Image Super-Resolution Using Deep Convolutional Networks
Image Super-Resolution Using Deep Convolutional Networks
code: http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
本文使用一个三层的卷积网络来实现图像超分辨率,得到很好的效果。
1 I NTRODUCTION
单帧图像的超分辨率,即由一幅低分辨率图像重建出一幅高分辨率图像。在计算机视觉中这是一个比较经典的问题,比较有难度,因为已知变量多于未知变量,所以需要通过引入强先验知识来约束解的空间。对于先验知识的学习,当前比较流行的方法是基于 example 学习策略。学习可以是基于单幅图像样本的内部结构的学习,也可以是基于高低分辨率样本对的外部映射函数的学习。
sparse-coding-based method 是外部样本学习SR方法的一个代表。这个方法主要流程如下:从图像中裁出重叠的图像块,经过预处理(减去均值,归一化),然后用一个低分辨字典对这些图像块进行编码。得到稀疏系数,再利用高分辨率字典得到对应的高分辨率图像块,最后对这些重构的图像块进行组合(例如权值平均)得到最终的输出。基于这种传统方法我们需要通过学习得打字典。
我们这里提出的 Super-Resolution Convolutional Neural Network (SRCNN),具有以下优点:
1)它的结构很简单,但是效果很好。
2)计算效率高,速度快。
3)实验显示,网络对图像的restoration 重建能力有进一步提高的空间。(更多数据,更好的模型)
2.2 Convolutional Neural Networks
卷积网络在计算机视觉领域获得广泛应用,取得很大成功。这种进步来自以下几个因素:1)基于现代GPU高效训练的实现,2)ReLU的提出是的训练快速收敛,3)大数据的获取。
2.3 Deep Learning for Image Restoration
这里主要介绍了以前有哪些文献是用深度学习来进行图像恢复的。
3 Convolutional Neural Networks for Super-Resolution
3.1 Formulation
给定一幅低分辨率图像,我们首先使用 bicubic 插值将图像放大到想要的尺寸。得到的图像我们用 Y 表示,我们的目标是从Y重建一幅高分辨图像F(Y),使其尽可能于高分率真值图像X相似。我们通过以下三个步骤学习一个映射 F,实现上述目标。
1)图像块的提取和表示:从图像Y中提取重叠的图像块,然后将其用一个高纬向量表示,
这些向量就是表示图像块的特征。
2)非线性映射: 我们将上述高纬向量非线性映射为另一个高纬向量,对应高分辨率图像块的特征
3)对高分辨率特征进行组合,得到高分辨率图像。
我们可以发现上述三个步骤组成了一个卷积网络。如下图所示:
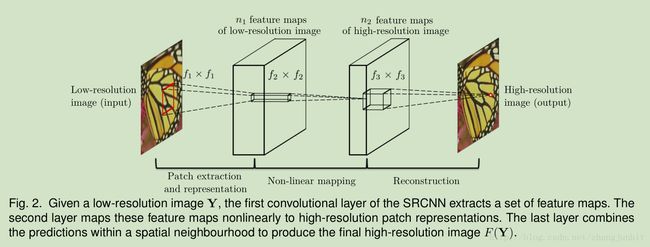
3.1.1 Patch extraction and representation
在图像恢复中有一个常用的策略就是从图像密集提取图像块,然后用一组预先训练好的基(PCA,DCT,Haar等)来表示。这等同于用一组滤波器对图像进行卷积,每个滤波器对应一个基。那么我们卷积网络的第一层可以如下表示:

其中,W1和B1分别表示滤波器和偏置,*表示卷积。这里 W1对应 n1个滤波器,每个滤波器是 c×f 1 ×f 1 ,c是图像通道数,RGB就是3通道,灰度图像是单通道。f1是滤波器尺寸。卷积之后我们就得到n1个特征图。接着我们对滤波器响应应用 ReLU,即 max(0,x)。
3.1.2 Non-linear mapping
经过上一步卷积,我们得到一个n1维特征向量,对应一个图像块,这一步,我们将一个n1维特征向量映射到一个n2维向量。这等价于使用n2个滤波器,其中每个滤波器只对应1*1的空间位置。当然这种解释只适用于1*1尺寸的滤波器。但是对于大的滤波器,3*3,5*5,非线性映射不是对应图像块,而是对应特征图中的 3*3,5*5 “块”。这一步可以看做下面的卷积

