Conditional Random Field
作者:milter
链接:https://www.jianshu.com/p/55755fc649b1
來源:简书
-
- 1 从例子说起——词性标注问题
- 2 定义CRF中的特征函数
- 3 从特征函数到概率
- 4 几个特征函数的例子
- 5 CRF与逻辑回归的比较
- 6 CRF与HMM的比较
假设你有许多小明同学一天内不同时段的照片,从小明提裤子起床到脱裤子睡觉各个时间段都有(小明是照片控!)。现在的任务是对这些照片进行分类。比如有的照片是吃饭,那就给它打上吃饭的标签;有的照片是跑步时拍的,那就打上跑步的标签;有的照片是开会时拍的,那就打上开会的标签。问题来了,你准备怎么干?
一个简单直观的办法就是,不管这些照片之间的时间顺序,想办法训练出一个多元分类器。就是用一些打好标签的照片作为训练数据,训练出一个模型,直接根据照片的特征来分类。例如,如果照片是早上6:00拍的,且画面是黑暗的,那就给它打上睡觉的标签;如果照片上有车,那就给它打上开车的标签。
这样可行吗?
乍一看可以!但实际上,由于我们忽略了这些照片之间的时间顺序这一重要信息,我们的分类器会有缺陷的。举个例子,假如有一张小明闭着嘴的照片,怎么分类?显然难以直接判断,需要参考闭嘴之前的照片,如果之前的照片显示小明在吃饭,那这个闭嘴的照片很可能是小明在咀嚼食物准备下咽,可以给它打上吃饭的标签;如果之前的照片显示小明在唱歌,那这个闭嘴的照片很可能是小明唱歌瞬间的抓拍,可以给它打上唱歌的标签。
所以,为了让我们的分类器能够有更好的表现,在为一张照片分类时,我们必须将与它相邻的照片的标签信息考虑进来。这就是条件随机场(CRF)大显身手的地方!
1 从例子说起——词性标注问题
1)啥是词性标注问题?
非常简单的,就是给一个句子中的每个单词注明词性。比如这句话:“Bob drank coffee at Starbucks”,注明每个单词的词性后是这样的:“Bob (名词) drank(动词) coffee(名词) at(介词) Starbucks(名词)”。
下面,就用条件随机场来解决这个问题。
以上面的话为例,有5个单词,我们将:(名词,动词,名词,介词,名词)作为一个标注序列,称为 l l ,可选的标注序列有很多种,比如 l l 还可以是这样:(名词,动词,动词,介词,名词),我们要在这么多的可选标注序列中,挑选出一个最靠谱的作为我们对这句话的标注。
2)怎么判断一个标注序列靠谱不靠谱呢?
就我们上面展示的两个标注序列来说,第二个显然不如第一个靠谱,因为它把第二、第三个单词都标注成了动词,动词后面接动词,这在一个句子中通常是说不通的。
假如我们给每一个标注序列打分,打分越高代表这个标注序列越靠谱,我们至少可以说,凡是标注中出现了动词后面还是动词的标注序列,要给它负分!!
