01 ARM体系结构与汇编指令
注:本文章是由笔者学习朱有鹏arm的学习笔记,特此感谢朱老师。
关于汇编:
1.汇编的实质是机器指令(机器码)的 助记符,是一款CPU的本质特征。2.不同CPU的机器指令集设计不同,因此 汇编程序不能在不同CPU间互相移植。
3.使用汇编编程可以充分发挥CPU的设计特点,所以汇编编程效率最高,因此在操作系统内核中效率极其重要处都需要用汇编处理。( 如中断处理等关键性能的地方)
语言发展:
纯机器码编程->汇编语言编程->C语言编程->C++编程->Java C#等语言编程->脚本语言编程编译器的作用:把C语言等高级语言翻译成汇编指令,再将汇编指令翻译成机器码
RISC和CISC的区别:
CISC:
complex instruction set computer- 复杂指令集CPU (平均设计指令(300条左右)) 例如:intel 奔腾
设计理念: 用最少的指令来完成任务
设计方式:CPU功能的扩展依赖于指令集的扩展,实质是CPU内部组合逻辑电路的扩展 (如 乘加指令=乘法+加法 类似 C语言 D = A*B +C)
RISC:
reduced instruction set computer- 精简指令集CPU (ARM-CPU常用指令30条左右)
设计理念: 让软件来完成具体的任务,CPU本身仅提供基本功能指令集
设计方式:CPU仅提供基础功能指令集(譬如内存与寄存器通信指令,基本运算指令与判断指令等),功能扩展由使用CPU的人利用基础架构来实现
IO与内存:
IO:input and output :一般就是指与CPU连接的各种内部或者外部设备
访问方式:
1. IO与内存统一编址方式:将IO口当作内存来访问 但是IO也要占用CPU的地址空间(占用CPU地址空间,CPU地址空间有限)2. IO与内存独立编址方式:使用专用的CPU指令集来访问某种特定的外设(不占用CPU地址空间)
内存:程序的运行场所(内部存储器)
访问方式:随机访问-通过CPU的 地址总线来寻址定位,然后通过CPU数据总线来读写 <每一个内存单元有一个固定的地址 (与CPU直接相连)>程序运行时两大核心元素:
程序(只可读) + 数据(可读写)
程序:是我们写好的源代码经过编译、汇编之后得到的机器码,这些机器码可以拿给CPU去解码执行,CPU不会也不应该去修改程序,所以程序是 只读的。数据:程序运行过程中定义和产生的变量的值,是可以读写的,程序运行实际就是为了改变数据的值。
冯诺依曼结构与哈佛结构:
冯诺依曼结构: 程序和数据都放在内存里面,且彼此不分离(Intel CPU、ARM7)哈佛结构: 程序和数据分别独立存放,且彼此完全分离(MCS51 ARM9等)
我的记忆方法:哈佛大学牛逼,保证稳定性和安全性-分开存放。
寄存器:
含义:
属于CPU外设的硬件组成部分,CPU可以像访问内存一样访问寄存器。软件编程控制某一硬件,其实就是编程读写该硬件的寄存器。
例如:汇编指令集是CPU的编程接口API 那么 寄存器就是外设硬件的软件编程接口APISoC中两类寄存器:
1.通用寄存器:(ARM中37个)CPU的组成部分功能没有确定,一般可读可写2.SFR:(special function register特殊功能寄存器)
不在CPU中而存在于CPU的外设中,我们通过访问外设的SFR来编程操控这个外设-硬件编程控制方法
功能是事先定好的,不能随意去改变的,也不是通用的,是定制化使用的
编程访问寄存器的方法:
(如何用C语言去访问一个特定的内存地址?)
