排序方法
冒泡排序
In [1]:
def insert_sort(array):
# 这个i表示该找第i+1大的数
for i in xrange(len(array)-1):
for j in xrange(0,len(array)-i-1):
if array[j]>array[j+1]:
array[j+1],array[j] = array[j],array[j+1]
return array
array = [12,18,29,9,4,1,6]
bubleSort(array)
Out[1]:
[1, 4, 6, 9, 12, 18, 29]
In [21]:
def bubleSort2(array):
# 这个i该找存在这个下标上的数了
for i in xrange(len(array)-1,0,-1):
for j in xrange(0,i):
if array[j]>array[j+1]:
array[j+1],array[j] = array[j],array[j+1]
return array
array = [12,18,29,9,4,1,6]
bubleSort(array)Out[21]:
[1, 4, 6, 9, 12, 18, 29]
复杂度分析
平均情况与最坏情况均为 $O(n^2)$, 使用了 temp 作为临时交换变量,空间复杂度为 $O(1)$.
选择排序
核心:不断地选择剩余元素中的最小者。
找到数组中最小元素并将其和数组第一个元素交换位置。
在剩下的元素中找到最小元素并将其与数组第二个元素交换,直至整个数组排序。
性质:
比较次数=(N-1)+(N-2)+(N-3)+...+2+1~N^2/2
交换次数=N
运行时间与输入无关
数据移动最少
In [9]:
def selectSort(array):
# 这里i记得是这次该决定谁存到这个下标上了
for i in xrange(len(array)-1):
min_ind = i
for j in xrange(i+1,len(array)):
if array[min_ind]>array[j]:
min_ind = j
if min_ind != i:
array[min_ind],array[i] = array[i],array[min_ind]
return array
array = [12,18,29,9,4,1,6]
selectSort(array)Out[9]:
[1, 4, 6, 9, 12, 18, 29]
In [1]:
def selectSort2(array):
# 这里i记得是这次该决定谁存到这个下标上了
for i in xrange(len(array)-1,0,-1):
max_ind = i
#print i
for j in xrange(0,i):
#print j,array[max_ind],array[j]
if array[max_ind]Out[1]:
[1, 4, 6, 9, 12, 18, 29]
插入排序
In [1]:
def insertSort(alist):
for i,item_i in enumerate(alist):
# 开始确定第i个元素应该在的位子;
index = i-1
# 从前一个元素开始,遍历到0,
while index>=0 and alist[index]>item_i:
alist[index+1]=alist[index]
index-=1
alist[index+1] = item_i
return alist
alist = [12,18,29,9,4,1,6]
insertSort(alist)Out[1]:
[1, 4, 6, 9, 12, 18, 29]
希尔排序
其实就是分组插入排序
In [7]:
def shellSort(alist):
n = len(alist)
gap = int(round(n/2)) # 去长度的一般作为gap
while gap>0:
# print gap
for i in xrange(gap,n):
# 把i插入该列前面已经排好的地方
temp = alist[i]
while i-gap >=0 and alist[i-gap]>temp:
alist[i]=alist[i-gap]
i-=gap
alist[i] = temp
gap = int(round(gap/2)) # 得到新的步长
return alist
array = [12,18,29,9,4,1,6]
shellSort(array)Out[7]:
[1, 4, 6, 9, 12, 18, 29]
归并排序
核心:将两个有序对数组归并成一个更大的有序数组。通常做法为递归排序,并将两个不同的有序数组归并到第三个数组中。归并排序是一种典型的分治应用。
分两步:分段 / 合并
时间复杂度为$ O(NlogN)$, 使用了等长的辅助数组,空间复杂度为 $O(N)$。
In [5]:
def mergeSort(alist):
if(len(alist) <=1 ):
return alist
mid = len(alist)/2
left = mergeSort(alist[:mid])
right = mergeSort(alist[mid:])
return combine(left,right)
def combine(left,right):
alist = []
l = 0
r = 0
while lOut[5]:
[1, 2, 3, 4, 5, 6, 7, 8, 12, 18, 27, 41]
quick-sort 快速排序
核心:快排是一种采用分治思想的排序算法,大致分为三个步骤。
定基准——首先随机选择一个元素最为基准
划分区——所有比基准小的元素置于基准左侧,比基准大的元素置于右侧
递归调用——递归地调用此切分过程
out-in-place 非原地排序
『递归 + 非原地排序』的实现虽然简单易懂,但是如此一来『快速排序』便不再是最快的通用排序算法了,因为递归调用过程中非原地排序需要生成新数组,空间复杂度颇高。list comprehension 大法虽然好写,但是用在『快速排序』算法上就不是那么可取了。
In [1]:
def qsort1(alist):
if len(alist)<=1:
return alist
privot = alist[0]
# 下面的做法用到了list的合并,这些语言底层其实没什么计数含量
# 完全可以用高级语言的库取代,我没有必要去实现这些底层
return qsort1([item for item in alist[1:] if itemprivot])
unsortedArray = [6, 5, 3, 1, 8, 7, 2, 4]
print(qsort1(unsortedArray)) [1, 2, 3, 4, 5, 6, 7, 8]
非原地排序复杂度分析
在最好的情况下,快速排序的基准元素正好是正好是整个数组的中位数,可以近似为二分,最好情况下递归的层数为$logn$.
