个就不解释了,指针可以使用const 限制它不被更改,因为指针指针可以指向其他的内存单元,引用本身就是变量的别名,一经初始化,不可更改,当然不能再用const修饰了。
3、引用是直接访问内存单元,指针是间接访问。
4、自增运算(++)对于引用和指针来说,运算结果是不同的。
int a[2] = {0,0};
int b = &a[0];
int *c = a;
b++; //这是啥意思?b++等价于a[0]++
c++;//这又是啥意思?
首先,b是a[0]的引用,所以b就是a[0] b++等价于a[0]++;所以a[0]变成了 1。然后,c++;是干了点啥事儿呢?c是一个变量,内容是数组a的地址,
c++的意思是指向数组的下一个元素,所以c++的运算结果就是c现在指向了a[1]。(*c)++ 和b++的运算结果就是一样的了。
引用一般用于函数的参数传递和参数返回,指针呢?哪里用都可以,只是用起来要小心。
补充
1.指针有自己的一块空间,而引用只是一个别名;
2.使用sizeof看一个指针的大小是4,而引用则是被引用对象的大小;
3.指针可以被初始化为NULL,而引用必须被初始化且必须是一个已有对象 的引用;
4.作为参数传递时,指针需要被解引用才可以对对象进行操作,而直接对引 用的修改都会改变引用所指向的对象;
5.可以有const指针,但是没有const引用;
6.指针在使用中可以指向其它对象,但是引用只能是一个对象的引用,不能 被改变;
7.指针可以有多级指针(**p),而引用至于一级;
8.指针和引用使用++运算符的意义不一样;
9.如果返回动态内存分配的对象或者内存,必须使用指针,引用可能引起内存泄露。
4 单例模式和工厂模式
设计模式不是代码,而是解决问题的方案,学习现有的设计模式可以做到经验复用。
单例模式
确保一个类只有一个实例,并提供了一个全局访问点。
使用一个私有构造函数、一个私有静态变量以及一个公有静态函数来实现。
私有构造函数保证了不能通过构造函数来创建对象实例,只能通过公有静态函数返回唯一的私有静态变量。
实现:
懒汉式-线程不安全
以下实现中,私有静态变量 uniqueInstance 被延迟化实例化,这样做的好处是,如果没有用到该类,那么就不会实例化 uniqueInstance,从而节约资源。
这个实现在多线程环境下是不安全的,如果多个线程能够同时进入if(uniqueInstance == null) ,那么就会多次实例化 uniqueInstance。
publicclassSingleton {
private static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance ==null) {
uniqueInstance =new Singleton();
}
return uniqueInstance;
}
}
懒汉式-线程安全
只需要对 getUniqueInstance()方法加锁,那么在一个时间点只能有一个线程能够进入该方法,从而避免了对 uniqueInstance 进行多次实例化的问题。
但是这样有一个问题,就是当一个线程进入该方法之后,其它线程试图进入该方法都必须等待,因此性能上有一定的损耗。
publicstaticsynchronized Singleton getUniqueInstance() {
if (uniqueInstance ==null) {
uniqueInstance =new Singleton();
}
return uniqueInstance;// synchronized同步
}
饿汉式-线程安全
线程不安全问题主要是由于 uniqueInstance 被实例化了多次,如果 uniqueInstance 采用直接实例化的话,就不会被实例化多次,也就不会产生线程不安全问题。但是直接实例化的方式也丢失了延迟实例化带来的节约资源的优势。
private static Singleton uniqueInstance =new Singleton();
双重校验锁-线程安全
public class Singleton {
private volatile static Singleton uniqueInstance;//volatile不稳定的
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) {
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
简单工厂
意图:
在创建一个对象时不向客户暴露内部细节;
简单工厂不是设计模式,更像是一种编程习惯。它把实例化的操作单独放到一个类中,这个类就成为简单工厂类,让简单工厂类来决定应该用哪个子类来实例化。
这样做能把客户类和具体子类的实现解耦,客户类不再需要知道有哪些子类以及应当实例化哪个子类。因为客户类往往有多个,如果不使用简单工厂,所有的客户类都要知道所有子类的细节。而且一旦子类发生改变,例如增加子类,那么所有的客户类都要进行修改。
如果存在下面这种代码,就需要使用简单工厂将对象实例化的部分放到简单工厂中。
public class Client {
