Deep Learning的案例FasterRCNN(二)
二
- 训练流
- caffe版本的训练步骤
- 到底在学习什么东西?
- LossFunction
- 在caffe中的数据流
- 后记
训练流
caffe版本的训练步骤
- Step1-RPN.TRAIN
- Step1-RPN.PROPOSAL
- Step2-FASTRCNN.TRAIN
- Step3-RPN.TRAIN
- Step3-RPN.PROPOSAL
- Step4-FASTRCNN.TRAIN
到底在学习什么东西?
-
识别+小分类(是否有物体):RPN
-
识别方法:CNN特征提取+Bounding-Box回归
-
回归(学习)什么: 一种平面图形的映射 t : P → G ^ \mathbf{t}:\mathbf{P}\to \mathbf{\hat{G}} t:P→G^。
具体来说是把一个proposal( P \mathbf{P} P)形状变形成一个groundtruth( G ^ \mathbf{\hat{G}} G^)形状。已知函数形式,学习(求解)该函数的参数t = { G ^ x = P w t x ( P ) + P x G ^ y = P h t y ( P ) + P y G ^ w = P w e x p ( t w ( P ) ) G ^ h = P h e x p ( t h ( P ) ) \mathbf{t}=\left\{ \begin{array}{ll} \hat{G}_{x}=P_{w}t_{x}(\mathbf{P})+P_{x} & \textrm{}\\ \hat{G}_{y}=P_{h}t_{y}(\mathbf{P})+P_{y} & \textrm{}\\ \hat{G}_{w}=P_{w}exp(t_{w}(\mathbf{P})) & \textrm{}\\ \hat{G}_{h}=P_{h}exp(t_{h}(\mathbf{P})) & \textrm{}\\ \end{array} \right. t=⎩⎪⎪⎨⎪⎪⎧G^x=Pwtx(P)+PxG^y=Phty(P)+PyG^w=Pwexp(tw(P))G^h=Phexp(th(P))
对于每一个 t ∗ = w ∗ T ϕ ( P i ) t_{*}=\mathbf{w}_{*}^{T}\phi(\mathbf{P}^i) t∗=w∗Tϕ(Pi)
w ∗ = arg min w ^ ∗ ∑ i N ( t ∗ i − w ^ ∗ T ϕ ( P i ) ) 2 + λ ∣ ∣ w ^ ∗ ∣ ∣ 2 \mathbf{w}_{*}=\argmin\limits_{\hat{\mathbf{w}}_{*}}\sum^{N}_{i}(t^i_{*}-\hat{\mathbf{w}}_{*}^{T}\phi(\mathbf{P}^i))^2+\lambda||\hat{\mathbf{w}}_{*}||^2 w∗=w^∗argmini∑N(t∗i−w^∗Tϕ(Pi))2+λ∣∣w^∗∣∣2
LossFunction
注意这里的 v = w ^ ∗ T ϕ ( P i ) \mathbf{v}=\hat{\mathbf{w}}_{*}^{T}\phi(\mathbf{P}^i) v=w^∗Tϕ(Pi) ,即预测的变形函数的参数
L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ⩾ 1 ] L l o c ( t u , v ) L(\mathbf{p},u,\mathbf{t}^u,\mathbf{v})=L_{cls}(\mathbf{p},u)+\lambda[u\geqslant1]L_{loc}(\mathbf{t}^u,\mathbf{v}) L(p,u,tu,v)=Lcls(p,u)+λ[u⩾1]Lloc(tu,v)
L l o c ( t u , v ) = ∑ i ∈ { x , y , w , h } s m o o t h L 1 ( t i u , v i ) L_{loc}(\mathbf{t}^u,\mathbf{v})=\sum_{i\in\{x,y,w,h\}}smooth_{L_{1}}(t^u_{i},v_{i}) Lloc(tu,v)=i∈{x,y,w,h}∑smoothL1(tiu,vi)
s m o o t h L 1 ( x ) = { 0.5 ( σ x ) 2 if ∣ x ∣ < 1 σ 2 ∣ x ∣ − 0.5 σ 2 otherwise smooth_{L_{1}}(x)=\left\{ \begin{array}{ll} 0.5 (\sigma x)^2 & \textrm{ if } |x| < \frac{1}{\sigma ^2}\\ |x| - \frac{0.5 }{\sigma ^2} & \textrm{ otherwise}\\ \end{array} \right. smoothL1(x)={0.5(σx)2∣x∣−σ20.5 if ∣x∣<σ21 otherwise
在caffe中的数据流
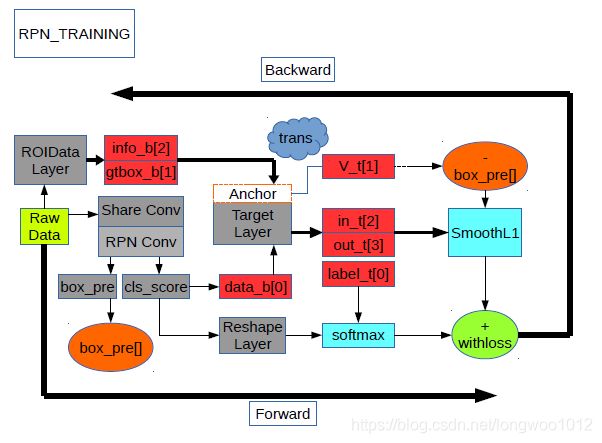
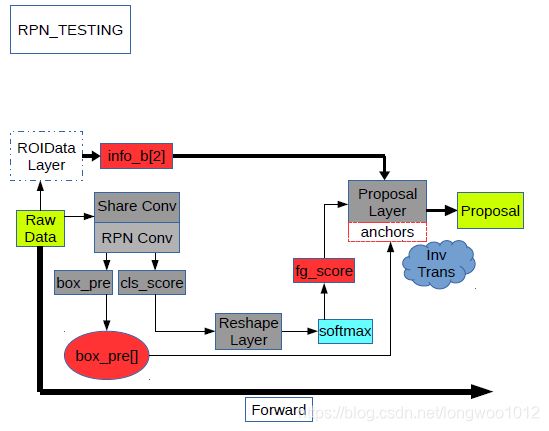
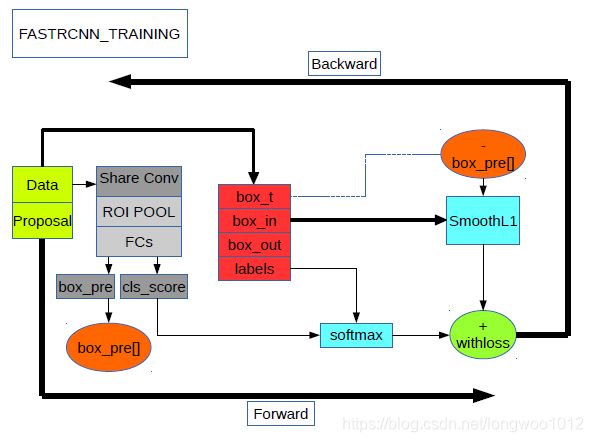
- 一张原始图片经过共享卷积层得到 b o t t o m [ 0 ] = [ . . . , W c , H c ] bottom[0]=[...,W_{c},H_{c}] bottom[0]=[...,Wc,Hc]
- ROIDataLayer从一张随机缩放过的图片中抽出所有的ROI区域,得到 b o t t o m [ 1 ] = g t b o x [ x 1 , y 1 , x 2 , y 2 , c l s ] ; b o t t o m [ 2 ] = [ W 0 , H , s c a l e ] bottom[1]=gtbox[x1,y1,x2,y2,cls];bottom[2]=[W_{0},H_{},scale] bottom[1]=gtbox[x1,y1,x2,y2,cls];bottom[2]=[W0,H,scale]
- AnchorTargetLayer在setup时原点处产生 A A A个anchor
- 在Forward中产生 W c ∗ H c W_{c}*H_{c} Wc∗Hc个shift值,通过shift偏移anchor共产生 A ∗ W c ∗ H c A*W_{c}*H_{c} A∗Wc∗Hc个 a l l _ a n c h o r s all\_anchors all_anchors
- 去掉 a l l _ a n c h o r s all\_anchors all_anchors中越界的anchor得到新的anchors
- 计算anchors与gtbox的overlap值,给anchors标记label,其中 > 0.7 , l a b e l = 1 ; < 0.3 , l a b e l = 0 ; o t h e r , l a b e l = − 1 >0.7,label=1;<0.3,label=0;other,label=-1 >0.7,label=1;<0.3,label=0;other,label=−1给 t o p [ 0 ] top[0] top[0]
- 抽取256个anchors的样本数,正负样本保持1:1
- 计算 v \mathbf{v} v,给 t o p [ 1 ] top[1] top[1];计算 u u u,给 t o p [ 2 ] top[2] top[2];计算 λ \lambda λ,给 t o p [ 3 ] top[3] top[3]
- Backward反向传播,更新权值
这些细节数据流程现在来看都有些模糊了,映像最深的还是那个变形函数的映射建立,说明带问题式搜索解答才是最有效率的。
后记
当年做到这里考虑的可以改造的思路
- 替换数据集?
- 替换共享卷积层?
- 替换回归函数?
- 多路输出+deepmusk+shapemusk=multipathnet?
这个时候就是看谁的动手能力强以及实验环境条件了。现在这个系列已经出到了MaskRCNN,甚至全部直接集成到Detectron2,也就意味着这一波用网络方法改造原有hardcoding视觉识别基础层的小高峰完成了。待其被各种花式应用探索潜力以后,应用层又会嗷嗷待哺,等待新一波的高峰到来。
- [1] Fast R-CNN - [2] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. - [3] https://www.jianshu.com/p/1f975b05ca86 - [4] https://www.jianshu.com/p/5056e6143ed5 - [5] https://www.jianshu.com/p/ab1ebddf58b1