远程管理爬虫服务器——scrapyd 使用小记
最近在学习scrapy,发现scrapy简单易学而且稳定高效,想架设了爬虫服务器供其他同事使用,发现scrapyd提供了很好的web接口,稍加改动就可以远程管理爬虫,下达爬虫 任务,监测爬虫状态。很是方便,便拿来研究:
1.scrapyd安装:
使用pip安装
pip install scrapyd
2.启动scrapyd:
cd c:\Python27\Scripts
python scrapyd
如图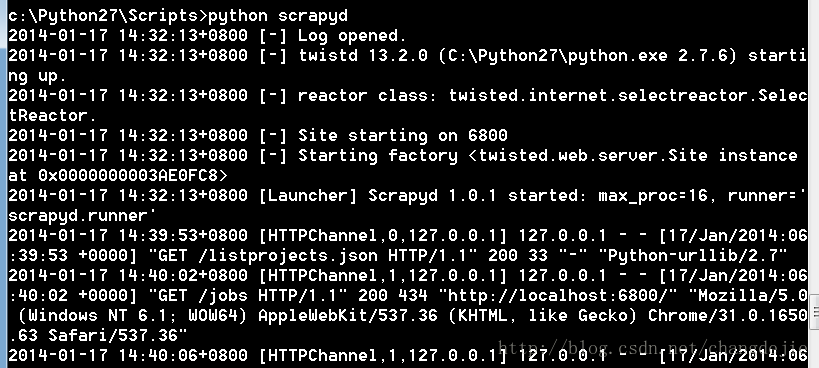
3.部署工程:
切换 到 工程目录,编辑 scrapy.cfg,把 #url = :6800/ 前面的 #号去掉。
编辑deploy相关信息,由于本人在服务端本地使用,所以目标地址为localhost,scrapy.cfg内容如下:

安装scrapyd-client :pip install scrapyd-client
将scrapyd-deploy文件放到工程目录下,并运行,如下图
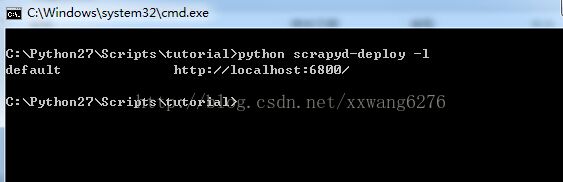
说明已scrapyd-deploy已发现工程
这时只要部署工程到scrapyd服务端就行,该目录下运行:python scrapyd-deploy
返回信息如下:

部署成功。
4.远程启动爬虫:
远程启动爬虫需要给http://localhost:6800/schedule.json地址POST工程名称和爬虫名称
新建scrapyd-test.py文件,内容如下:
执行该文件:
说明爬虫已启动。
去页面查看下爬虫状态:
已经结束了,log里有详细日志,items为爬到的内容。
也可以去items目录下查看历史信息
基本的功能都有了。
5.详细使用API(scrapyd官方文档):
http://scrapyd.readthedocs.org/en/latest/api.html