Spark:基于jieba分词的特征向量提取
基于jieba分词的对计算机课程名的特征向量提取
首先引入包:
import org.apache.spark.sql.{DataFrame, SparkSession}//spark入口,DataFrame操作需要用到的包
import java.nio.file.{Path, Paths}//加入自定义词库时路径需要的包
import com.huaban.analysis.jieba.{JiebaSegmenter, WordDictionary}//jieba分词需要用到的包
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}//特征向量提取需要用到的包
import scala.collection.mutable//java.util.List转换成scala Aarray需要用到的包
连接数据库得到DataFrame:
// 创建Spark入口
val spark = SparkSession.builder().getOrCreate()
/*这一行很关键!引入scala Encoder,使得scala拥有自动的RDD / DataFrame类型转换能力。*/
/*后面的map操作需要用到。若不引入,则会抛出Encoder缺失异常*/
// 关键!
import spark.implicits._
// 连接本项目测试数据库
val jdbcDF = spark.read.format("jdbc")
.option("url", "xxx")//为隐私就用xxx代替了
.option("driver", "com.mysql.jdbc.Driver")
.option("dbtable", "class_name")
.option("user", "rec")
.option("password", "cuclabcxg")
.load()
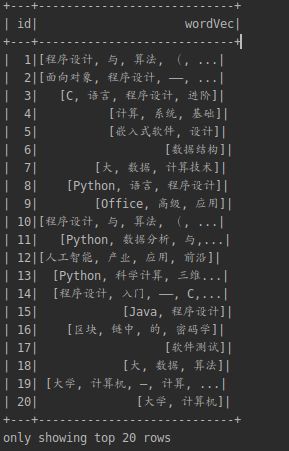
使用DataFrame的select()取列操作和filter()的取行操作,来取出我们要提取特征向量的DataFrame格式的数据。
//jieba加入自定义词库
//val path = Paths.get("/home/maples/lab/sogou.txt")
//WordDictionary.getInstance().loadUserDict(path)
//val jieba = new JiebaSegmenter()
//val res:String = jieba.sentenceProcess(text).toString()
//特征提取
//id - 分词 二维表
val id_word :DataFrame= jdbcDF.select("id","name")
.filter(jdbcDF("discipline")==="计算机")
.map(row =>(row.getInt(0),(new JiebaSegmenter()).sentenceProcess(row.getString(1)):mutable.Buffer[String]))
.toDF("id","wordVec")
id_word.show()
【注意这里】
1、我原先是这样写的:
val jieba = new JiebaSegmenter()
val id_word :DataFrame= jdbcDF.select("id","name")
.filter(jdbcDF("discipline")==="计算机")
.map(row =>(row.getInt(0),jieba.sentenceProcess(row.getString(1)):mutable.Buffer[String]))
.toDF("id","wordVec")
我先将JiebaSegmenter()对象在取DataFrame操作外面进行实例化,然后在.map()里调用jieba的分词方法。
会报以下错误:
Exception in thread "main" org.apache.spark.SparkException: Task not serializable......
大概意思是map()里的东西没有序列化,查阅博客后得知,jieba是运行在Driver端的,而map()是运行在Executor端的,两个操作是在不同地方执行的,所以我把new JiebaSegmenter()的操作搬到了map()里就ok了。
2、注意这里的id_word需要声明它的类型:DataFrame,包括后面新建的DataFrame对象都要声明它的类型为DataFrame,否则在调用这些DataFrame对象的时候,会报以下错误:
hashingTF.transform cannot resolve method 'transform'......
就是我在对id_word对象计算哈希值的时候,transform报红,识别不了我的id_word的类型。后面摸索发现需要在前面对这些对象声明类型(然而《Spark编程基础》几乎都没有声明类型)。
3、由于我对第二个字段即课程名进行分词后得到的是一个java.util.List类型,而特征提取的操作需要这里是一个scala的Array类型,所以需要引入包:
import scala.collection.JavaConversions.asScalaBuffer
import scala.collection.mutable
并且在分词结果后面加上 :mutable.Buffer[String]
jieba.sentenceProcess(row.getString(1)):mutable.Buffer[String]
关于java.util.List类型和scala Array之间的互相转换我找到一篇博客供参考:
https://www.jianshu.com/p/c4f6cbec8363
4、在声明变量类型后,DataFrame在初始化的时候后面就不能直接加.show()来打印输出,像这样:
var df :DataFrame = .......
.show()
因为这样=右边的返回值就是Unit不是DataFrame,会报错。
要这样写:
var df :DataFrame = .......
df.show()
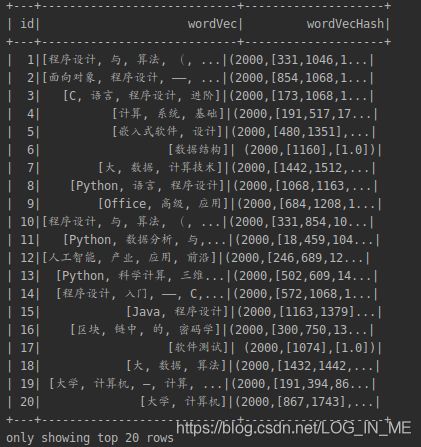
计算向量的Hash值:
//计算hash值
val hashingTF = new HashingTF()
.setInputCol("wordVec")
.setOutputCol("wordVecHash")
.setNumFeatures(2000)
val featureVec = hashingTF.transform(id_word)
.show()
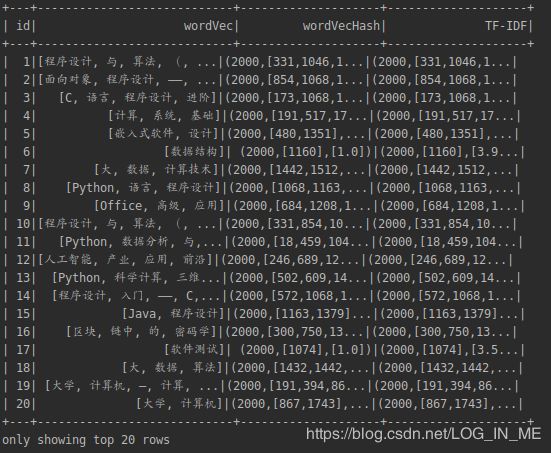
计算TF-IDF词袋:
//计算TF-IDF词袋
val idf = new IDF()
.setInputCol("wordVecHash")
.setOutputCol("TF-IDF")
val idfModel = idf.fit(featureVec)
val TFIDFResult = idfModel.transform(featureVec)
TFIDFResult.show()