那么对于递归非原地快排来说,最好的情况下,每往下递归一层,所需要的存储空间是上一层的一半,完成最底层调用后就向上返回执行出栈操作,故并不需要保存本层所有元素的值(空间重用),所以需要的存储空间就是 $ sum^{log_2n}_{i=0} frac{n}{2^i} = n2(1-frac{1}{n}) = 2n$

那么最坏的情况就是,每次选的基准元素就是整个数组的最值,这样递归的层数就是n-1次
那么对于递归非原地快排来说,最坏的情况是第i层的空间位n-i+1,总的空间位$ sum^{n-1}_{i=0} n-i+1= frac{n(n+1)}{2}=O(n^2) $
-
*
in-palce 原地排序
过程中控制4个下标:
l 待排序部分的下界
u 待排序部分的上界
m 不大于基准元素的最后一个位置,在遍历结束后与基准元素位置交换
i 遍历的元素下标,从l到u
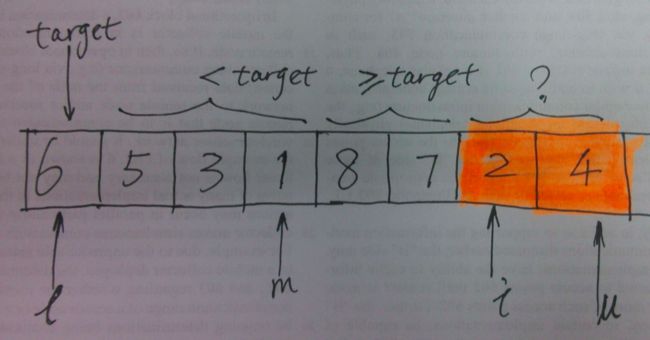
In [2]:
def qsort2(alist,l,u):
# 递归结束条件
if l>=u:
return
# 初始化几个下标
m=l
privot = alist[l]
for i in xrange(l+1,u+1):
if alist[i]Out[2]:
[1, 2, 3, 4, 5, 6, 6, 6, 8]
Two-way partitioning 两路分块
选择一个基准元素放在开头,在两端开始遍历,当l端找到大于基于元素的位置停下来,当r端找到不小于基准元素的位置停下来,两者进行交换,直到两者交叉或者相等,那么这个它r的位置就是基准元素的位置
In [31]:
import random
def qsort3(alist,lower,upper):
if(lower >= upper):
return
idx = random.randint(lower,upper)
alist[lower],alist[idx]=alist[idx],alist[lower]
privot = alist[lower]
left,right = lower+1,upper
while left<=right: # 等于的时候依然要继续因为还没划定边界,最后退出循环的时候一定是交叉的,r的右边都是不小于基准的,l的左边都是小于基准的
while left <= right and alist[left]=left and alist[right]>=privot:
right-=1
# 循环到这里要么是交叉了,要么是找到合适的位置了
if left Out[31]:
[1, 2, 3, 3, 4, 4, 5, 6, 7, 7, 8]
随机分区
如果待排序列正好是顺序的时候,整个的递归将会达到最大递归深度(序列的长度)。而实际上在操作的时候,当列表长度大于1000(理论值)的时候,程序会中断,报超出最大递归深度的错误(maximum recursion depth exceeded)。在查过资料后我们知道,Python在默认情况下,最大递归深度为1000(理论值,其实真实情况下,只有995左右,各个系统这个值的大小也不同)。 这个问题有两种解决方案, 1)重新设置最大递归深度,采用以下方法设置:
import sys
sys.setrecursionlimit(99999)
2)第二种方法就是采用另外一个版本的分区函数,称为随机化分区函数。由于之前我们的选择都是子序列的第一个数,因此对于特殊情况的健壮性就差了许多。现在我们随机从子序列选择基准元素,这样可以减少对特殊情况的差错率。
i = random.randint(p, r)
Heap Sort - 堆排序
堆排序的实现过程分为两个子过程。第一步为取出大根堆的根节点(当前堆的最大值), 由于取走了一个节点,故第二步需要对余下的元素重新建堆。重新建堆后继续取根节点,循环直至取完所有节点,此时数组已经有序。
堆的实现通过构造二叉堆(binary heap),实为二叉树的一种;由于其应用的普遍性,当不加限定时,均指该数据结构的这种实现。这种数据结构具有以下性质。
任意节点小于(或大于)它的所有后裔,最小元(或最大元)在堆的根上(堆序性)。
堆总是一棵完全树。即除了最底层,其他层的节点都被元素填满,且最底层尽可能地从左到右填入。
需要注意的是,堆是用数组保存的,所以根结点在下标为0的位子,又因为二叉堆是完全二叉树,所以下标位n/2的地方是二叉树里面最后一个非叶子结点的地方(有子结点),所以在建立大顶堆的时候,自底向上用下滤的方法建立各个小树,建每个小树用时$log(i)$,共建了$frac{n}{2} $个小树