public static voidmain(String[] args) {
int type = 1;
Product product;
if (type == 1) {
product = new ConcreteProduct1();
} elseif (type == 2) {
product = new ConcreteProduct2();
} else {
product = new ConcreteProduct();
}
}
}
实现
public interface Product {
}
public class ConcreteProduct implements Product{
}
public class ConcreteProduct1 implements Product{
}
public class ConcreteProduct2 implements Product{
}
public class SimpleFactory {
public Product createProduct(int type) {
if (type ==1) {
return new ConcreteProduct1();
} elseif (type ==2) {
return new ConcreteProduct2();
}
return new ConcreteProduct();
}
}
public class Client {
public static voidmain(String[] args) {
SimpleFactory simpleFactory = newSimpleFactory();
Product product = simpleFactory.createProduct(1);
}
}
5 排序算法
详细链接–> 十大排序算法动图详解
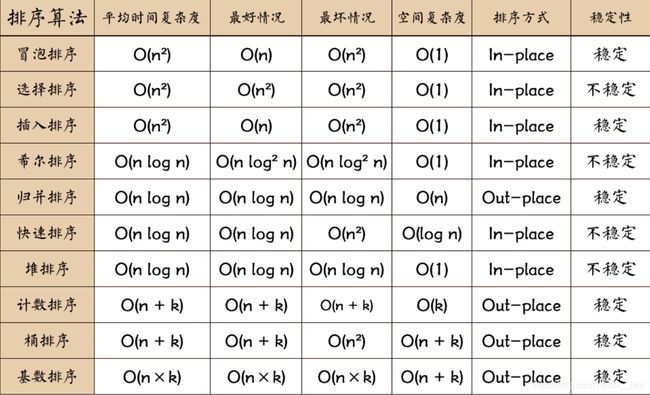
冒泡排序
/**
* 冒泡排序
*
* @param array
* @return
*/
public static int[] bubbleSort(int[] array) {
if (array.length == 0)
return array;
for (int i = 0; i < array.length; i++)
for (int j = 0; j < array.length - 1 - i; j++)
if (array[j + 1] < array[j]) {
int temp = array[j + 1];
array[j + 1] = array[j];
array[j] = temp;
}
return array;
}
选择排序
选择排序(Selection-sort) 是一种简单直观的排序算法。
它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
/**
* 选择排序
* @param array
* @return
*/
public static int[] selectionSort(int[] array) {
if (array.length == 0)
return array;
for (int i = 0; i < array.length; i++) {
int minIndex = i;
for (int j = i; j < array.length; j++) {
if (array[j] < array[minIndex]) //找到最小的数
minIndex = j; //将最小数的索引保存
}
int temp = array[minIndex];
array[minIndex] = array[i];
array[i] = temp;
}
return array;
}
插入排序
插入排序(Insertion-Sort) 的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
/**
* 插入排序
* @param array
* @return
*/
public static int[] insertionSort(int[] array) {
if (array.length == 0)
return array;
int current;
for (int i = 0; i < array.length - 1; i++) {
current = array[i + 1];
int preIndex = i;
while (preIndex >= 0 && current < array[preIndex]) {
array[preIndex + 1] = array[preIndex];
preIndex--;
}
array[preIndex + 1] = current;
}
return array;
}
希尔排序
希尔排序是希尔(Donald Shell) 于1959年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n2)的第一批算法之一。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。