int *p = (int *)0x30008000;*p = 16;
究竟软件是怎样控制硬件:
通过操控硬件所对应的SFR来访问(跟访问内存一样(访问内存通过总线的方式(通过地址来访问)))关于ARM体系结构的总结:
1.ARM是 RISC架构的常用ARM汇编指令只是二三十条
低功耗CPU
ARM的架构非常适合单片机,嵌入式(尤其是物联网区域)。 服务器等高性能领域目前主导还是intel
2.ARM是 统一编址的(IO与内存统一编址)
大部分的ARM(M3 M4 M7 M0 ARM9 ARM11 A8 A9)都是32位架构
32位ARM CPU支持的内存少于4G(例如 SFR会占用CPU地址),通过CPU地址总线访问
3.ARM是 哈佛结构的
常见的ARM( 除ARM7外-冯诺依曼结构)都是哈佛结构的,保证CPU的稳定性和安全性
注: 哈佛结构也决定了ARM裸机程序(使用实地址即物理地址(数据手册中给出的地址))的链接比较麻烦,必须使用复杂的链接脚本告知链接器如何组织程序;
但是对于OS之上的应用( 工作在虚拟地址之中)则不需考虑这么多。一些专用术语:
(详细阐述见另一博客文章)
ROM : read only memory只读存储器(硬盘 flash)- CPU不能通过地址总线和数据总线来写RAM : ramdom access memory 随机访问存储器 - 和顺序访问相对比(flash 0,1,2,3,4,。。。500)
IROM: internal rom(内部ROM) 集成到Soc内部的ROM
IRAM: internal ram(内部RAM) 集成到Soc内部的RAM
DRAM: dynamic ram(动态RAM)
SROM: static rom? sram and rom?
ONENAND/NAND:
ONENAND :集合NOR Flash 和 NAND Flash
NAND : NAND Flash~
SFR : special function register
关于内存和外存:
内存:
内部存储器(用来运行程序的)RAM
举例: DRAM SRAM DDR
SRAM static 静态内存 -- 容量小、价格高 但不需要软件初始化直接上电就能用
DRAM dynamic 动态内存 -- 容量大、价格低 上电后不能直接使用,需要软件初始化后才能使用
连接方式:地址访问,通过地址总线&数据总线的总线式访问方式连接(随机访问-直接访问但是占用CPU地址空间,大小受限)
外存:
内部存储器(用来存储东西的)ROM
举例: 硬盘 Flash(NAND INAND U盘 SSD) 光盘
连接方式:通过CPU的外存接口来连接(不占用CPU的地址空间,访问速度没有总线式快,访问时序较复杂)
SoC常用外存:
1.Flash
1.1 NORFlash : 总线式访问
(一般接到SROMC_Bank,容量小、价格高 可以和CPU直接总线式相连,CPU上电后可以直接读取,一般用作启动介质(只用来放启动代码))1.2 NANDFlash:时序式访问(通过命令接口) - (分为SLC和MLC)类似于硬盘
容量大、价格低 不能总线式访问,CPU上电后不能直接读取,需要CPU先运行一些初始化软件,然后通过时序接口读写eg:上电以后CPU必须先读取一段代码,让这段代码来初始化硬盘,硬盘才能工作,然后通过时序接口读写
1.2.1 SLC(容量不大 价格较高 但稳定性好 访问时序简单)
1.2.2 MLC(容量很大 价格很低 访问复杂 容易出现坏块 必须需要ECC(Error Correcting Code)校验)
注:我的记忆方法:S-slowly 缓慢-安全-价格高 容量小
1.2.3 举例:1.2.3.1: eMMc/iNand/moviNand
eMMC(embeded 嵌入式 MMC)-芯片类似与MMC卡(芯片嵌入主板相当于插了SD卡)
iNand是SanDisk公司出产的eMMC,moviNand是三星公司出产的eMMC
oneNAND是三星公司自己研发出的一种Nand(集合NOR Flash 和 NAND Flash)
1.2.3.2: SD卡/TF卡/MMC卡
1.2.3.3: eSSD (SSD硬盘)-MLC的
2.硬盘
SATA硬盘 (机械式访问,磁存储原理,SATA是接口)关于内存&外存的运用:
一般PC机都是: 很小容量的BIOS(相当于NorFlash)(存储启动代码会同时初始化硬盘和内存)+ 很大容量的硬盘(类似于 NandFlash)+ 大容量DRAM-- 四两拨千斤哈一般的单片机: 很小容量的NorFlash + 很小容量的SRAM
嵌入式系统: NorFlash很贵,嵌入式系统倾向于不用NorFlash。(启动里面有解释)
直接用:外接的大容量NandFlash + 外接大容量DRAM + Soc内置的SRAM
将Nand的启动代码读取到内置的SRAM里面,运行就可初始化NandFlash和DRAM
关于S5PV210使用的启动:
1.启动方式: 外接的大容量NandFlash + 外接大容量DRAM + Soc内置的SRAM
实际上210的启动还要更好玩一些:1.210内置了一块大小为96KB的SRAM(叫做IRAM)
2.同时还有一块内置的64KB大小的特性NorFlash(叫IROM)。-后面记得区别~
为什么要这样设计呢?
