python 并发编程
操作系统的历史
- 多道操作系统
- 当遇到IO操作时候就切换
- 提高cpu的利用率
- 进程之间数据隔离
- 时空复用:在同一个时间点上,多个程序同时执行着,一块内存上存储了多少进程的数据
- 时间分片
- 时间片轮转
进程
- 是计算机最小的资源分配单位:每一个程序在运行起来的时候需要分配一些内存
- 一个运行的程序
- 在操作系统中用pid来标识一个进程
- 一般开启进程不会超过cpu个数的两倍
- 进程的调度算法
- 先来先服务:先来先调度
- 短作业优先:短作业或短进程优先
- 时间片论法:每个进程就绪时间和享受时间成比例。在规定时间片内为完成,释放cpu排就绪队列队尾
- 多级反馈算法:设置多个就绪对列,先来先按规定时间片执行,没完成放到第下一个就绪队列第一个。当第一就绪对接为空时,开始第二就绪队列执行
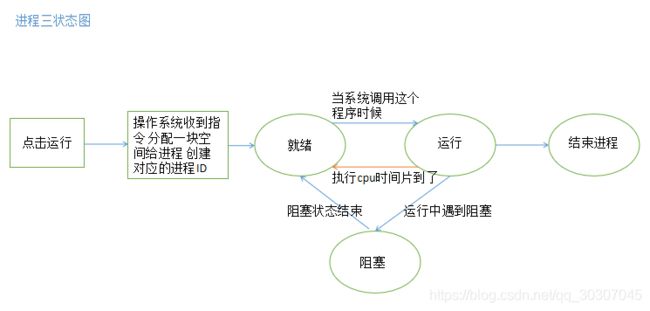
- 进程的结束
- 正常退出:自愿,如用户点击交互页面退出
- 出错退出:自愿,如python中a.py中a.py不存在
- 严重错误:非自愿,如执行非法指令,引用不存在的内存
- 进程被杀死:非自愿,如kill -进程id
- 进程三状态图:

线程
- 计算机中能被cpu调度的最小单位:实际执行具体编译解释之后的代码是线程,所以cpu执行的是解释之后的线程中的代码
- 同一个进程中的多个线程能同时被不同cpu执行
- 数据共享,操作系统调度最小单位,可以利用多核操作系统调度
- 数据不安全,开启和关闭切换时间开销小
并发和并行
- 并发:一个cpu,多个程序轮流执行
- 并行:多个cpu,各自在自己的cpu上执行程序
同步和异步
- 同步:调用一个操作,要等待结果
- 异步:调用一个操作,不需要等待结果
阻塞和非阻塞
- 阻塞:cpu不工作
- 非阻塞:cpu工作
同步/异步与阻塞/非阻塞
- 同步阻塞:效率最低,调用一个函数需要等待这个函数的执行结果,并且在执行这个函数的过程中cpu不工作。input
- 同步非阻塞:实际上效率低下,调用一个函数需要等待这个函数的执行结果,在执行函数过程中cpu工作。eval,sum
- 异步阻塞:调用一个函数不需要等待这个函数的执行结果,并且在执行这个函数过程中cpu不工作。
- 异步非阻塞:调用一个函数不需要等待这个函数的执行结果,并且在执行这个函数过程中cpu工作。start
进程相关代码:
multiprocessing模块
# 参数说明
Process([group [, target [, name [, args [, kwargs]]]]])
1 group参数未使用,值始终为None
2 target表示调用对象,即子进程要执行的任务
3 args表示调用对象的位置参数元组,args=(1,2,'egon',)
4 kwargs表示调用对象的字典,kwargs={'name':'egon','age':18}
5 name为子进程的名称# 方法介绍
1 p.start():启动进程,并调用该子进程中的p.run()
2 p.run():进程启动时运行的方法,正是它去调用target指定的函数,自定义类的类中一定要实现该方法
3 p.terminate():强a制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
4 p.is_alive():如果p仍然运行,返回True
5 p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程# 属性介绍
1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
2 p.name:进程的名称
3 p.pid:进程的pid
4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束
5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功from multiprocessing import Process
import os
def func(name):
print(f"hello {name} 我的第一个进程,我的父进程id:{os.getppid()},我的进程id:{os.getpid()}")
print("我是子进程")
if __name__ == '__main__':
arg_lst = [('路飞',), ('娜美',), ('索隆',), ('香吉士',)]
p_lst = []
for arg in arg_lst:
p = Process(target=func, args=arg)
p.start() # 异步非阻塞
p_lst.append(p)
for p in p_lst: p.join() # 同步阻塞
print(f"主进程完成,我的id:{os.getpid()}")
# 进程之间数据是隔离的
import os
import time
from multiprocessing import Process
class MyProcess(Process):
def __init__(self, a, b, c):
self.a = a
self.b = b
self.c = c
super().__init__()
def run(self):
time.sleep(1)
print(os.getppid(), os.getpid(), self.a, self.b, self.c)
if __name__ == '__main__':
for i in range(10):
p = MyProcess(1, 2, 3)
p.start()
守护进程
- 守护进程会等待主进程结束的代码结束后再结束,而不是等待整个主进程结束
- 主进程什么时候结束,守护进程什么时候结束,和其他子进程执行进度无关
- 主进程会等待所有的子进程结束后结束,是为了回收子进程的资源
import time
from multiprocessing import Process
def son1():
while True:
print('--> in son1')
time.sleep(1)
