pytorch加载自定义数据集
我们在学习Pytorch进行文本处理时,所使用的数据集基本上都为官方提供的处理好的,调用torchtext中的相应函数即可实现对数据的处理。那么当我们需要加载自己的数据集时该怎么办呢,本文将以txt文件为例讲解一下如何加载。
我们的txt文件包含852471行,每一行如图所示为一句话
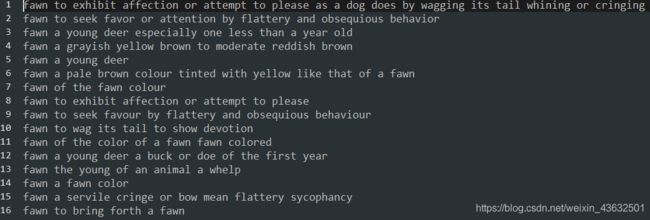
我们将使用torch.utils.data中包含的相关类,将该文件分割成训练集和验证集,并生成迭代器。
1、导入相关类
import os
from torch.utils.data import Dataset, random_split, DataLoader
torch.utils.data.Dataset: 一个抽象类, 所有其他类的数据集类都应该是它的子类。而且其子类必须重载两个重要的函数:len(提供数据集的大小)、getitem(支持整数索引)。
torch.utils.data.random_split(dataset, lengths): 按照给定的长度将数据集划分成没有重叠的新数据集组合。
torch.utils.data.DataLoader: 数据加载器。组合了一个数据集和采样器,并提供关于数据的迭代器。
2、定义我们自己的dataset类
class MyDataset(Dataset):
def __init__(self, instances):
self.instances = instances
//数据集的样本总数
def __len__(self):
return len(self.instances)
//建立索引,通过索引来读取数据集中样本
def __getitem__(self, index):
return self.instances[index]
3、定义文件读取函数,划分训练集和验证集
//定义文件路径
data_path = os.path.join(os.getcwd(), '.data/reverse')
def make_data(txt_file):
data = []
with open(os.path.join(data_path, txt_file), encoding='utf-8') as fr:
for line in fr.readlines():
data.append(line)
full_data = MyDataset(data)
//将训练集与验证集按照9:1进行划分
train_size = int(0.9 * len(full_data))
val_size = len(full_data) - train_size
train_data, val_data = random_split(full_data, [train_size, val_size])
return train_data, val_data
train_data, val_data = make_data('dataset.txt')
random_split: 按照给定的长度将数据集划分成没有重叠的新数据集组合。
划分后的数据集大小:
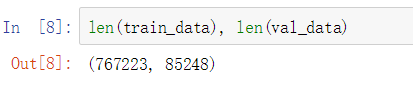
保存成新的txt文件:
with open("train_data.txt","w", encoding='utf-8') as fw:
for i,data in enumerate(train_data):
fw.writelines(data)
看一下训练集样本:
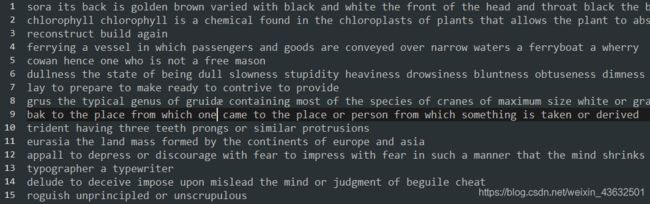
4、最后,定义数据集加载器,生成的数据迭代器为pytorch的输入。
train_loader = DataLoader(dataset=train_data, batch_size=128, shuffle=True)
val_loader = DataLoader(dataset=val_data, batch_size=128, shuffle=True)
torch.utils.data.DataLoader:(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None): 数据加载器。组合了一个数据集和采样器,并提供关于数据的迭代器。
参数说明:
dataset (Dataset) – 需要加载的数据集(可以是自定义或者自带的数据集)。
batch_size – batch的大小(可选项,默认值为1)。
shuffle – 是否在每个epoch中shuffle整个数据集, 默认值为False,一般都设置为True。
sampler – 定义从数据中抽取样本的策略. 如果指定了, shuffle参数必须为False。
num_workers – 表示读取样本的线程数, 0表示只有主线程。
collate_fn – 合并一个样本列表称为一个batch。
pin_memory – 是否在返回数据之前将张量拷贝到CUDA。
drop_last (bool, optional) – 设置是否丢弃最后一个不完整的batch,默认为False。
timeout – 用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错。应该为非负整数。
参考链接
https://cloud.tencent.com/developer/article/1435013
https://blog.csdn.net/xholes/article/details/81410834