为了支持多种外部设备启动。
为什么用IROM启动而不用NORFLASH启动呢?
降低BOM成本。
因为iROM可以使SOC从各种外设启动,
可以省下一块boot rom(专门用来启动的rom,一般是 norflash)。
2.启动过程大致:
2.1:
1- CPU上电后先从内部IROM中读取预先设置的代码(BL0),执行。
这一段IROM代码首先做了一些基本的初始化(CPU时钟、关看门狗...)
(这一段IROM代码是三星出厂前设置的,三星也不知道我们板子上将来接的是什么样的DRAM, 所以这一段IROM是不能复杂初始化外界的DRAM的,因此这一段代码只能初始化Soc内部的东西);
2-然后这一段代码会判断我们选择的启动模式(我们通过硬件的跳线可以更改板子的启动模式),3-然后从相应的外部存储器去读取第一部分启动代码(BL1,大小为16K)到内部的IRAM。
2.2:从IRAM去运行刚上一步读取来的BL1(16KB),然后执行。BL1负责初始化NandFlash,然后将BL2读取到 IRAM(剩余的80KB)然后运行
2.3:从IRAM运行BL2,BL2初始化DRAM,然后将OS读取到DRAM中,然后启动OS,启动过程结束。
3.启动思路:因为启动代码的大小是不定的,有些公司可能96KB就够了,有些公司可能1MB都不够。所以刚才说的2步的启动方式 有问题。
三星的解决方案是:
把启动代码分为2半(BL1和BL2),这两部分协同工作来完成启动。
但是看了手册还是有个疑问,先读取BL1再读取剩余的BL2,总量也是96K呀。
其实uboot中不是这么做的,因为uboot远不止96k,一般是160k到200k左右。
SRAM放不下,所以uboot不是将BL2复制到SRAM,而是直接复制到DDR2,这样的话BL1就得要初始化DDR2了。 (详情见关于此的博客)
注:1.BL0做了什么呢?
关看门狗
初始化指令cache
初始化栈
初始化堆
初始化块设备复制函数device copy function
设置SoC时钟系统
复制BL1到内部IRAM(16KB) 检查BL1的校验和 跳转到BL1去执行2.启动模式:当第一启动模式失败时,SD/MMC卡启动模式下将会从SD/MMC2通道尝试再次启动。(二次启动是一种冗余设计。)
3.s5PV210所有启动:
先1st启动->通过OMpin选择启动介质
再2nd启动,从SD2(SD卡通道2)
再Uart启动
再USB启动
这个应该是默认启动,可以通过调节代码(OM[5]),从Uart和USB先启动喔。
学习S5PV210将会用到的启动方式:
1. 使用板载的emmc卡来启动(SD卡通道0)-(0M[0]->OM[5] 101100)开发板收到默认就是从emmc启动,内部预先烧录了android
2. SD卡通道2启动
OMpin设置和SD0启动一样
3. USB调试模式启动
(0M[0]->OM[5] 1XXXX1)
注:
SD: 101100
USB:101101
结:
1.拨码开关设置我们只需动OM5即可,其他几个根本不需要碰。需要SD启动时OM5打到GND,USB启动时OM5打到VCC
2.可以先不销毁emmc中的android,而是用USB启动来做裸机调试。后面课程会使用USB和SD卡两种启动方式。
ARM的编程模式和7种工作模式:
1.ARM的基本设定:
ARM采用的32位架构ARM约定 :
-byte : 8bits
-halfword: 16bits(2 byte)
-word : 32bits(4 byte)
一个字就是CPU的位宽,CPU一次所能处理的数据的长度
32位CPU = 数据总线32位 = CPU位宽32位 = 一个字也是32位
大部分ARM core(指令集) 提供:
-ARM指令集 (32-bit)
-Thumb指令集 (16-bit) 最先出来 异常处理不好完成
-Thumb2指令集 (16 & 32bit)
2.ARM处理器的7个工作模式:
(1个用户模式+6个特权模式(1个系统模式+5种异常模式))
用户模式-User :非特权模式,大部分任务执行在这种模式
异常模式
-FIQ(快速中断) :当一个高优先级(fast)中断产生时将会进入这种模式
-IRQ(普通中断): 当一个低优先级(normal)中断产生时将会进入这种模式
-Supervisor(管理模式):当复位或软中断指令执行时将会进入这种模式
-Abort(中止模式):当存取异常时将会进入这种模式
-Undef(未定义模式):当执行未定义指令时会进入这种模式
系统模式
-System:使用和user模式相同寄存器集的特权模式
注:
1.除User(用户模式)是Normal(普通模式)外,其他6种都是Privilege(特权模式)
2.Privilege中出Sys模式外,其余5种为异常模式
3.各种模式的切换:
3.1 程序员通过代码主动切换(通过写CPSR寄存器)
3.2 CPU在某些情况下自动切换(如中断来了,CPU自动切换到中断模式)
4.各种模式下权限和可以访问的寄存器不同
补充:CPU为什么要设计这些模式呢?
