对dpdk的rte_ring实现原理和代码分析
对dpdk的rte_ring实现原理和代码分析
前言
dpdk的rte_ring是借鉴了linux内核的kfifo实现原理,这里统称为无锁环形缓冲队列。
环形缓冲区通常有一个读指针和一个写指针。读指针指向环形缓冲区中可读的数据,写指针指向环形缓冲区中可写的数据。通过移动读指针和写指针就可以实现缓冲区的数据读取和写入。
在通常情况下,环形缓冲区的读用户仅仅会影响读指针, 而写用户仅仅会影响写指针。如果仅仅有一个读用户和一个写用户,那么不需要添加互斥保护机制就可以保证数据的正确性。
但是,如果有多个读写用户访问环形缓冲区, 那么必须添加互斥保护机制来确保多个用户互斥访问环形缓冲区。 具体来讲,如果有多个写用户和一个读用户,那么只是需要给写用户加锁进行保护;反之,如果有一个写用户和多个读用户,那么只是需要对读用户进行加锁保护。
所以这里说它是无锁,其实我是持保留态度的,只有在单生产单消费的场景下,才能说它是正在的无锁,多生产或者多消费的场景下,必须要加锁来保护才行,kfifo提供了自旋锁保护,而dpdk提供了原子锁cas来保护。
备注:dpdk版本18.11, 以下图片来自dpdk的prog_guide-master.pdf. dpdk官网编程指南手册
本人从dpdk移植了ring实现到自己的github里面 https://github.com/air5005/usg/tree/master/libs/libring 有兴趣的可以参考
rte_ring的实现原理
单生产者入队
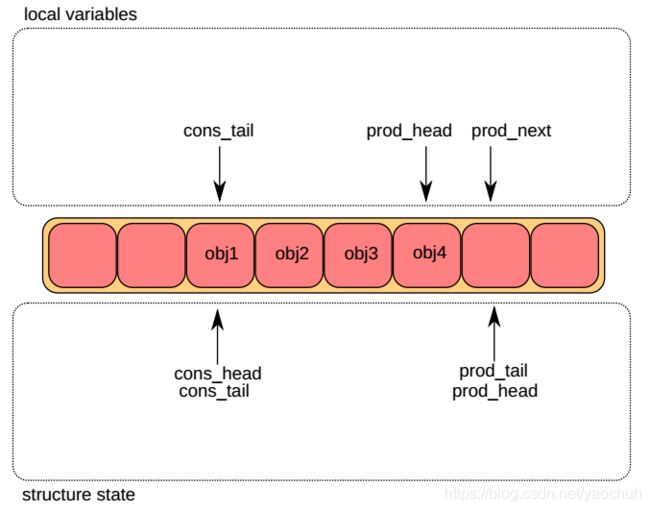
当只有一个生产者增加一个对象到环形缓冲区,这个时候只有一个生产者头和尾(prod_head和prod_tail)被修改。这个初始状态是有一个生产者的头和尾指向了相同的位置。
- 第一步
将r->prod.head保存到变量的prod_head, prod_next = prod_head + n,如下图
(在代码里面的话,临时变量prod_head = old_head. prod_next = new_head)

- 第二步
修改prod_head去指向prod_next指向的位置。 指向新增加对象的指针被拷贝到ring(obj4)。

- 第三步
一旦这个对象被增加到环形缓冲区中,prod_tail将要被修改成prod_head指向的位置。 至此, 这入队操作完成了。
单消费者出队
当只有一个消费者出队操作在环形缓冲区,这个时候只有一个消费者头和尾(cons_head和cons_tail)被修改并且这只有一个消费者。初始状态是一个消费者的头和尾指向了相同的位置。
- 第一步
首先,暂时将消费者的头索引和生产者的尾部索引交给临时变量,并且将cons_next指向表中下一个对象,如果在这环形缓冲区没有足够的对象,将返回一个错误。

- 第二步
第二步是修改cons_head去指向cons_next指向的位置,并且指向出队对象(obj1)的指针被拷贝到一个临时用户定义的指针中。

- 第三步
最后,cons_tail被修改成指向cons_head指向的位置。至此,单消费者的出队操作完成了。

多生产者入队
- 初始状态下,环形缓冲区的状态是prod_head和prod_tail都指向同一个位置,这个时候core1和core2都保存prod_head到各自的临时变量,如果core1和core2是同时执行这个动作的话,他们的临时变量保存的prod_head和prod_next应该完全相同。如下图所示:

- 在core1上面执行cas,比较prod_head和临时变量里面的prod_head,如果相同则把prod_head移动到prod_next,这个时候再core2也是执行完全一下的动作,由于使用的是cas,原子操作的比较和设置,只能有一个是成功的,这里如果是core1成功的话,那么core2的cas就是失败的。
所以这个时候ring里面的prod_head移动到core1的prod_next这个位置了并填充obj4到ring里面。

- core2在执行第一次cas的时候失败了,这个时候再执行一次,重新update临时变量里面的prod_head和prod_next,由于core1已经cas成功,那么这个时候core2 update到的这两个值就相应的更新了,这个时候再执行cas,则能成功,所以这个时候ring里面的prod_head移动到core2的prod_next这个位置并填充obj5到ring里面。

- core1在更新完ring的prod_head和obj后,这个时候临时变量里面保存的prod_head和prod_next是固定的,这个时候需要借助这两个值,当ring里面的prod_tail == prod_head(临时变量)的时候,即可直接更新prod_tail = prod_next, 这里的更新tail条件是唯一的,否则不能更新。

- core2在更新完ring的prod_head和obj后,这个时候临时变量里面保存的prod_head和prod_next是固定的,同理,core2也需要判断当ring里面的prod_tail == prod_head(临时变量)的时候,即可直接更新prod_tail = prod_next, 如果这个时候core1还没有update这个tail值的话,core2需要一直等待,知道core1更新了tail值位置才行(因为core1更新head值在core2之前,所以core1更新tail值也需要在core2之前)。

多消费者出队
多消费者出列和多生产者入列的实现逻辑大致相同,也是先更新cons head、存储obj、最后更新cons tail,具体这里就不一一罗列出来了,下面我们看具体代码的实现。
代码分析
rte_ring 结构体
struct rte_ring {
/*
* Note: this field kept the RTE_MEMZONE_NAMESIZE size due to ABI
* compatibility requirements, it could be changed to RTE_RING_NAMESIZE
* next time the ABI changes
*/
char name[RTE_MEMZONE_NAMESIZE] __rte_cache_aligned; /**< Name of the ring. */
int flags; /**< Flags supplied at creation. */
const struct rte_memzone *memzone;
/**< Memzone, if any, containing the rte_ring */
uint32_t size; /**< Size of ring. */
uint32_t mask; /**< Mask (size-1) of ring. */
uint32_t capacity; /**< Usable size of ring */
char pad0 __rte_cache_aligned; /**< empty cache line */
/** Ring producer status. */
struct rte_ring_headtail prod __rte_cache_aligned;
char pad1 __rte_cache_aligned; /**< empty cache line */
/** Ring consumer status. */
struct rte_ring_headtail cons __rte_cache_aligned;
char pad2 __rte_cache_aligned; /**< empty cache line */
};
struct rte_ring结构体主要包含一个生产者prod和一个消费者cons,还有ring本身支持加入obj数量的容量大小,
这个过程struct rte_ring、struct rte_ring_headtail都设置了cache line对其,防止出现cache miss的情况.
struct rte_ring_headtail {
volatile uint32_t head; /**< Prod/consumer head. */
volatile uint32_t tail; /**< Prod/consumer tail. */
uint32_t single; /**< True if single prod/cons */
};
rte_ring_headtail 实现了head和tail,环形链表两个游标,还有一个single,标示是单操作者还是多操作者.
创建ring rte_ring_create
struct rte_ring *
rte_ring_create(const char *name, unsigned count, int socket_id,
unsigned flags)
{
char mz_name[RTE_MEMZONE_NAMESIZE];
struct rte_ring *r;
struct rte_tailq_entry *te;
const struct rte_memzone *mz;
ssize_t ring_size;
int mz_flags = 0;
struct rte_ring_list* ring_list = NULL;
const unsigned int requested_count = count;
int ret;
/* 获取rte_ring_tailq链表,用来保存ring,方便定位查看系统存在的ring */
ring_list = RTE_TAILQ_CAST(rte_ring_tailq.head, rte_ring_list);
/* 判断flags表示是否设置了RING_F_EXACT_SZ, RING_F_EXACT_SZ的话,内部会
把count做一个调整,调整为2的指数次方,否则要求外面带进来的count本身就是
2的指数次方*/
/* for an exact size ring, round up from count to a power of two */
if (flags & RING_F_EXACT_SZ)
count = rte_align32pow2(count + 1);
/* 根据count获取ring需要的大小,
ring_size的大小计算如下
ring_size = sizeof(struct rte_ring) + count * sizeof(void *);
ring_size = RTE_ALIGN(ring_size, RTE_CACHE_LINE_SIZE);
即等于sizeof(struct rte_ring)+count个指针的大小,所以ring用来保存的
数据就是指针.
*/
ring_size = rte_ring_get_memsize(count);
if (ring_size < 0) {
rte_errno = ring_size;
return NULL;
}
/* 填充一下ring的名字,RTE_RING_MZ_PREFIX+name */
ret = snprintf(mz_name, sizeof(mz_name), "%s%s",
RTE_RING_MZ_PREFIX, name);
if (ret < 0 || ret >= (int)sizeof(mz_name)) {
rte_errno = ENAMETOOLONG;
return NULL;
}
/* 申请一下rte_ring_tailq的节点,挂到rte_ring_tailq尾部 */
te = rte_zmalloc("RING_TAILQ_ENTRY", sizeof(*te), 0);
if (te == NULL) {
RTE_LOG(ERR, RING, "Cannot reserve memory for tailq\n");
rte_errno = ENOMEM;
return NULL;
}
/* 读写锁保护tailq操作 */
rte_rwlock_write_lock(RTE_EAL_TAILQ_RWLOCK);
/* reserve a memory zone for this ring. If we can't get rte_config or
* we are secondary process, the memzone_reserve function will set
* rte_errno for us appropriately - hence no check in this this function */
mz = rte_memzone_reserve_aligned(mz_name, ring_size, socket_id,
mz_flags, __alignof__(*r));
if (mz != NULL) {
r = mz->addr;
/* no need to check return value here, we already checked the
* arguments above */
/* 对ring里面变量做初始化操作 */
rte_ring_init(r, name, requested_count, flags);
te->data = (void *) r;
r->memzone = mz;
TAILQ_INSERT_TAIL(ring_list, te, next);
} else {
r = NULL;
RTE_LOG(ERR, RING, "Cannot reserve memory\n");
rte_free(te);
}
rte_rwlock_write_unlock(RTE_EAL_TAILQ_RWLOCK);
return r;
}
int
rte_ring_init(struct rte_ring *r, const char *name, unsigned count,
unsigned flags)
{
int ret;
/* compilation-time checks */
RTE_BUILD_BUG_ON((sizeof(struct rte_ring) &
RTE_CACHE_LINE_MASK) != 0);
RTE_BUILD_BUG_ON((offsetof(struct rte_ring, cons) &
RTE_CACHE_LINE_MASK) != 0);
RTE_BUILD_BUG_ON((offsetof(struct rte_ring, prod) &
RTE_CACHE_LINE_MASK) != 0);
/* init the ring structure */
memset(r, 0, sizeof(*r));
ret = snprintf(r->name, sizeof(r->name), "%s", name);
if (ret < 0 || ret >= (int)sizeof(r->name))
return -ENAMETOOLONG;
r->flags = flags;
r->prod.single = (flags & RING_F_SP_ENQ) ? __IS_SP : __IS_MP;
r->cons.single = (flags & RING_F_SC_DEQ) ? __IS_SC : __IS_MC;
if (flags & RING_F_EXACT_SZ) {
r->size = rte_align32pow2(count + 1);
r->mask = r->size - 1;
r->capacity = count;
} else {
if ((!POWEROF2(count)) || (count > RTE_RING_SZ_MASK)) {
RTE_LOG(ERR, RING,
"Requested size is invalid, must be power of 2, and not exceed the size limit %u\n",
RTE_RING_SZ_MASK);
return -EINVAL;
}
r->size = count;
r->mask = count - 1;
r->capacity = r->mask;
}
r->prod.head = r->cons.head = 0;
r->prod.tail = r->cons.tail = 0;
return 0;
}
具体创建一个ring的函数流程如上,具体我在代码里面加了每个操作的注释,主要分为以下几个流程:
- 确定count数量,需要满足是2的指数次方
- 申请内存,具体ring size=sizeof(struct rte_ring) + count * sizeof(void *),通过rte_memzone_reserve_aligned申请内存
- 申请tailq节点,加入rte_ring_tailq链表里面,用来保存ring,方便定位查看系统存在的ring
- 使用rte_ring_init初始化ring结构体
入队列
入队列操作主要分为三个流程
- 更新r->prod.head
static __rte_always_inline unsigned int
__rte_ring_move_prod_head(struct rte_ring *r, unsigned int is_sp,
unsigned int n, enum rte_ring_queue_behavior behavior,
uint32_t *old_head, uint32_t *new_head,
uint32_t *free_entries)
{
const uint32_t capacity = r->capacity;
unsigned int max = n;
int success;
do {
/* Reset n to the initial burst count */
n = max;
*old_head = r->prod.head;
/* add rmb barrier to avoid load/load reorder in weak
* memory model. It is noop on x86
*/
rte_smp_rmb();
/*
* The subtraction is done between two unsigned 32bits value
* (the result is always modulo 32 bits even if we have
* *old_head > cons_tail). So 'free_entries' is always between 0
* and capacity (which is < size).
*/
/* 计算当前可用容量,
cons.tail是小于等于prod.head, 所以r->cons.tail - *old_head得到一个
负数,capacity减这个差值就得到剩余的容量 */
*free_entries = (capacity + r->cons.tail - *old_head);
/* check that we have enough room in ring */
if (unlikely(n > *free_entries))
n = (behavior == RTE_RING_QUEUE_FIXED) ?
0 : *free_entries;
if (n == 0)
return 0;
/* 新头的位置 */
*new_head = *old_head + n;
/* 如果是单生产者,直接更新r->prod.head即可,不需要加锁 */
if (is_sp)
r->prod.head = *new_head, success = 1;
/* 如果是多生产者,需要使用cmpset比较,如果&r->prod.head == *old_head
则&r->prod.head = *new_head
否则重新循环,获取新的*old_head = r->prod.head,知道成功位置*/
else
success = rte_atomic32_cmpset(&r->prod.head,
*old_head, *new_head);
} while (unlikely(success == 0));
return n;
}
- 将obj存放到r指定位置
/* r经过__rte_ring_move_prod_head处理后,r->prod.head已经移动到想要的位置
&r[1]是数据的位置, prod_head是旧的r->prod.head,obj_table是要加入的obj
ENQUEUE_PTRS的处理目的是把对应个数的obj存放到r的指定位置里面,由于
obj在r里面坑已经站好,所以这里只要按指定填充即可,不需要加锁
*/
#define ENQUEUE_PTRS(r, ring_start, prod_head, obj_table, n, obj_type) do { \
unsigned int i; \
const uint32_t size = (r)->size; \
uint32_t idx = prod_head & (r)->mask; \
obj_type *ring = (obj_type *)ring_start; \
if (likely(idx + n < size)) { \
for (i = 0; i < (n & ((~(unsigned)0x3))); i+=4, idx+=4) { \
ring[idx] = obj_table[i]; \
ring[idx+1] = obj_table[i+1]; \
ring[idx+2] = obj_table[i+2]; \
ring[idx+3] = obj_table[i+3]; \
} \
switch (n & 0x3) { \
case 3: \
ring[idx++] = obj_table[i++]; /* fallthrough */ \
case 2: \
ring[idx++] = obj_table[i++]; /* fallthrough */ \