其中 W2包含 n2个滤波器,每个尺寸是 n1*f2*f2。这样就得到了一个 n2维向量,对应高分辨率图像块。
我们可以增加卷积层来增加模型的非线性,但是这会增加模型的复杂度。
3.1.3 Reconstruction
这一步就是对高分辨率图像块的权值平均,这个平均可以看做对一组特征图的一个预先定义的滤波器,使用下面的卷积表示

这里W3对应 c个 n 2 × f 3 × f 3 滤波器。
上述三个步骤本来是完全独立的,但是它们又可以用一个三层的卷积网络来统一训练。
3.2 Relationship to Sparse-Coding-Based Methods
我们可以发现,sparse-coding-based SR method 可以被看做一个卷积网络,如下图所示:
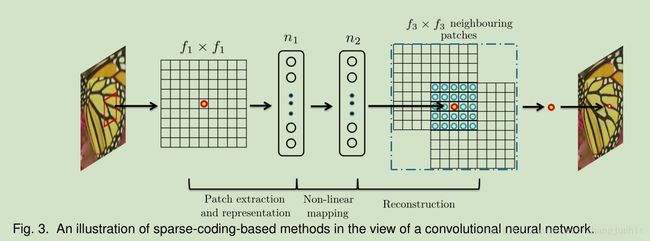
在 sparse-coding-based 方法中,我们首先从输入图像提取出一个 f 1 × f 1的图像块,然后将其投影到一个低纬字典中,如果这个字典的尺寸是n1,那么这个投影等同于使用n1个f 1 × f 1 滤波器对图像块进行卷积。
sparse coding solver 将会对上面的输出n1个系数进行迭代处理,输出n2个系数,通过对于 sparse coding 情况下 n1=n2。这n2个系数表示高分辨率图像块。从这个角度来说, sparse coding solver 可以看做是一个非线性映射算法,它空间尺寸是 1 × 1。但是 sparse coding solver 不是前馈的,它是一个迭代算法,相反我们的非线性算法是完全前馈的。可以被高效计算。如果我们使 f2=1,那么我们的非线性算子可以看做像素级全链接层。这里需要指出,在SRCNN中,the sparse coding solver 是对应前两场网络的,而不是第二层或激活函数(ReLU)。所以SRCNN中的非线性算子也可以在学习中被优化。
上面n2个稀疏将其投影到一个高纬字典中产生一个高纬块。这些重叠的高纬块再被平均。这如上面所说,这一步可以被看做一个卷积。
从上面的讨论我们可以看出 sparse-coding based SR method 可以被看做一个卷积网络,但是 sparse-coding based SR method 中的所有操作没有统一优化,三个步骤是独立的。与之相反,我们卷积网络是一个端对端统一训练得到所有的网络参数。
上面这种理解也帮助我们设计超参数。
3.3 Training
本文中的三层卷积网络的训练和普通的CNN网络训练是一样的。这里我们采用 Mean Squared Error (MSE) 作为损失函数。
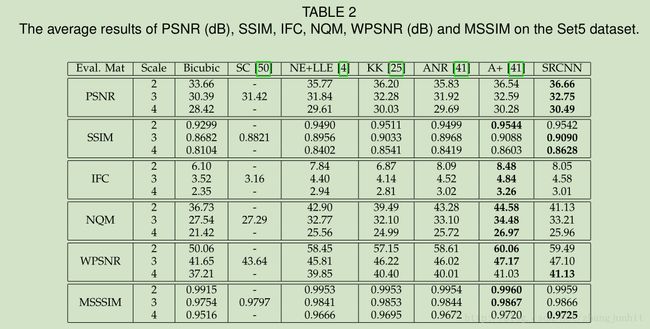
4 EXPERIMENTS
本文的理论比较简单,所以实验部分描述就比较多一些。
速度:

对于彩色图像的 处理:
