条件随机场CRF简介
Crf模型
1. 定义




一阶(只考虑y前面的一个)线性条件随机场:

相比于最大熵模型的输入x和输出y,crf模型的输入输出都是序列化以后的矢量,是对最大熵模型的序列扩展。
相比于最大熵模型的另外一个不同是,crf多出了一个维度j(j表示序列x的位置),即任意一个输出yi,都跟所有的输入x有关。
经过变换,crf概率模型可以转化为:
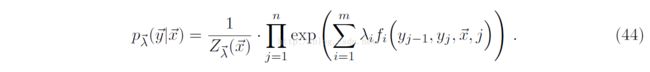
先求一个位置x的所有特征,再求所有位置x

先求一个维度特征所有位置,再求所有维度的特征
2. 特征
假设
输入x:北京天气
输出y:BMES
其中的一条训练语料及标注如下:
北 B
京 M
天 M
气 E
设计特征如下:
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
# Bigram
B
那么对于位置“天”,训练语料对应的特征为:
U00:%x[-2,0] 北
U01:%x[-1,0] 京
U02:%x[0,0] 天
U03:%x[1,0] 气
U04:%x[2,0] B+1
单独拿出来某一个特征,比如说“U02:%x[0,0]”来分析,对于整条训练语料来说,该特征可以表示如下:
f(B|U02:北) = 1
f(M|U02:京) = 1
f(M|U02:天) = 1
f(E|U02:气) = 1
特征函数有两种模板:
1. Unigram template
对应于状态特征Sl 。特征函数的个数有L*N个,其中L表示类别的种类个数,N表示根据模板扩展后的输入x的种类个数。
2. bigram template
对应于转移特征tk。转移特征函数的引入了yi-1(上一个token的输出类别),所以特征函数的个数为L*L*N。
如果只有一个B的话,代表概率对于所有的输入序列X都是一样的,所有特征函数的个数为N*N。
3. 模型结构
模型宏定义:
version:100
cost-factor:1 #代价参数,过大会导致过拟合
maxid: 69 #特征函数的个数
xsize: 1 #标记的列数
输出y的结果:
B
E
M
符合模板的所有x:
15U00:_B-1
0U00:_B-2
45 U00:京
30 U00:北
3U01:_B-1
33 U01:京
18 U01:北
48 U01:天
21 U02:京
6 U02:北
36 U02:天
51 U02:气
54U03:_B+1
9 U03:京
24 U03:天
39 U03:气
42U04:_B+1
57U04:_B+2
12 U04:天
27 U04:气
特征函数的权重:
0.3548558043014228
-0.1550525254028647
-0.1998032788985595
0.3548558043014228
-0.1550525254028647
-0.1998032788985595
0.3548558043014228
-0.1550525254028647
-0.1998032788985595
0.3548558043014228
-0.1550525254028647
-0.1998032788985595
…….
分成两部分的概率值,总共69个权重,其中9(3*3)个是转移概率,对应于模板的Bigram;剩下的60个权重是unigram:20(特征函数个数)*3(输出标记个数)。
4. 训练模型
目标函数:训练数据的对数似然函数
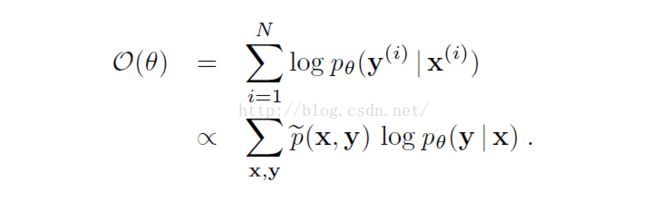
使用改进的迭代尺度法improved iterative scaling (IIS)


5. 求解概率
类似于hmm,使用维特比算法

对应于以上模型,测试语句为:
北天气
对应的解码输出为:
#0.488230
北 B B/0.630640 B/0.630640 E/0.081250 M/0.288110
天 M M/0.930957 B/0.033202 E/0.035841 M/0.930957
气 E E/0.811839 B/0.059784 E/0.811839 M/0.128377
第一行代表整句标注的概率,下面是每一个词对应的所有标注的边际概率值。

6. 使用
CRF++:
CRF++主要用于标注数据和切分数据,常见的应用有词性标注、命名实体识别、信息提取和文本组块分析、切词等。
使用stl和LBFGS算法,可以支持nbest输出
总结
1. 对比
hmm假设x之间相互独立,而且y只和前一个y有关。
MEMM模型相比于hmm,取消了x之间相互独立的假设,但是存在标记偏移的问题。
Crf模型取消了x之间相互独立的假设,当前y和前后y都有关联,解决了MEMM的标记偏移问题。
2. 标记偏移问题
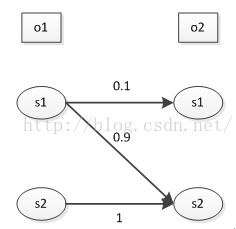
假设开始的观察值为o1,此时对应的状态的有两个s1和s2,如图所示,即使实际上由s1到s2的概率要高于s2到s2,但是由于概率归一化的问题,从s1状态出发边的概率和为1,从s2状态出发边的概率和为1,状态对应的出边的个数不同,从而导致竞争不合理的存在。
Hmm不存在这个问题:由于其不仅与转移概率有关,还跟对应的生成概率有关,生成概率特别小可以避免这种竞争不合理情况的存在。当MEMM状态的出边只有一条的时候,会忽略observation。
The critical difference betweenCRFs and MEMMs is that a MEMM uses per-state exponential models
for the conditional probabilitiesof next states given the current state, while a CRF has a single exponentialmodel for the joint probability of the entire sequence of labels given theobservation sequence. Therefore, the weights of different features at differentstates can be traded off against each other.
3. Crf模型的特点
优点:
序列断句和标注的区分性模型
综合了任意组合、过去未来的特征
基于动态编程的训练和解码方法
目标函数是凸函数,可以找到全局最优
缺点:
相比于MEMM,收敛速度慢,可以使用MEMM训练的结果作为参数起始值。
参考文献
《统计学习方法》李航
Conditional Random Fields: ProbabilisticModels for Segmenting and Labeling Sequence Data
Classical Probabilistic Models and ConditionalRandom Fields
Conditional Random Fields: An Introduction
基于条件随机场的古汉语自动断句与标点方法
基于前后文n-gram模型的古汉语句子切分https://taku910.github.io/crfpp/#source
http://www.hankcs.com/nlp/the-crf-model-format-description.html
http://www.52nlp.cn/中文分词入门之字标注法4
http://www.xuebuyuan.com/1635331.html