def son2(): # 执行10s
for i in range(10):
print('--> in son2')
time.sleep(1)
if __name__ == '__main__': # 3s
p1 = Process(target=son1)
p1.daemon = True # 表示设置p1是一个守护进程
p1.start()
p2 = Process(target=son2, )
p2.start()
time.sleep(3)
print('in main')
p2.join() # 等待p2结束之后才结束
锁Lock
- 会降低运行效率,但是保证数据安全
import time
from multiprocessing import Lock, Process
def func(i, lock):
with lock: # 代替注释的两句代码
# lock.acquire() # 拿钥匙
print('被锁起来的代码%s' % i)
# lock.release() # 还钥匙
time.sleep(1)
if __name__ == '__main__':
lock = Lock()
for i in range(10):
p = Process(target=func, args=(i, lock))
p.start()
队列
- 进程之间的数据是隔离的
- 进程之间的通信(IPC) Inter Process communication
- 基于文件:同一台机器上的多个进程之间通信
- Queue队列
- 基于socket的文件级别的通信来完成数据传递
- Queue队列
- 基于网络:同一台机器或多台机器上的多进程通信
- 第三方工具(消息中间件)
- memcache
- redis
- rabbitmq
- kafka
- 第三方工具(消息中间件)
- 基于文件:同一台机器上的多个进程之间通信
from multiprocessing import Queue, Process
def pro(q):
for i in range(10):
print(q.get())
def son(q):
for i in range(10):
q.put('hello%s' % i)
if __name__ == '__main__':
q = Queue()
p = Process(target=son, args=(q,))
p.start()
p = Process(target=pro, args=(q,))
p.start()
生产者和消费者模型
- 生产者(产生数据线程)和消费者(消费数据线程)不直接通讯,而是通过阻塞队列来进行通讯。
- 生产者产完数据直接扔给阻塞队列,不用等消费者处理。
- 消费者直接从阻塞队列拿数据,阻塞队列相当与一个缓存区,平衡消费者和生成者的处理能力。
- 完成了获取数据和处理数据解耦,根据能力不同,来规划个数,提高cpu使用率
import time
import random
from multiprocessing import Queue, Process
def consumer(q, name): # 消费者:通常取到数据之后还要进行某些操作
while True:
food = q.get()
if food:
print('%s吃了%s' % (name, food))
else:
break
def producer(q, name, food): # 生产者:通常在放数据之前需要先通过某些代码来获取数据
for i in range(10):
foodi = '%s%s' % (food, i)
print('%s生产了%s' % (name, foodi))
time.sleep(random.random())
q.put(foodi)
if __name__ == '__main__':
q = Queue()
c1 = Process(target=consumer, args=(q, '路飞1'))
c2 = Process(target=consumer, args=(q, '路飞2'))
p1 = Process(target=producer, args=(q, '香吉士1', '烤肉'))
p2 = Process(target=producer, args=(q, '香吉士2', '火腿'))
c1.start()
c2.start()
p1.start()
p2.start()
p1.join()
p2.join()
q.put(None)
q.put(None)
进程数据共享(一般不用)
from multiprocessing import Process, Lock, Manager
def change_dic(dic, lock):
with lock:
dic['count'] -= 1
if __name__ == '__main__':
lock = Lock()
m = Manager()
dic = m.dict({'count': 100})
p_lst = []
for i in range(100):
p = Process(target=change_dic, args=(dic, lock))
p.start()
p_lst.append(p)
for p in p_lst: p.join()
print(dic)
在CPython中的多线程
- gc 垃圾回收机制
- 引用计数+分代回收
- 全局解释器锁的出现主要是为了完成gc的回收机制,对不同的线程的引用计数的变化记录更加精准
- 全局解释器锁GIL(global interpreter lock)
- 导致了同一个进程中的多个线程只能有一个线程被cpu执行
- 多线程节省的是io操作的时间,而不是cpu计算的时间。

线程代码:
threading模块
import os
import time
from threading import Thread, current_thread, enumerate, active_count
def func(i):
print('start%s' % i, current_thread().ident)
time.sleep(1)