case 1: \
ring[idx++] = obj_table[i++]; \
} \
} else { \
for (i = 0; idx < size; i++, idx++)\
ring[idx] = obj_table[i]; \
for (idx = 0; i < n; i++, idx++) \
ring[idx] = obj_table[i]; \
} \
} while (0)
- 更新r->prod.tail
static __rte_always_inline void
update_tail(struct rte_ring_headtail *ht, uint32_t old_val, uint32_t new_val,
uint32_t single, uint32_t enqueue)
{
if (enqueue)
rte_smp_wmb();
else
rte_smp_rmb();
/*
* If there are other enqueues/dequeues in progress that preceded us,
* we need to wait for them to complete
*/
/* 如果是多生产者流程,这里需要等待tail等于我们想要的old val
因为是多生产者,这里需要等其他prod把这个tail update,这里的
能成立*/
if (!single)
while (unlikely(ht->tail != old_val))
rte_pause();
/* 更新tail */
ht->tail = new_val;
}
完整函数如下:
static __rte_always_inline unsigned int
__rte_ring_do_enqueue(struct rte_ring *r, void * const *obj_table,
unsigned int n, enum rte_ring_queue_behavior behavior,
unsigned int is_sp, unsigned int *free_space)
{
uint32_t prod_head, prod_next;
uint32_t free_entries;
/* 更新r->prod.head指针操作 */
n = __rte_ring_move_prod_head(r, is_sp, n, behavior,
&prod_head, &prod_next, &free_entries);
if (n == 0)
goto end;
/* r经过__rte_ring_move_prod_head处理后,r->prod.head已经移动到想要的位置
&r[1]是数据的位置, prod_head是旧的r->prod.head,obj_table是要加入的obj
ENQUEUE_PTRS的处理目的是把对应个数的obj存放到r的指定位置里面,由于
obj在r里面坑已经站好,所以这里只要按指定填充即可,不需要加锁
*/
ENQUEUE_PTRS(r, &r[1], prod_head, obj_table, n, void *);
/* 更新r->prod.tail指针操作 */
update_tail(&r->prod, prod_head, prod_next, is_sp, 1);
end:
if (free_space != NULL)
*free_space = free_entries - n;
return n;
}
出队列
出队列操作流程和入队列流程基本一致,也是分为三部分,不过操作的是cons指针
-
更新r->cons.head
-
将obj从r指定位置移除
-
更新r->cons.tail
static __rte_always_inline unsigned int
__rte_ring_do_dequeue(struct rte_ring *r, void **obj_table,
unsigned int n, enum rte_ring_queue_behavior behavior,
unsigned int is_sc, unsigned int *available)
{
uint32_t cons_head, cons_next;
uint32_t entries;
/* 更新r->cons.head */
n = __rte_ring_move_cons_head(r, (int)is_sc, n, behavior,
&cons_head, &cons_next, &entries);
if (n == 0)
goto end;
DEQUEUE_PTRS(r, &r[1], cons_head, obj_table, n, void *);
/* 更新r->cons.tail */
update_tail(&r->cons, cons_head, cons_next, is_sc, 0);
end:
if (available != NULL)
*available = entries - n;
return n;
}
ring衍生出来的api
rte_ring_mp_enqueue_bulk 多生产者批量入队列,数量要求固定
rte_ring_sp_enqueue_bulk 单生产者批量入队列,数量要求固定
rte_ring_enqueue_bulk 生产者批量入队列,同时支持单生产和多生产,数量要求固定
rte_ring_mp_enqueue 多生产者单次入队列
rte_ring_sp_enqueue 单生产者单次入队列
rte_ring_enqueue 生产者单次入队列,同时支持单生产和多生产
rte_ring_mc_dequeue_bulk 多消费者批量出队列,数量要求固定
rte_ring_sc_dequeue_bulk 单消费者批量出队列,数量要求固定
rte_ring_dequeue_bulk 消费者批量出队列,同时支持单消费和多消费,数量要求固定
rte_ring_mc_dequeue 多消费者单次出队列
rte_ring_sc_dequeue 单消费者单次出队列
rte_ring_dequeue 消费者单次出队列,同时支持单消费和多消费
rte_ring_count 已经加入的obj数量
rte_ring_free_count 剩余容量
rte_ring_full 判断ring是否已经满了,没有容量了
rte_ring_empty 判断ring是否为空
rte_ring_get_size 获取ring的大小
rte_ring_get_capacity 获取ring的最大容量
rte_ring_list_dump 打印系统所有ring的信息
rte_ring_lookup 根据名字查找ring是否存在
rte_ring_mp_enqueue_burst 多生产者批量入队列,如果ring可用容量不够,加入最大能加入的数量
rte_ring_sp_enqueue_burst 单生产者批量入队列,如果ring可用容量不够,加入最大能加入的数量
rte_ring_enqueue_burst 生产者批量入队列,同时支持单生产和多生产,如果ring可用容量不够,加入最大能加入的数量
rte_ring_mc_dequeue_burst 多消费者批量出队列,如果ring可用容量不够,加入最大能加入的数量
rte_ring_sc_dequeue_burst 单消费者批量出队列,如果ring可用容量不够,加入最大能加入的数量
rte_ring_dequeue_burst 消费者批量出队列,同时支持单消费和多消费,如果ring可用容量不够,加入最大能加入的数量
已知问题
rte_ring是不可抢占的,如果遇到多任务抢占的情况下,可能导致死锁。
- 在同一个ring执行多生产者入队列操作的时候,该pthread不能被在同一环上执行多生产者队列的其他pthread抢占
- 在同一个ring执行多消费者出队列操作的时候,该pthread不能被另一个在同一环上执行多消费者出队列操作的pthread抢占
如果出现以上两种情况,可能会导致第二个pthread旋转,直到第一个pthread再次被调度。甚至如果第一个pthread被具有更高优先级的上下文抢占,它甚至可能导致死锁。
使用ring的时候,需要谨慎考虑任务的抢占,单生产和单消费都是支持抢占的,但是多生产或者多消费在抢占情况下会有概率出现死锁。