建立大顶堆有两种方法 :
自底向上,先随便把这些数据放在一个数组里面,然后从最深一层的父节点开始自底向上下滤操作
自顶向下,先建一个空的堆,然后慢慢在最后位置插入新元素,并让它向上滤
步骤:
构造最大堆(Build_Max_Heap):若数组下标范围为0~n,考虑到单独一个元素是大根堆,则从下标n/2开始的元素均为大根堆。于是只要从n/2-1开始,向前依次构造大根堆,这样就能保证,构造到某个节点时,它的左右子树都已经是大根堆。
堆排序(HeapSort):由于堆是用数组模拟的。得到一个大根堆后,数组内部并不是有序的。因此需要将堆化数组有序化。思想是移除根节点,并做最大堆调整的递归运算。第一次将heap[0]与heap[n-1]交换,再对heap[0...n-2]做最大堆调整。第二次将heap[0]与heap[n-2]交换,再对heap[0...n-3]做最大堆调整。重复该操作直至heap[0]和heap[1]交换。由于每次都是将最大的数并入到后面的有序区间,故操作完后整个数组就是有序的了。
最大堆调整(Max_Heapify):该方法是提供给上述两个过程调用的。目的是将堆的末端子节点作调整,使得子节点永远小于父节点 。
最差时间复杂度 $O ( n log n )¥ 最优时间复杂度$O ( n log n ) 平均时间复杂[$Θ ( n log n ) $
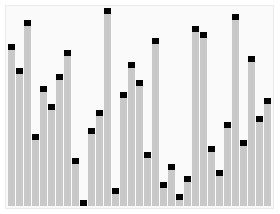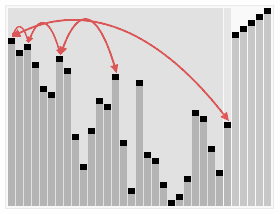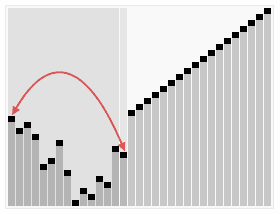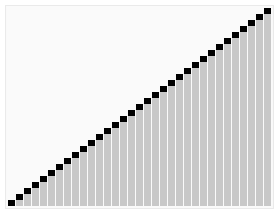
堆排在空间比较小(嵌入式设备和手机)时特别有用,但是因为现代系统往往有较多的缓存,堆排序无法有效利用缓存,数组元素很少和相邻的其他元素比较,故缓存未命中的概率远大于其他在相邻元素间比较的算法。但是在海量数据的排序下又重新发挥了重要作用,因为它在插入操作和删除最大元素的混合动态场景中能保证对数级别的运行时间
In [17]:
def heap_sort(alist):
# 下面是下滤的操作,下滤的前提是保证下面的子树是已经建好的子树
def sink(alist,i,length):
largest = i
if (2*i+1)alist[largest]:
largest = 2*i+1
if (2*i+2)alist[largest]:
largest = 2*i+2
if largest != i:
alist[largest],alist[i] = alist[i],alist[largest]
sink(alist,largest,length)
# 下面开始堆排序的操作,从最深一层的父节点开始循环,这样可以保证下滤的时候,下面都是排好序的字节点
# 先建立大顶堆
# n/2表示最后一个非叶结点
for i in xrange(len(alist)/2,-1,-1): #倒序到0,所以第二位设置为-1
sink(alist,i,len(alist))
# 然后不断底摘掉顶
length = len(alist)
for i in xrange(0,len(alist)):
alist[0],alist[length-1] = alist[length-1],alist[0]
length-=1
sink(alist,0,length)
return alist
unsortedArray = [6, 5, 3,13, 1, 8,28, 7, 2, 4]
sortedArray = heap_sort(unsortedArray)
sortedArray Out[17]:
[1, 2, 3, 4, 5, 6, 7, 8, 13, 28]
堆排序在 top K 问题中使用比较频繁。堆排序是采用二叉堆的数据结构来实现的,虽然实质上还是一维数组。二叉堆是一个近似完全二叉树 。
In [38]:
import heapq
heapq.nlargest(2,[9,5,12,38,32,21,1,-23])
heapq.nsmallest(2,[9,5,12,38,32,21,1,-23])Out[38]:
[-23, 1]
[经典排序算法](http://www.cnblogs.com/kkun/a...

