pytorch自然语言处理基础模型之四:TextRNN
1、模型原理
RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络。首先我们要明确什么是序列数据,摘取百度百科词条:时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,但总归序列数据有一个特点——后面的数据跟前面的数据有关系。
RNN网络的典型结构:
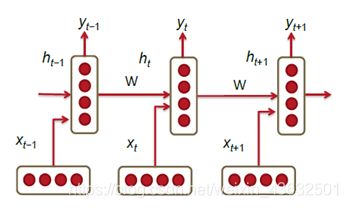
Xt表示在t时刻的输入,ht表示t时刻的隐藏层状态,yt表示t时刻的输出。每一个隐藏层都有许多的神经元,这些神经元将上一层的输入做线性变换(矩阵乘法,也就是乘以权重),然后再使用非线性激活函数进行激活。t时刻的输入Xt和t-1时刻的隐藏层状态作为t时刻隐藏层的输入,并由隐藏层产生t时刻的输出特征ht,再对ht使用全连接和softmax作为最终的输出。
2、代码实现
本文以简单数据集和网络结构实现TextRNN,数据集为三句话,取每句话的前两个词进行训练,用最后一个词进行验证,目的是便于读者更好的理解该网络的原理。
1. 导入需要的库,设置数据类型
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
dtype = torch.FloatTensor
2. 创建数据和字典
sentences = [ "i like dog", "i love coffee", "i hate milk"]
//join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict)
3. 创建batch
def make_batch(data):
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split()
inp = [word_dict[w] for w in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(np.eye(n_class)[inp])
target_batch.append(target)
return input_batch, target_batch
// to Torch.Tensor
input_batch, target_batch = make_batch(sentences)
input_batch = Variable(torch.Tensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch))
看一下生成的batch:
input_batch:
tensor([[[0., 0., 0., 0., 0., 1., 0.],
[0., 0., 1., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 1., 0.],
[0., 1., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0., 0., 0.]]])
target_batch:
tensor([6, 3, 4])
4. 定义网络参数
// TextRNN Parameter
batch_size = len(sentences)
n_step = 2 // number of cells(= number of Step)
n_hidden = 5 // number of hidden units in one cell
5. 创建网络
class TextRNN(nn.Module):
def __init__(self):
super().__init__()
self.rnn = nn.RNN(input_size=n_class, hidden_size=n_hidden)
self.W = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
self.b = nn.Parameter(torch.randn(n_class).type(dtype))
def forward(self, X, h_0):
// transpose ,可以对矩阵的维度进行转换
// X : [batch_size, n_step, n_class] -> [n_step, batch_size, n_class]
X = X.transpose(0, 1)
// out : [n_step, batch_size, num_directions(=1) * n_hidden]
// h_n : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
out, h_n = self.rnn(X, h_0)
//为方便计算,我们这里只取最后一个序列的输出
out = out[-1] // [batch_size, num_directions(=1) * n_hidden]
// output : [batch_size, n_class]
output = torch.mm(out, self.W) + self.b
return output
6. 训练模型
model = TextRNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
// Training
for epoch in range(5000):
optimizer.zero_grad()
// hidden : [num_layers * num_directions, batch, hidden_size]
hidden = Variable(torch.zeros(1, batch_size, n_hidden))
// input_batch : [batch_size, n_step, n_class]
//output : [batch_size, n_class],
output = model(input_batch, hidden)
//target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
训练结果:
Epoch: 1000 cost = 0.120706
Epoch: 2000 cost = 0.022281
Epoch: 3000 cost = 0.008089
Epoch: 4000 cost = 0.003726
Epoch: 5000 cost = 0.001918
7. 验证模型
//predict
predict = output.data.max(1, keepdim=True)[1]
//squeeze:从数组的形状中删除单维度条目,若axis为空,则删除所有单维度的条目
print([sen.split()[:2] for sen in sentences], "->" ,[number_dict[i.item()] for i in predict.squeeze()])
验证结果:
[['i', 'like'], ['i', 'love'], ['i', 'hate']] -> ['dog', 'coffee', 'milk']
参考链接
https://blog.csdn.net/zhaojc1995/article/details/80572098
https://www.cnblogs.com/puheng/p/9379730.html
https://github.com/graykode/nlp-tutorial