1. CPU是硬件,OS是软件,软件的设计要依赖硬件的特性,硬件的设计要考虑软件的需要,便于实现软件特性
2. OS有安全级别要求,因此CPU设计多种模式是为了方便OS的多种觉得安全等级需要
ARM的37个通用寄存器介绍:
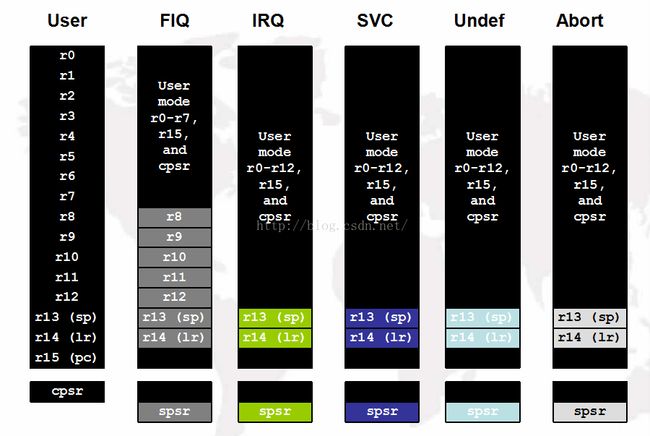
注:
1. System模式使用User模式寄存器集,sp-堆栈指针,lr-存返回地址,pc-程序计数器-程序控制寄存器,cpsr-程序状态寄存器,spsr-程序状态保存寄存器保存cpsr
2. 每种模式下最多只能看到18个寄存器,其他寄存器虽然名字相同,但是在当前模式不可见
3. 影子寄存器:对r14这个名字来说,在ARM中共有6个名叫r14(又叫lr)的寄存器,但是在每种特定处理器模式下,只有一个r14是当前可见的,其他的r14必须切换到他的对应模式下才能看到。这种设计叫影子寄存器(banked register)4.关于CPSR:

4.2 cpsr中的I、F位和开、关中断有关
4.3 cpsr中的mode位(bit4~bit0共5位)决定CPU的工作模式,在uboot代码中会使用汇编进行设置
5.关于PC:
5.1 pc为程序指针,pc指向哪里,cpu就会执行哪条指令(所以程序跳转时就是把目标地址代码放到pc中)
5.2 整个cpu中只有一个pc(cpsr也只有一个,但spsr有5个)
结:
1.ARM共有37个寄存器,都是32位长度
2.37个寄存器中30个为"通用"型,1个固定用作pc,1个固定用作cpsr,5个固定用作5种异常模式下的spsr
关于ARM的异常:
1.什么是异常:
正常工作之外的流程都叫异常(例如 中断)2.怎样处理:
通过异常向量表2.1 关于异常向量表:
2.1.1 所有的CPU都有异常向量表,这是CPU设计时就设定好的,是硬件决定的
2.1.2 当异常发生时,CPU会自动动作(PC跳转到异常向量处处理异常,有时伴有一些辅助动作)
2.1.3 异常向量表是硬件向软件提供的处理异常的支持
2.2 处理机制:
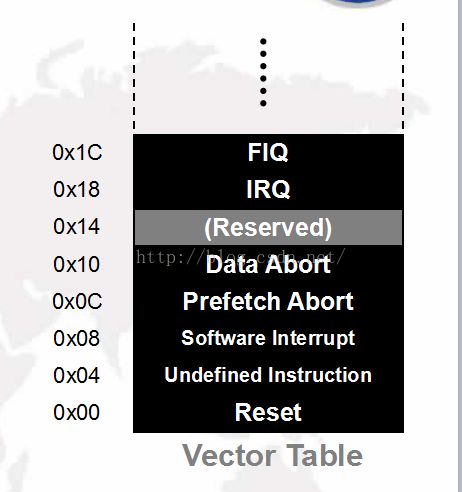
- 拷贝 CPSR到 SPSR_
- 设置适当的CPSR位:
、改变处理器状态进入ARM
、改变处理器模式进入相应异常模式
、设置中断禁止位禁止相应中断(如果需要)
- 保存返回地址到 LR_
- 设置PC为相应的异常变量
2.2.2 返回时,异常处理需要:
- 从SPSR_
- 从LR_
- Note:这些操作只能在ARM态执行
关于指令与伪指令:
1.(汇编)指令:
CPU机器指令的助记符,经过编译后会得到一串1、0组成的机器码,可以由CPU读取执行
1.1 两种不同风格的ARM指令:
1.1.1 ARM官方的ARM汇编风格:指令一般用大写、Windows中IDE开发环境(如ADS、MDK等)常用。如:LDR R0,[R1]
1.1.2 GNU(GNU/Linux)风格ARM汇编:
指令一般用小写、linux常用。如:ldr r0,[r1]
注释:GNU is GNU、Linux is Linux kernel、GNU/Linux is GNU/Linux。
第一个GNU是一个组织,一个自由软件组织
第二个Linux是一个内核,一个Linux kernel
第三个GNU/Linux是一个完整的操作系统,相对于Windows来说的一个完整的操作系统GNU/Linux。
1.2 ARM汇编特点:
1.2.1 LDR/STR架构
1.2.1.1 ARM采用RISC架构,CPU本身不能直接读取内存,而需要先将内存中内容加载入CPU中通用寄存器中才能 被CPU处理1.2.1.2 ldr (load register) 指令将内存内容加载入通用寄存器