对于比较排序算法,我们知道,可以把所有可能出现的情况画成二叉树(决策树模型),对于n个长度的列表,其决策树的高度为h,叶子节点就是这个列表乱序的全部可能性为n!,而我们知道,这个二叉树的叶子节点不会超过2^h,所以有2^h>=n!,取对数,可以知道,h>=logn!,这个是近似于O(nlogn)。也就是说比较排序算法的最好性能就是O(nlgn)。
那有没有线性时间,也就是时间复杂度为O(n)的算法呢?答案是肯定的。不过由于排序在实际应用中算法其实是非常复杂的。这里只是讨论在一些特殊情形下的线性排序算法。特殊情形下的线性排序算法主要有计数排序,桶排序和基数排序。这里只简单说一下计数排序。
-
*
桶排序Bucket sort
补充说明三点
桶排序是稳定的
桶排序是常见排序里最快的一种,比快排还要快…大多数情况下
桶排序非常快,但是同时也非常耗空间,基本上是最耗空间的一种排序算法
但桶排序是有要求的,就是数组元素隶属于固定(有限的)的区间,如范围为[0-9] (考试分数为1-100等),有时候想着感觉桶排序的第一步入桶操作和哈希表的构造有点像呢
假设数据分布在[0,100)之间,每个桶内部用链表表示,在数据入桶的同时插入排序。然后把各个桶中的数据合并。

In [20]:
import numpy as np
def bucket_sort(alist):
# 下面是入桶的过程
dic = dict()
for item in alist:
if item in dic:
dic[item].append(item)
else:
dic[item]=[]
dic[item].append(item)
# 下面是归并的过程
result = []
for key,items in dic.items():
for i in items:
result.append(i)
return result
unsortedArray = [6, 5, 3,5, 6, 5,3, 7, 3, 6]
sortedArray = bucket_sort(unsortedArray)
print sortedArray[3, 3, 3, 5, 5, 5, 6, 6, 6, 7]
In [59]:
import heapq
def bucket_sort2(alist):
# 下面是入桶的过程
k = heapq.nlargest(1,alist)[0]+1
dic = [None for i in range(k)]
for item in alist:
if dic[item]!=None:
dic[item].append(item)
else:
dic[item]=[]
dic[item].append(item)
# 下面是归并的过程
result = []
for i in xrange(0,k):
while dic[i]:
result.append(dic[i].pop())
return result
unsortedArray = [6, 5, 3,5, 6, 5,3, 7, 3, 6]
sortedArray = bucket_sort2(unsortedArray)
print sortedArray[3, 3, 3, 5, 5, 5, 6, 6, 6, 7]
计数排序
计数排序是建立在对待排序列这样的假设下:假设待排序列都是正整数(做下标来用)。首先,声明一个新序列list2,序列的长度为待排序列中的最大数(可以通过建立大顶堆获得)。遍历待排序列,对每个数,设其大小为i,list2[i]++,这相当于计数大小为i的数出现的次数。然后在依次加上前面的数,就知道最终这个数应该排在哪里了,然后,申请一个list,长度等于待排序列的长度(这个是输出序列,由此可以看出计数排序不是就地排序算法),倒序遍历待排序列(倒排的原因是为了保持排序的稳定性,即大小相同的两个数在排完序后位置不会调换),假设当前数大小为i,list[list2[i]-1] = i,同时list2[i]自减1(这是因为这个大小的数已经输出一个,所以大小要自减)。于是,计数排序的源代码如下。
In [48]:
import heapq
def count_sort(alist):
k = heapq.nlargest(1,alist)[0]+1 ;# 算出alist中的最大数,解决Top k 问题
alist2 = [0 for i in range(k)] # 建立长度为k初始化位0的数组
alist3 = [0 for i in range(len(alist))] # 排序后的结果存在这里
# 下面开始计数
for item in alist:
alist2[item]+=1