希尔排序是把记录按下表的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
/**
* 希尔排序
*
* @param array
* @return
*/
public static int[] ShellSort(int[] array) {
int len = array.length;
int temp, gap = len / 2;
while (gap > 0) {
for (int i = gap; i < len; i++) {
temp = array[i];
int preIndex = i - gap;
while (preIndex >= 0 && array[preIndex] > temp) {
array[preIndex + gap] = array[preIndex];
preIndex -= gap;
}
array[preIndex + gap] = temp;
}
gap /= 2;
}
return array;
}
归并排序
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(n log n)的时间复杂度。代价是需要额外的内存空间。
归并排序 是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
/**
* 归并排序
*
* @param array
* @return
*/
public static int[] MergeSort(int[] array) {
if (array.length < 2) return array;
int mid = array.length / 2;
int[] left = Arrays.copyOfRange(array, 0, mid);
int[] right = Arrays.copyOfRange(array, mid, array.length);
return merge(MergeSort(left), MergeSort(right));
}
/**
* 归并排序——将两段排序好的数组结合成一个排序数组
*
* @param left
* @param right
* @return
*/
public static int[] merge(int[] left, int[] right) {
int[] result = new int[left.length + right.length];
for (int index = 0, i = 0, j = 0; index < result.length; index++) {
if (i >= left.length)
result[index] = right[j++];
else if (j >= right.length)
result[index] = left[i++];
else if (left[i] > right[j])
result[index] = right[j++];
else
result[index] = left[i++];
}
return result;
}
快速排序
快速排序 的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
算法描述
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
- 步骤1:从数列中挑出一个元素,称为 “基准”(pivot );
- 步骤2:重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 步骤3:递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
/**
* 快速排序方法
* @param array
* @param start
* @param end
* @return
*/
public static int[] QuickSort(int[] array, int start, int end) {
if (array.length < 1 || start < 0 || end >= array.length || start > end) return null;
int smallIndex = partition(array, start, end);
if (smallIndex > start)
QuickSort(array, start, smallIndex - 1);
if (smallIndex < end)
QuickSort(array, smallIndex + 1, end);
return array;
}
/**
* 快速排序算法——partition
* @param array
* @param start
* @param end
* @return
*/