1.2.1.3 str (store register) 指令将寄存器内容存入内存空间中
1.2.1.4 ldr/str 组合用来实现ARM CPU和内存数据交换
1.2.2 8种寻址方式
寄存器寻址 mov r1, r2
立即(数)寻址 mov r0, #0xFF00寄存器位移寻址 mov r0, r1, lsl #3(lsl 左移指令)
寄存器间接寻址 ldr r1, [r2]
基址变址寻址 ldr r1, [r2,#4]
多寄存器寻址 ldmia r1!, {r2-r7,r12}
堆栈寻址 stmfd sp!, {r2-r7,lr}
相对寻址 beq flag
fag:
1.2.3 指令后缀
同一指令经常附带不同后缀,变成不同的指令。经常使用的后缀有:B(byte)功能不变,操作长度变为8位
H(half word)功能不变,长度变为16位
S(signed)功能不变,操作数变为有符号 -如(ldr(加载4字节) ldrb(1) ldrh(2) ldrsb ldrsh)
S(S标志) 功能不变,影响CPSR标志位 -mov和movs
1.2.4 条件执行后缀
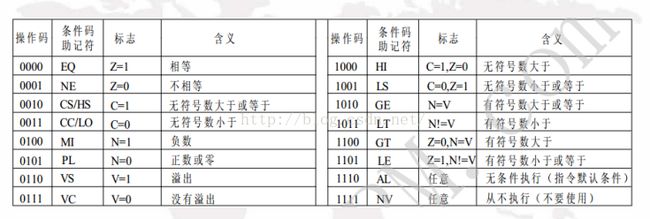
(有后缀) moveq r0,r1
@1.如果eq后缀成立,则直接执行mov r0,r1;如果eq不成立则本句代码直接作废,相当于没有
@2.类似于C语言中 if(eq) {r0 = r1;}条件后缀执行注意2点:
1.条件后缀是否成立,不是取决于本句代码,而是取决于这句代码 之前的代码运行后的结果
2.条件后缀决定了 本句代码是否被执行,而不会影响上一句和下一句代码是否被执行
1.2.5 多级指令流水线

-允许多个操作同时处理,而非顺序执行
ARM Thumb
PC PC 取指(从存储器中读取指令)
PC-4 PC-2 解码(解码指令中用到的寄存器)
PC-8 PC-4 执行(寄存器读(从寄存器Bank)->移位及ALU操作->寄存器写(到寄存器Bank))
2.PC指向正被取指的指令,而非正在执行的指令
1.3 常用ARM指令
1.3.1 数据处理指令:
数据传输指令
mov
mvn
mov r1, r0
@两个寄存器之间数据传递
mov r1, #0xff
@将立即数赋值给寄存器
注释:mov-原封不动的传递 mvn-按位取反后传递
算术指令 add sub rsb adc sbc rsc
逻辑指令 and(与) orr(或) eor(异或) bic(位清除指令)
bic r0, r1, #0x1f
@将r1中的数的bit0到bit4(0x1f-5位)清零后赋值给r0
比较指令 cmp cmn tst teq
注:
1.比较指令用来比较2个寄存器中的数
2. 比较指令不用后加s后缀就可以影响cpsr中的标志位。cmp: cmp r0,r1 等价于 sub r2,r0,r1 (r2 = r0 - r1)
cmn: cmn r0,r1 等价于 add r2,r0,r1 (r2 = r0 + r1)
tst: tst r0,#0xf
@测试r0的bit0~bit3是否全为0
乘法指令 mvl mla umull umlal smull smlal
前导零计数 clz
1.3.2 cpsr访问指令:
mrs & msrcpsr 和 spsr的区别和联系:
cpsr是程序状态寄存器,整个SoC中只有一个;
spsr是程序状态保存寄存器,有5个分别在5种异常模模式下,作用是当从普通模式进入异常模式时,用来保存之前普通模式下的spsr,以在返回普通模式时恢复原来的cpsr.
注:
1.mrs 用来读psr, msr用来写psr(cpsr、spsr)