print('end%s' % i)
if __name__ == '__main__':
tl = []
for i in range(10):
t = Thread(target=func, args=(i,))
t.start()
print(t.ident, os.getpid())
tl.append(t)
print(enumerate(), active_count())
for t in tl: t.join()
print('所有的线程都执行完了')
# current_thread() 获取当前所在的线程的对象 current_thread().ident通过ident可以获取线程id
# enumerate 列表 存储了所有活着的线程对象,包括主线程
# active_count 数字 存储了所有活着的线程个数# 面向对象的方式起线程
from threading import Thread
class MyThread(Thread):
def __init__(self, a, b):
self.a = a
self.b = b
super().__init__()
def run(self):
print(self.ident)
t = MyThread(1, 2)
t.start()
print(t.ident)
# 线程之间的数据的共享
from threading import Thread
n = 100
def func():
global n
n -= 1
t_l = []
for i in range(100):
t = Thread(target=func)
t.start()
t_l.append(t)
for t in t_l:
t.join()
print(n)
守护线程
- 主进程会等待所有子线程结束而结束
- 守护线程随着主进程的结束而结束
- 守护线程会在主线程的代码结束之后继续守护其他子线程
- 所有线程都会随着进程的结束而被回收
- 其他子线程——>主线程结束——>主进程结束——>整个进程中资源被回收——>守护线程也会被回收
import time
from threading import Thread
def son():
while True:
print('in son')
time.sleep(1)
def son2():
for i in range(3):
print('in son2 ****')
time.sleep(1)
t = Thread(target=son)
t.daemon = True
t.start()
Thread(target=son2).start()
线程数据不安全现象
- 线程之间存在数据不安全
- 当进行+=、-=、*=、/= 等赋值运算之后,数据不安全
- 当if while等条件判断由多个线程完成,数据不安全
- 数据共享且异步,数据不安全
- append、pop、strip、queue、logging数据安全,列表或数字中的方法操作全局变量时候数据安全,因为内部实现了锁机制
- 可用dis模块,分别看都进行了什么操作,其实只要不操作全局变量,不要在类里操作静态变量就可避免大部分不安全问题
import dis
a = 0
def func():
global a
a += 1
dis.dis(func)
# 8 0 LOAD_GLOBAL 0 (a) 加载全局变量
# 2 LOAD_CONST 1 (1) 推入栈顶
# 4 INPLACE_ADD 进行计算a+1 = 1
# 6 STORE_GLOBAL 0 (a) 存储到全局变量 在6-8之间会触发GIL锁
# 8 LOAD_CONST 0 (None) 返回值操作return
# 0 RETURN_VALUE 返回值操作returnimport dis
a = []
def func():
a.append(1)
dis.dis(func)
# 4 0 LOAD_GLOBAL 0 (a)
# 2 LOAD_ATTR 1 (append)
# 4 LOAD_CONST 1 (1)
# 6 CALL_FUNCTION 1
# 8 POP_TOP # 将堆顶删除
# 10 LOAD_CONST 0 (None)
# 12 RETURN_VALUE
线程锁
from threading import Thread, Lock
n = 0
def add(lock):
for i in range(500000):
global n
with lock:
n += 1
def sub(lock):
for i in range(500000):
global n
with lock:
n -= 1
t_l = []
lock = Lock()
for i in range(2):
t1 = Thread(target=add, args=(lock,))
t1.start()
t2 = Thread(target=sub, args=(lock,))
t2.start()
t_l.append(t1)
t_l.append(t2)
for t in t_l:
t.join()
print(n)
单例模式的线程锁
import time
from threading import Thread
class A:
from threading import Lock
__instance = None
lock = Lock()
def __new__(cls, *args, **kwargs):
with cls.lock:
if not cls.__instance:
time.sleep(0.000001) # cpu轮转
cls.__instance = super().__new__(cls)
return cls.__instance
def func():
a = A()
print(a)
for i in range(10):
Thread(target=func).start()
递归锁
- Lock为互斥锁 效率高
- RLock为递归锁 效率相对低
- RLock是给一把万能钥匙,能依次开锁

from threading import RLock, Thread
rl = RLock() # 在同一个线程中可以被acquire多次