public static int partition(int[] array, int start, int end) {
int pivot = (int) (start + Math.random() * (end - start + 1));
int smallIndex = start - 1;
swap(array, pivot, end);
for (int i = start; i <= end; i++)
if (array[i] <= array[end]) {
smallIndex++;
if (i > smallIndex)
swap(array, i, smallIndex);
}
return smallIndex;
}
/**
* 交换数组内两个元素
* @param array
* @param i
* @param j
*/
public static void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
堆排序
堆排序(Heapsort) 是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
//声明全局变量,用于记录数组array的长度;
static int len;
/**
* 堆排序算法
*
* @param array
* @return
*/
public static int[] HeapSort(int[] array) {
len = array.length;
if (len < 1) return array;
//1.构建一个最大堆
buildMaxHeap(array);
//2.循环将堆首位(最大值)与末位交换,然后在重新调整最大堆
while (len > 0) {
swap(array, 0, len - 1);
len--;
adjustHeap(array, 0);
}
return array;
}
/**
* 建立最大堆
*
* @param array
*/
public static void buildMaxHeap(int[] array) {
//从最后一个非叶子节点开始向上构造最大堆
//for循环这样写会更好一点:i的左子树和右子树分别2i+1和2(i+1)
for (int i = (len/2- 1); i >= 0; i--) {
adjustHeap(array, i);
}
}
/**
* 调整使之成为最大堆
*
* @param array
* @param i
*/
public static void adjustHeap(int[] array, int i) {
int maxIndex = i;
//如果有左子树,且左子树大于父节点,则将最大指针指向左子树
if (i * 2 < len && array[i * 2] > array[maxIndex])
maxIndex = i * 2; //感谢网友矫正,之前是i*2+1
//如果有右子树,且右子树大于父节点,则将最大指针指向右子树
if (i * 2 + 1 < len && array[i * 2 + 1] > array[maxIndex])
maxIndex = i * 2 + 1; //感谢网友矫正,之前是i*2+2
//如果父节点不是最大值,则将父节点与最大值交换,并且递归调整与父节点交换的位置。
if (maxIndex != i) {
swap(array, maxIndex, i);
adjustHeap(array, maxIndex);
}
}
6 static用法
静态全局变量
静态全局变量有以下特点:
该变量在全局数据区分配内存;
未经初始化的静态全局变量会被程序自动初始化为0( 在函数体内声明的自动变量的值是随机的,除非它被显式初始化,而在函数体外被声明的自动变量也会被初始化为0);
静态全局变量在声明它的整个文件都是可见的,而在文件之外是不可见的;
静态变量都在全局数据区分配内存,包括后面将要提到的静态局部变量。
定义静态全局变量还有以下好处:
- 静态全局变量不能被其它文件所用;
- 其它文件中可以定义相同名字的变量,不会发生冲突;
局部静态变量
在局部变量之前加上关键字static,局部变量就成为一个局部静态变量。
内存中的位置:静态存储区
初始化:未经初始化的全局静态变量会被自动初始化为0(自动对象的值是任意的,除非他被显式初始化);
作用域:作用域仍为局部作用域,当定义它的函数或者语句块结束的时候,作用域结束。但是当局部静态变量离开作用域后,并没有销毁,而是仍然驻留在内存当中,只不过我们不能再对它进行访问,直到该函数再次被调用,并且值不变;
静态函数
在函数返回类型前加static,函数就定义为静态函数。函数的定义和声明在默认情况下都是extern的,但静态函数只是在声明他的文件当中可见,不能被其他文件所用。
函数的实现使用static修饰,那么这个函数只可在本cpp内使用,不会同其他cpp中的同名函数引起冲突;
warning:不要再头文件中声明static的全局函数,不要在cpp内声明非static的全局函数,如果你要在多个cpp中复用该函数,就把它的声明提到头文件里去,否则cpp内部声明需加上static修饰;