2.cpsr寄存器比较特殊,需要专门的指令访问,这就是mrs和msr
1.3.3 跳转(分支)指令:
b & bl & bxb 直接跳转 (就没打算返回)
bl branch and link ,跳转前把返回地址放入lr中,以便返回,以便用于函数调用
bx 跳转同时切换到ARM模式,一般用于异常处理的跳转
1.3.4 访存指令:
ldr/str & ldm/stm & swp单个字/半字/字节访问 ldr/str
多字批量访问 ldm/stm
swp r1,r2,[r0](r1=r0,r0=r2)
swp r1,r1,[r0](r1=r0,r0=r1)r1和r0交换数据
1.4 ARM中的立即数:
合法立即数与非法立即数( 立即数以“#”为前缀)ARM指令都是32位的,除了指令标记和操作标记外,本身只能附带很少位数的立即数。因此立即数有合法和非法之分
合法立即数:经过任意位数的移位后非零部分可以用8位表示的即为合法立即数
1.5 软中断指令:
swi (software interrupt)软中断指令用来实现操作系统中系统调用
1.6 协处理器和协处理指令详解:
1.6.1 协处理器cp15操作指令:
mcr & mrcmrc用于读取cp15中的寄存器
mcr用于写入cp15中的寄存器
1.6.2 什么是协处理器:
1.SoC内部另一处理核心,协助主CPU实现某些功能,被主CPU调用执行一定任务2.ARM设计上支持多达16个协处理器,但是一般SoC只实现其中的CP15(CP:cooperation processor-coprocessor)
3.协处理器和MMU、cache、TLB等处理有关,功能上和操作系统的虚拟地址映射、cache管理等有关
1.6.3 mrc & mcr 使用方法:
mcr{注: 1.{cond}: 可选执行条件
2.opcode_1: 对于cp15永远为0
3.Rd: ARM的普通寄存器
4.Crn: cp15的寄存器,合法值是co-c15
5.Crm: cp15的寄存器,一般均设为c0
6.opcode_2: 一般省略或为0
学习要点:
1.不必深究,将uboot中和kernel中起始代码中的一般操作搞明白即可
2.只看一般用法,不详细区分参数细节,否则会陷入很多复杂未知中
3.关键在于理解,而不在于记住
1.7 ldm/stm 与 栈的处理:
1.7.1 为什么需要多寄存器访问指令:ldr/str每周期中能访问4字节内存,如果需要批量读取、写入内存时太慢,解决方案是ldm/stm
-ldm (load register mutiple) -stm (store register mutiple)
1.7.2 举例:
stmia sp,{r0-r12}
-将r0存入sp指向的内存处(假设为0x30001000);然后地址+4(即指向0x30001004),将r1存入该地址;
然后地址再+4(指向0x30001008),将r2存入该地址~直到r12的内容放入(0x30001030),指令完成。
-一个访存周期同时完成13个寄存器的读写
1.7.3 8种后缀:
ia(increase after) 先传输,再地址+4ib (increase before) 先地址+4,再传输
da(decrease after) 先传输,再地址-4
db (decrease before) 先地址-4,再传输
fd (full decrease) 满减栈
ed (empty decrease) 空减栈
fa(full add) 满增栈
ea (empty add) 空增栈
1.7.4 4种栈:
空栈:栈指针指向空位,每次存入可以直接存入然后栈指针移动一格;而取出时需要先移动一格才能取出满栈:栈指针指向栈中的最后一格,再次存入时需要先移动栈指针一格再存入;而取出时可以直接取出,然后再移动栈指针