rl.acquire()
print('希望被锁住的代码')
rl.release()
def func(i, rlock):
rlock.acquire()
rlock.acquire()
print(i, ': start')
rlock.release()
rlock.release()
print(i, ': end')
rlock = RLock()
for i in range(5):
Thread(target=func, args=(i, rlock)).start()
死锁现象
- 多把(互斥锁/递归)锁,并且在多个线程中,交叉使用
- 如果互斥锁出现死锁,最快的解决办法是把所有的互斥锁都改成一把递归锁
- 互斥锁效率高,但是多把锁容易出现死锁现象,一把互斥锁就够了
- 递归锁效率低,解决死锁有奇效
import time
from threading import Thread, Lock, RLock
# fork_lock = noodle_lock = RLock() # 解决方案A:把互斥锁换成同一把递归锁
# fork_noodle_lock = Lock() # 解决方案B:换成同一把互斥锁,并让他完成完成逻辑后解锁
fork_lock = Lock()
noodle_lock = Lock()
def eat(name):
noodle_lock.acquire() # 方案B 换成fork_noodle_lock.acquire()
print(name, '抢到面了')
fork_lock.acquire() # 方案B 去掉该锁
print(name, '抢到叉子了')
print(name, '吃面')
time.sleep(0.1)
fork_lock.release() # 方案B 去掉该锁
print(name, '放下叉子了')
noodle_lock.release() # 方案B 换成fork_noodle_lock.release()
print(name, '放下面了')
def eat2(name):
fork_lock.acquire() # 方案B 同上面一样只锁一次
print(name, '抢到叉子了')
noodle_lock.acquire()
print(name, '抢到面了')
print(name, '吃面')
noodle_lock.release()
print(name, '放下面了')
fork_lock.release()
print(name, '放下叉子了')
Thread(target=eat, args=('路飞',)).start()
Thread(target=eat2, args=('娜美',)).start()
Thread(target=eat, args=('罗宾',)).start()
Thread(target=eat2, args=('索隆',)).start()
队列
- 线程之间数据安全的容器
- 实现原理:基于管道+锁 管道基于文件级别的socket+pickle实现的
- 具体用法看我另一篇博客 https://blog.csdn.net/qq_30307045/article/details/106966449
池
- 在程序开始的时候,还没提交任务先创建几个线程或者进程放到一个池子里,叫做池
池的意义
- 如果先开好进程/线程,那么有任务之后就可以直接使用这个池中的数据
- 并且开好的线程或进程会一直在池中,可以被多个任务反复利用
- 极大的减少了开启/关闭 调度线程/进程的时间开销
- 池中的线程/进程个数控制操作系统需要调度的任务个数,控制池中的单位
- 有利于提高操作系统的效率,减轻操作系统的负担
ThreadPoolExecutor线程池
- 一般线程池数量大于cpu_count 小于cpu_count*2
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
import time
import random
def func(a, b):
print(current_thread().ident, "start", a, b)
time.sleep(random.randint(1, 4))
print(current_thread().ident, "end")
tp = ThreadPoolExecutor(4) # 实例化,创建池
for i in range(20):
tp.submit(func, i, b=i+1) # 提交任务
ProcessPoolExecutor进程池
- 一般进程池数量不超过cpu_count*5
from concurrent.futures import ProcessPoolExecutor
import os
import time
import random
def func(a, b):
print(os.getpid(), "start", a, b)
time.sleep(random.randint(1, 4))
print(os.getpid(), "end")
if __name__ == '__main__':
pp = ProcessPoolExecutor(4) # 实例化,创建池
for i in range(20):
pp.submit(func, i, b=i+1) # 提交任务
获取任务结果
from concurrent.futures import ThreadPoolExecutor
import time
def func(a, b):
# time.sleep(1)
return a*b
tp = ThreadPoolExecutor(4) # 实例化,创建池
future_l = []
for i in range(20):
ret = tp.submit(func, i, b=i+1) # 提交任务
# print(ret) # 得到的是Future未来对象
# print(ret.result()) # 如果这里直接print结果会变成同步
future_l.append(ret)
for i in future_l:
print(i.result())
map