上面所说的动词后面还是动词就是一个特征函数,我们可以定义一个特征函数集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。也就是说,每一个特征函数都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。
2 定义CRF中的特征函数
现在,我们正式地定义一下什么是CRF中的特征函数,所谓特征函数,就是这样的函数,它接受四个参数:
句子 s s (就是我们要标注词性的句子)
i i ,用来表示句子s中第i个单词
li l i ,表示要评分的标注序列给第 i i 个单词标注的词性
li−1 l i − 1 ,表示要评分的标注序列给第 i−1 i − 1 个单词标注的词性
它的输出值是0或者1,0表示要评分的标注序列不符合这个特征,1表示要评分的标注序列符合这个特征。
Note:这里,我们的特征函数仅仅依靠当前单词的标签和它前面的单词的标签对标注序列进行评判,这样建立的CRF也叫作线性链CRF,这是CRF中的一种简单情况。为简单起见,本文中我们仅考虑线性链CRF。
3 从特征函数到概率
定义好一组特征函数后,我们要给每个特征函数 fj f j 赋予一个权重 λj λ j 。现在,只要有一个句子 s s ,有一个标注序列l,我们就可以利用前面定义的特征函数集来对 l l 评分。
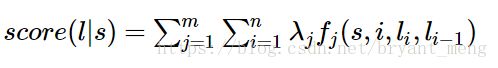
上式中有两个求和,外面的求和用来求每一个特征函数 fj f j 评分值的和,里面的求和用来求句子中每个位置的单词的的特征值的和。
对这个分数进行指数化和标准化,我们就可以得到标注序列l的概率值 p(l|s) p ( l | s ) ,如下所示:
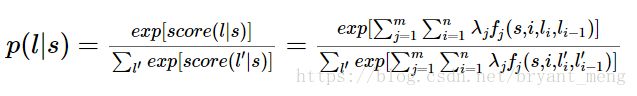
4 几个特征函数的例子
当 li l i 是“副词”并且第 i i 个单词以 “ ly l y ” 结尾时,我们就让 f1=1 f 1 = 1 ,其他情况 f1 f 1 为0。不难想到, f1 f 1 特征函数的权重 λ1 λ 1 应当是正的。而且 λ1 λ 1 越大,表示我们越倾向于采用那些把以“ ly l y ” 结尾的单词标注为“副词”的标注序列
如果 i=1 i = 1 , li l i = 动词,并且句子 s s 是以“?”结尾时, f2=1 f 2 = 1 ,其他情况 f2=0 f 2 = 0 。同样, λ2 λ 2 应当是正的,并且 λ2 λ 2 越大,表示我们越倾向于采用那些把问句的第一个单词标注为“动词”的标注序列。
当 li−1 l i − 1 是介词, li l i 是名词时, f3=1 f 3 = 1 ,其他情况 f3=0 f 3 = 0 。 λ3 λ 3 也应当是正的,并且 λ3 λ 3 越大,说明我们越认为介词后面应当跟一个名词。
如果 li l i 和 li−1 l i − 1 都是介词,那么 f4=1 f 4 = 1 ,其他情况 f4=1 f 4 = 1 。这里,我们应当可以想到 λ3 λ 3 是负的,并且 λ4 λ 4 的绝对值越大,表示我们越不认可介词后面还是介词的标注序列。
好了,一个条件随机场就这样建立起来了,让我们总结一下:
为了建一个条件随机场,我们首先要定义一个特征函数集,每个特征函数都以整个句子 s s ,当前位置 i i ,位置 i i 和 i−1 i − 1 的标签为输入。然后为每一个特征函数赋予一个权重,然后针对每一个标注序列 l l ,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值。
5 CRF与逻辑回归的比较
观察公式:
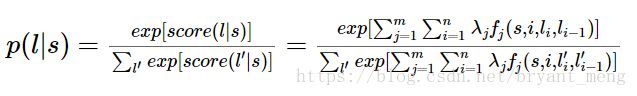
是不是有点逻辑回归的味道?
事实上,条件随机场是逻辑回归的序列化版本。逻辑回归是用于分类的对数线性模型,条件随机场是用于序列化标注的对数线性模型。
6 CRF与HMM的比较
用一句话来说明HMM和CRF的关系就是这样:
每一个HMM模型都等价于某个CRF
每一个HMM模型都等价于某个CRF
每一个HMM模型都等价于某个CRF
但是,CRF要比HMM更加强大,原因主要有两点:
1) CRF可以定义数量更多,种类更丰富的特征函数。HMM模型具有天然具有局部性,就是说,在HMM模型中,当前的单词只依赖于当前的标签,当前的标签只依赖于前一个标签。这样的局部性限制了HMM只能定义相应类型的特征函数,我们在上面也看到了。但是CRF却可以着眼于整个句子s定义更具有全局性的特征函数,如这个特征函数:
2) CRF中,每个特征函数的权重可以是任意值