增栈:栈指针移动时向地址增加的方向移动的栈
减栈:栈指针移动时向地址减小的方向移动的栈
1.7.5 补充:
!的作用:ldmia r0,{r2-r3}
ldmia r0!,{r2-r3} - !将r0在运算过程中产生的变化写回到r0里面去 类似static
结:感叹号的作用就是r0的值在ldm过程中发生的增加或者减少最后写回到r0去,
也就是说ldm时会改变r0的值
^的作用:
ldmfd sp!,{r0-r6,pc}
ldmfd sp!,{r0-r4,pc}^ - 在目标寄存器中有pc时,会同时将spsr写入到cpsr,一般用于从异常模式返回
总结:
1.批量读取或写入内存时要用ldm/stm指令
2.各种后缀以理解为主,不需记忆,最常见的是stmia和stmfd(ARM默认使用-满减栈)
3. 谨记:操作栈时使用相同的后缀就不会出错,不管是满栈还是空栈、增栈还是减栈-(进栈出栈都是用一样的)2.(汇编)伪指令:
伪指令本质是不是指令(只是和指令一起写在代码中),它是编译器环境提供的,
目的是用来指导编译过程,经过编译后伪指令最终不会生成机器码2.1 伪指令的意义:
1.伪指令不是指令(只是和指令一起写在代码中),伪指令和指令的根本区别是经过编译后会不会生成机器码2.伪指令的意义在于指导编译过程
3.伪指令是和具体的编译器相关的,我们使用gnu工具链,因此学习gnu环境下的汇编伪指令
2.2 gnu汇编中的一些符号:
1. @用来做注释。可以在行首也可以在代码后面同一行直接跟,和C语言中//类似2. #做注释,一般放在行首,表示这一行都是注释而不是代码
3. :以冒号结尾的是标号
4. .点号在gnu汇编中表示当前指令的地址
5. #立即数前面要加#或$,表示这是个立即数
2.3 常见的gnu伪指令:
.global_start @ 给_start外部链接属性.section .text @ 指定当前段为代码段
.ascii(定义字符) .byte(字节) .short(2个字节) .long(4个字节) .word(4个字节)
.quad(8个字节) .float .string @定义数据
.align 4 @ (2的4次方)以16字节对齐(内存地址对齐)
.balignl 16,0xabcdefgh @ 对齐+填充-16字节对齐填充
b表示位填充;
align表示要对齐;
l表示long,以4字节为单位填充;
16表示16字节对齐;
0xabcdefgh是用来填充的原料
.equ @类似于C中宏定义
2.4 偶尔会用到的gnu伪指令:
.end @标识文件结束.include @头文件包含
.arm/.code32 @声明以下为arm指令
.thumb/.code16 @声明以下为thumb指令
2.5 最重要的几个伪指令
.ldr 大范围的地址加载指令.adr 小范围的地址加载指令
.adrl 中等范围的地址加载指令
.nop 空操作
2.5.1 ARM中有一个ldr指令,还有一个ldr伪指令。且一般都用ldr伪指令而不用ldr指令
ldr指令: ldr r0,#0xff(必须是合法立即数)
伪指令: ldr r0,=0xff(不用考虑是合法还是非法) @涉及到合法/非法立即数,涉及到ARM文字池
2.5.2 adr与ldr:
1. adr编译时会被1条sub或add指令替代,而ldr编译时会被1条mov指令替代或者文字池方式处理;
2. adr总是以PC为基准来表示地址,因此指令本身和运行地址有关,可以用来检测程序当前的运行地址在哪里
3. ldr加载的地址和链接时给定的地址有关,由链接脚本决定
4.差别:
ldr加载的地址在 链接时确定
adr加载的地址在 运行时确定