Datawhale_数据分析组队学习task8
绘图和可视化
- Matplotlib API入门
- Figure和Subplot
- 调整subplot周围的间距
- 颜色、标记和线型
- 设置标题、轴标签、刻度以及刻度标签
- 添加图例
- 注解以及在Subplot上绘图
- 将图表保存到文件
- 使用pandas和seaborn绘图
- 线型图
- 柱状图
- 直方图和密度图
- 散布图或点图
- 分面网格(facet grid)和类型数据
Matplotlib API入门
import matplotlib.pyplot as plt
import numpy as np
data = np.arange(10)
plt.plot(data)

Figure和Subplot
# matplotlib图像位于Figure对象中,plt.figure创建一个新的Figure
fig = plt.figure()
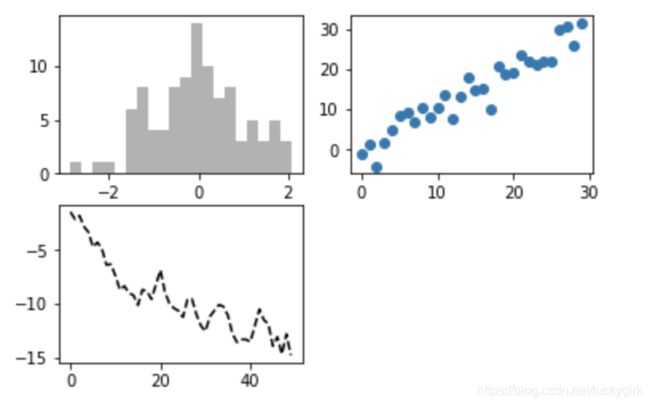
# 创建带有三个subplot的Figure
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
# 最后一个subplot执行绘图命令
plt.plot(np.random.randn(50).cumsum(),'k--')
ax1.hist(np.random.randn(100),bins = 20,color = 'k',alpha = 0.3)
ax2.scatter(np.arange(30),np.arange(30) + 3 * np.random.randn(30))
调整subplot周围的间距
subplots_adjust(left=None, bottom=None, right=None, top=None,wspace=None, hspace=None)
- wspace 和 hspace 用于控制宽度和高度的百分比
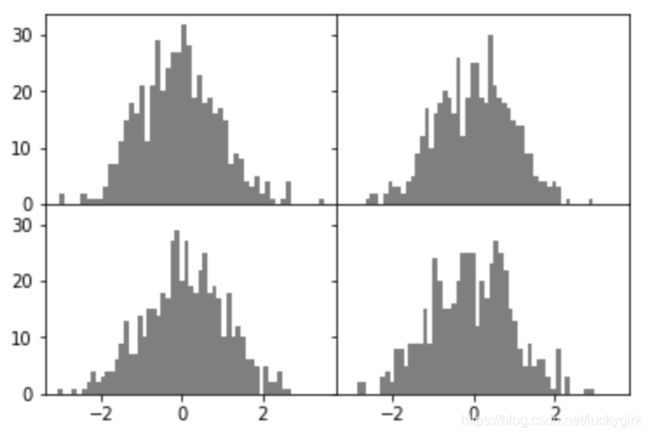
# 将间距收缩到0
fig,axes = plt.subplots(2,2,sharex = True,sharey = True)
for i in range(2):
for j in range(2):
axes[i,j].hist(np.random.randn(500),bins = 50,color = 'k',alpha = 0.5)
plt.subplots_adjust(wspace =0,hspace = 0)
颜色、标记和线型
在一个字符串中指定颜色和线型
ax.plot(x, y, linestyle='--', color='g')
from numpy.random import randn
plt.plot(randn(30).cumsum(),'ko--')

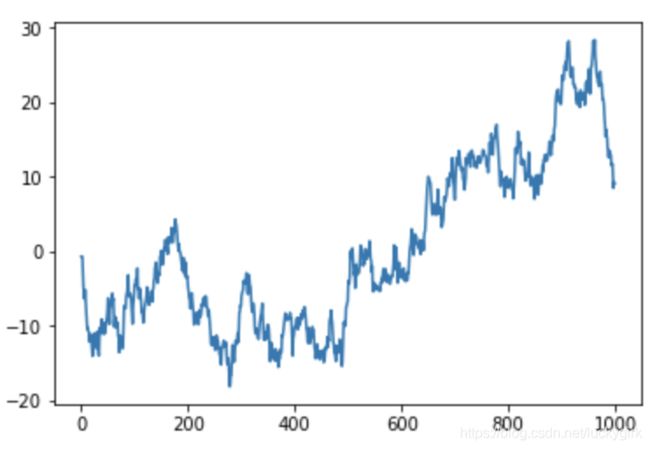
设置标题、轴标签、刻度以及刻度标签
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(np.random.randn(1000).cumsum())
# set_xticks和set_xticklables改变x轴刻度
ticks = ax.set_xticks([0,250,500,750,1000])
labels = ax.set_xticklabels(['one','two','three','four','five'],rotation = 30,fontsize = 'small') # rotation设定x刻度标签倾斜30度
ax.set_title('My first matplotlib plot')
ax.set_xlabel('Stages')
轴的类集合方法批量设置绘图选项
props = {
'title': 'My first matplotlib plot',
'xlabel': 'Stages',
'ylabel': 'Stages2',
}
ax.set(**props)
添加图例
# 添加subplot时传入label参数
from numpy.random import randn
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(randn(1000).cumsum(),'k',label = 'one')
ax.plot(randn(1000).cumsum(),'k--',label = 'two')
ax.plot(randn(1000).cumsum(),'k.',label = 'three')
# 调用ax.ledend()或plt.legend()自动创建图例
ax.legend(loc = 'beat') # loc设置图例位置