# 下面开始统计前面的,有点像积分操作 哈哈哈 算出来的就是最终的位置
for i in range(1,k):
alist2[i] += alist2[i-1]
# 下面开始倒序把数填在它该在的地方去
for item in alist[::-1]: #倒序遍历
#print item
alist3[alist2[item]-1] = item
alist2[item]-=1
return alist3
unsortedArray = [6, 5, 3,5, 6, 5,3, 7, 3, 6]
sortedArray = count_sort(unsortedArray)
print sortedArray [3, 3, 3, 5, 5, 5, 6, 6, 6, 7]
基数排序
流程
是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
它是这样实现的:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
复杂度分析
基数排序的时间复杂度是O(k·n),其中n是排序元素个数,k是数字位数。注意这不是说这个时间复杂度一定优于O(n·log(n)),k的大小取决于数字位的选择(比如比特位数),和待排序数据所属数据类型的全集的大小;k决定了进行多少轮处理,而n是每轮处理的操作数目。
k约等于logB(N)
所以,基数排序的平均时间T就是:
T~= logB(N)·n
其中前一项是一个与输入数据无关的常数,当然该项不一定小于logn
如果考虑和比较排序进行对照,基数排序的形式复杂度虽然不一定更小,但由于不进行比较,因此其基本操作的代价较小,而且在适当选择的B之下,k一般不大于logn,所以基数排序一般要快过基于比较的排序,比如快速排序。
例如
待排序数组[62,14,59,88,16]简单点五个数字
分配10个桶,桶编号为0-9,以个位数数字为桶编号依次入桶,变成下边这样
| 0 | 0 | 62 | 0 | 14 | 0 | 16 | 0 | 88 | 59 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |桶编号
将桶里的数字顺序取出来,
输出结果:[62,14,16,88,59]
再次入桶,不过这次以十位数的数字为准,进入相应的桶,变成下边这样:
由于前边做了个位数的排序,所以当十位数相等时,个位数字是由小到大的顺序入桶的,就是说,入完桶还是有序
| 0 | 14,16 | 0 | 0 | 0 | 59 | 62 | 0 | 88 | 0 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |桶编号
因为没有大过100的数字,没有百位数,所以到这排序完毕,顺序取出即可
最后输出结果:[14,16,59,62,88]
In [17]:
import math # 求log和上约界
def radix_sort(alist,radix=10):
# 首先计算入桶的次数
k = int( math.ceil(math.log(max(alist),radix)) ) # math.ceil返回的是整数
# 然后每个数k次进桶
## 首先定义一个可以接受list的桶的序列
result = [ i for i in alist]
bucket = [[] for i in range(radix) ] # 按照基数大小确定桶的个数多少
for i in range(k):
for item in result: # 每次使用上次排完序的内容
# 求当前位上应该对应的桶号;
## 这里不必担心位数多少的问题,因为位数不够下面求完就是0
bucket[ item%(radix**(i+1))/(radix**i) ].append(item)
# 然后合并各个桶
del result[:]
for small_bucket in bucket:
result.extend(small_bucket)
bucket = [[] for i in range(radix)]
return result
unsortedArray = [26, 25, 23,5, 36, 5,3, 17, 3, 6,12,23,34,35,]
sortedArray = radix_sort(unsortedArray,10)
print sortedArray [3, 3, 5, 5, 6, 12, 17, 23, 23, 25, 26, 34, 35, 36]