Datawhale组队学习第一章总结
1.1载入数据
1.1.1任务一:导入numpy和pandas
import numpy as np
import pandas as pd
1.1.2任务二:载入数据
(1)载入相对路径数据
df=pd.read_csv('train.csv')
df.head(3)
| – | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
(2)相对路径载入报错时,使用os.getcwd()查看当前工作目录
import os
cwd=os.getcwd()
os.chdir("G:\hands-on-data-analysis-master\第一单元项目集合")
df=pd.read_csv('train.csv')
思考:pd.read_csv()是以逗号为分隔符进行数据的加载,pd.read_table()加载全部数据为一列
1.1.3任务三:每1000行为一个数据模块,逐块读取
chunker=pd.read_csv('train.csv',chunksize=1000)
思考:逐块读取它的本质就是将文本分成若干块,每次处理chunksize行的数据,最终返回一个TextParser对象
1.1.4任务四:将表头改成中文
df=pd.read_csv('train.csv',names=['乘客ID','是否幸存','舱位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'],index_col='乘客ID',header=0)
df.head()
| – | 乘客ID | 是否幸存 | 舱位等级 | 姓名 | 性别 | 年龄 | 兄弟姐妹个数 | 父母子女个数 | 船票信息 | 票价 | 客舱 | 登船港口 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
1.2初步观察
1.2.1任务一:查看数据的基本信息
df.info()
df.info()
Int64Index: 891 entries, 1 to 891
Data columns (total 11 columns):
是否幸存 891 non-null int64
舱位等级 891 non-null int64
姓名 891 non-null object
性别 891 non-null object
年龄 714 non-null float64
兄弟姐妹个数 891 non-null int64
父母子女个数 891 non-null int64
船票信息 891 non-null object
票价 891 non-null float64
客舱 204 non-null object
登船港口 889 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 83.5+ KB
1.2.2任务二:观察表格前10行和后10行数据
df.head(10)#前10行数据
df.tail(10)#后10行数据
1.2.3任务三:判断数据是否为空,为空返回True,否则返回False
df.isnull().head()
1.3保存数据
1.3.1任务一:保存数据在一个新的路径
df.to_csv('train_chinese.csv')
1.4知道你的数据叫什么
1.4.1任务一:简单了解pandas中两个数据类型DateFrame和Series
#DateFrame
sdata={'姓名':['大黄','小美','飞飞','小明'],'体重':['99','98','180','140']}
sdata=pd.DataFrame(sdata)
sdata
体重 姓名
0 99 大黄
1 98 小美
2 180 飞飞
3 140 小明
#series
sdata={'大黄':99,'小美':98,'飞飞':180,'小明':140}
weight=pd.Series(sdata)
weight
大黄 99
小明 140
小美 98
飞飞 180
dtype: int64
1.4.2任务二:加载数据
train_data=pd.read_csv('train.csv')
1.4.3任务三:查看数据的每列的项
train_data.head(3)
1.4.4任务四:查看cabin这列的所有项
df['Cabin']
1.4.5任务五:加载test_1.csv,对比train.csv,然后将多出的列删除
#删除'Unnamed: 0','a'两列
test_data.drop(['Unnamed: 0','a'],axis=1,inplace=True)
1.4.6任务六:将[‘passengerid’,‘name’,‘age’,‘ticket’]这几个列元素隐藏,只观察其他几个列元素
df=pd.read_csv('train.csv')
df.drop(['PassengerId','Name','Age','Ticket'],axis=1)
1.5筛选的逻辑
1.5.1任务一:以age为筛选条件,显示年龄在10岁以下的乘客信息
df[df['Age']<10]
1.5.2任务二:以age为条件,将年龄在10岁到50岁之间乘客的信息显示出来,将其命名为midage
midage=df[(df['Age']>10)&(df['Age']<50)]
1.5.3任务三:将midage数据中第100行的pclass和sex的数据显示出来
midage=midage.reset_index(drop=True)#True代表删除之前索引False代表不删除之前索引
midage.loc[[99],['Pclass','Sex']]
1.5.4任务四:将midage数据中的第100,,15,108行的’Pclass‘,name,sex显示出来
midage.loc[[99,104,108],['Pclass','Name','Sex']]
1.5.5任务五:使用iloc将midage数据中第100,105,108的pclass,name,sex数据显示出来
midage.iloc[[99,104,108],[5,3,4]]
1.6了解你的数据吗?
1.6.1任务一:利用pandas对示例数据进行排序,要求升序
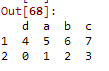
frame=pd.DataFrame(np.arange(8).reshape((2,4)),index=['2','1'],columns=['d','a','b','c'])
frame
frame.sort_values(by='c',ascending=False)
#按行索引
frame.sort_index()
#按列索引
frame.sort_index(axis=1)
#按列倒序索引
frame.sort_index(axis=1,ascending=False)
#任选两列降序索引
frame.sort_values(by=['a','c'])
1.6.2任务二:对泰坦尼克号数据按票价和年龄进行降序排列
df.sort_values(by=['Fare','Age'],ascending=False).head(3)
1.6.3任务三:利用pandas计算两个dataframe数据相加结果
frame_1=pd.DataFrame(np.arange(9.).reshape(3,3),columns=['a','b','c'],index=['one','two','three'])
frame_2=pd.DataFrame(np.arange(12.).reshape(4,3),columns=['a','e','c'],index=['first','one','two','second'])
frame_1+frame_2
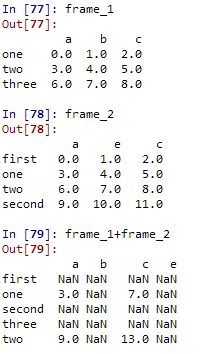
两个dataframe相加后会返回一个新的dataframe,对应的行和列的值会相加,没有对应的会变成空值NaN
1.6.4任务四:通过泰坦尼克号数据如何计算出在船上最大的家族有多少人?`
max(df['SibSp']+df['Parch'])
![]()
1.6.5任务五:使用describe()函数查看数据基本统计信息
frame2=pd.DataFrame([[1.4,np.nan],[7.1,-4.5],[np.nan,np.nan],[0.75,-1.3]],index=['a','b','c','d'],columns=['one','two'])
frame2
frame2.describe()

1.6.6任务六:分别看泰坦尼克号数据中票价,父母子女这列数据的基本信息
#票价
df['Fare'].describe()
#父母子女
df['Parch'].describe()