类的静态成员
在类中,静态成员可以实现多个对象之间的数据共享,并且使用静态数据成员还不会破坏隐藏的原则,即保证了安全性。因此,静态成员是类的所有对象中共享的成员,而不是某个对象的成员。对多个对象来说,静态数据成员只存储一处,供所有对象共用
类的静态函数
静态成员函数和静态数据成员一样,它们都属于类的静态成员,它们都不是对象成员。因此,对静态成员的引用不需要用对象名。
在静态成员函数的实现中不能直接引用类中说明的非静态成员,可以引用类中说明的静态成员(这点非常重要)。如果静态成员函数中要引用非静态成员时,可通过对象来引用。从中可看出,调用静态成员函数使用如下格式:<类名>::<静态成员函数名>(<参数表>);
7 tcp和udp区别与应用场景

8 数据库
索引
索引的优缺点
索引的优点:
① 建立索引的列可以保证行的唯一性,生成唯一的rowId
② 建立索引可以有效缩短数据的检索时间
③ 建立索引可以加快表与表之间的连接
④ 为用来排序或者是分组的字段添加索引可以加快分组和排序顺序
索引的缺点:
① 创建索引和维护索引需要时间成本,这个成本随着数据量的增加而加大
② 创建索引和维护索引需要空间成本,每一条索引都要占据数据库的物理存储空间,数据量越大,占用空间也越大(数据表占据的是数据库的数据空间)
③ 会降低表的增删改的效率,因为每次增删改索引需要进行动态维护,导致时间变长
什么情况下需要建立索引
- 数据量大的,经常进行查询操作的表要建立索引。
- 用于排序的字段可以添加索引,用于分组的字段应当视情况看是否需要添加索引。
- 表与表连接用于多表联合查询的约束条件的字段应当建立索引。
9 自动化测试
自动化测试与人工测试区别
自动化测试其实就是通过自动化工具执行定制好的测试脚本,可以节省人力和时间成本,提高测试效率。但自动化测试不是并不能完全代替人工测试。自动化测试能解决很多问题,同时也带来很多问题。
自动化测试的优点:
1、减少人力成本,提高测试效率
2、完成大量重复性工作
3、完成手工不能完成的工作
4、有效利用资源
5、保证工作的一致性,增加信任度
自动化测试的缺点:
1、不能取代手工测试
2、手工测试比自动化测试发现缺陷更多
3、对测试质量的依赖性极大
4、测试自动化不能够提高有效性
5、测试自动化可能会制约软件开发。由于自动化测试比手工测试更脆弱,所以维护会受到限制,从而制约软件开发。
6、工具本身并无想象力
综上所述,可以归结为自动化完成不了的,手工测试都能弥补,两者有效的结合是测试质量保证的关键。
(1)覆盖率
- 优势:在同等时间内,启动自动化测试能够覆盖更多的功能。
- 劣势:只适合回归测试,开发中的功能不划算。对于开发中功能,需求或者实现的更改,都会导致自动化脚本的变更,维护脚本的工作量和开发这个功能不相上下,实在是不划算。
(2)测试效率
- 优势:完成同等数目的测试,启动自动化速度更快。
- 劣势:脚本开发比用例开发耗时长,包括编写脚本、调试脚本、维护脚本,而手工测试也要对测试哦用例进行撰写、评审、修订。由于用例编写更多为自然语言,时间上肯定会少。这里也引申一个另外的一种观点,直接用自动化脚本替代测试用例,也不乏是很好的做法。
(3)执行可靠性
- 优势:可靠的按脚本执行,后续定位、复现有明确的配置路径可循。
- 劣势:程序是死的,人是活的。目前而言,最智慧的还是人。可以说是成也萧何败也萧何,自动化的稳定来源于其死板,而人的智慧体现在思维的跳跃,跳跃的思维也会导致后期不易定位。
(4)资源利用率
- 优势:设备、仪表资源能够7*24小时利用。
- 劣势:无。这点上,自动化完胜。
(5)人力上限
- 优势:可进行压力、负载、并发、重复等人力不易完成的任务。
- 劣势:无。这点,自动化完胜。
(6)人员培养
- 优势:提升测试人员能力,提高与开发沟通的效率。
- 劣势:培养一名自动化测试人员耗费资源更多,不但是功利的说自动化工程师更贵,同时在团队中推广自动化配套的培训、测试管理、产品开发环节都要跟上。增加的环节从某种意义上讲,就是浪费,因为如果不弄自动化,都可以省了。
10 系统测试分类和常用的测试方法
一、系统测试分类
1、功能测试:验证当前软件主体功能是否实现
2、兼容性测试:验证当前软件在不同的环境下是否还可以使用。window,mac,浏览器,在电脑,ipad上能用吗
3、安全测试:验证软件是否只是对授权用户提供功能使用。银行卡自己使用是否安全。
4、性能测试:相对于当前于软件消耗的资源,产出能力;运行效率。
二、常用系统测试方法
1、按测试对象分类
白盒测试:软件底层代码功能实现,同时逻辑正确
黑盒测试:测试软件外在功能是否可用(点点点)。
灰盒测试:介于两者之间(接口测试)
2、按测试对象是否执行分类
静态测试:测试对象不执行,侧文档
动态测试:将软件运行在真实环境当中
3、按测试手段进行分类
手工测试:由测试人员手动的对被测对象进行验证,优点,就是可以灵活的改变测试操作和环境
自动化测试:两种形式:一种是自己写测试脚本,另外一种是通过第三方测试工具对被测对象进行测试。
优点:高效率完成人不能做的测试。
例如:同一时间,接口压力测试。