from concurrent.futures import ThreadPoolExecutor
def func(a):
# time.sleep(1)
return a[0]*a[1]
# map 只适合传递简单的参数 并且必须是一个可迭代类型的参数
tp = ThreadPoolExecutor(4)
ret = tp.map(func, ((i, i+1) for i in range(20)))
for i in ret:
print(i)
add_done_callback回调函数
- 效率最高,如果需要顺序排,可以在返回值时候做标识符
from concurrent.futures import ThreadPoolExecutor
import time
def func(a, b):
time.sleep(1)
return a*b
def print_func(ret):
print(ret.result())
tp = ThreadPoolExecutor(4)
# future_l = []
for i in range(20):
ret = tp.submit(func, i, i+1)
# future_l.append(ret)
ret.add_done_callback(print_func) # 异步阻塞 回调函数,给ret对象绑定回调函数,等ret对应任务有了结果后立即调用print_func函数
# 可以对结果进行立即处理,而不用按顺序接收结果处理结果
# for i in future_l: # 同步阻塞
# print(i.result())
协程
- 因为Cpython解释器下的多线程不能利用多核:规避所有io操作,所以需要协程来提高cpu使用率
- 协程是操作系统不可见的
- 协程的本质是一条线程,多个任务在一条线程上来回切换,来规避IO操作,就达到了我们将一条线程中的IO操作降到最低的目的
- 协程数据共享,数据安全。协程是一条线程的一部分,所以数据共享。协程需要手动切换,用户级别,不是计算机自动调度的,所以是数据安全的。
- 协程相对于进程和线程开销最小。进程>线程>协程
- 协程不能利用多核。
- 协程并不一定比线程更好,因为协程更多的是规避用户感知的IO操作(socket,网页操作),而线程能感知到的更多(一些和文件相关的IO操作,只有系统能感知到)
- 用户级别的协程好处:减轻了操作系统的负担;如果一条线程开启多个协程,会给cpu造成一直在执行的印象,能多争取到一些时间片时间被cpu执行,程序效率提高。

切换并规避IO的两个模块
- gevent 利用 greenlet(c语言)底层模块完成的切换 + 自动规避IO的功能
- asyncio 利用 yield(python)底层模块完成的切换 + 自动规避IO的功能
- tornado 异步的web框架 基于yield
- yield from 为了更好的实现协程添加的方法
- send 为了更好的实现协程添加的方法
gevent
# 能够判断出是io操作的
def patch_all(socket=True, dns=True, time=True, select=True, thread=True, os=True, ssl=True,
subprocess=True, sys=False, aggressive=True, Event=True,
builtins=True, signal=True,
queue=True, contextvars=True,
**kwargs):from gevent import monkey
monkey.patch_all()
import time
import gevent
def func(): # 带有io操作的内容写到函数里,然后提交给func的gevent
print("start func")
time.sleep(1) # conn.recv 等
print("end func")
g1 = gevent.spawn(func)
g2 = gevent.spawn(func)
g3 = gevent.spawn(func)
gevent.joinall([g1, g2, g3])
# 基于协程实现并发
# server端
from gevent import monkey
monkey.patch_all()
import socket
import gevent
def func(conn):
while True:
msg = conn.recv(1024).decode('utf-8')
MSG = msg.upper()
conn.send(MSG.encode('utf-8'))
sk = socket.socket()
sk.bind(('127.0.0.1', 8080))
sk.listen()
while True:
conn, _ = sk.accept()
gevent.spawn(func, conn)
# client端
import time
import socket
from threading import Thread
def client():
sk = socket.socket()
sk.connect(('127.0.0.1', 8080))
while True:
sk.send(b'hello')
msg = sk.recv(1024)
print(msg)
time.sleep(0.5)
for i in range(500):
Thread(target=client).start()
asyncio
import asyncio
async def func(name):
print("start", name)
# await 可能会发生阻塞的方法
# await 关键字必须卸载一个async函数里
await asyncio.sleep(1)
print("end")
loop = asyncio.get_event_loop() # 相当于计算阻塞时间的长短
# loop.run_until_complete(func("路飞"))
loop.run_until_complete(asyncio.wait([func("路飞"), func("娜美")]))