注解以及在Subplot上绘图
text 可以将文本绘制在图表的指定坐标(x,y),还可以加上一些自定义格式:
ax.text(x, y, 'Hello world!',family='monospace', fontsize=10
from datetime import datetime
import pandas as pd
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
data = pd.read_csv(r'/Users/faye/Desktop/examples/spx.csv',index_col = 0,parse_dates = True)
spx= data['SPX']
spx.plot(ax = ax,style = 'k-')
crisis_data = [
(datetime(2007, 10, 11), 'Peak of bull market'),
(datetime(2008, 3, 12), 'Bear Stearns Fails'),
(datetime(2008, 9, 15), 'Lehman Bankruptcy')
]
for date, label in crisis_data:
ax.annotate(label, xy=(date, spx.asof(date) + 75),
xytext=(date, spx.asof(date) + 225),
arrowprops=dict(facecolor='black', headwidth=4,width=2,headlength=4),
horizontalalignment='left', verticalalignment='top')
ax.set_xlim(['1/1/2007', '1/1/2011'])
ax.set_ylim([600, 1800])
ax.set_title('Important dates in the 2008-2009 financial crisis')

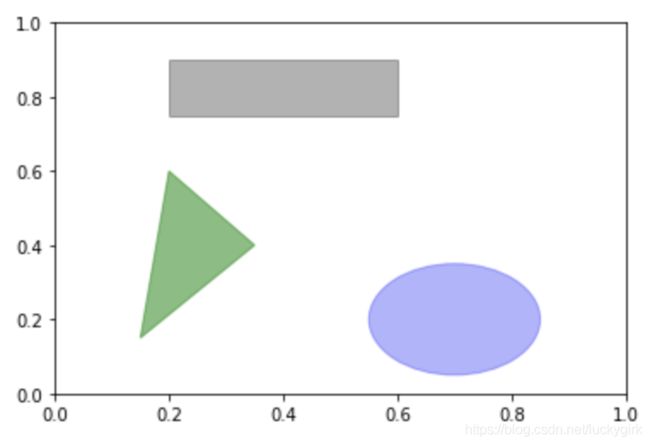
# 在图表中创建图形
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
rect = plt.Rectangle((0.2, 0.75), 0.4, 0.15, color='k', alpha=0.3)
circ = plt.Circle((0.7, 0.2), 0.15, color='b', alpha=0.3)
pgon = plt.Polygon([[0.15, 0.15], [0.35, 0.4], [0.2, 0.6]],color='g', alpha=0.5)
ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon)
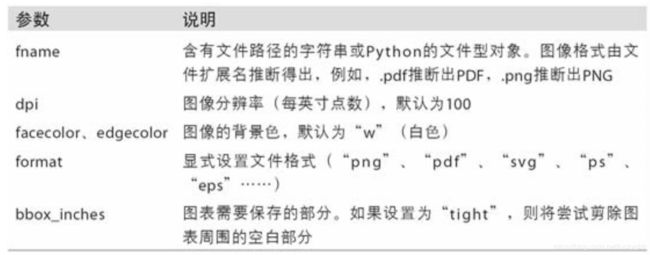
将图表保存到文件
将图表保存为 SVG 文件
plt.savefig('figpath.svg')
将图表保存为 设置分辨率的PNG图片
plt.savefig('figpath.png', dpi=400, bbox_inches='tight')
savefig参数选项:
使用pandas和seaborn绘图
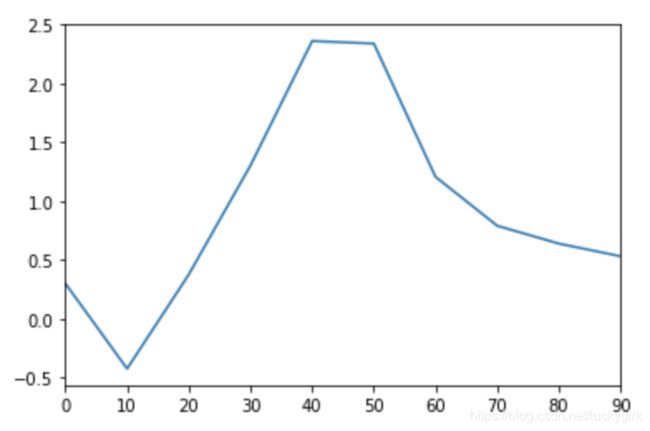
线型图
s = pd.Series(np.random.randn(10).cumsum(),index=np.arange(0, 100, 10))
s.plot()
 plot参数列表:
plot参数列表:

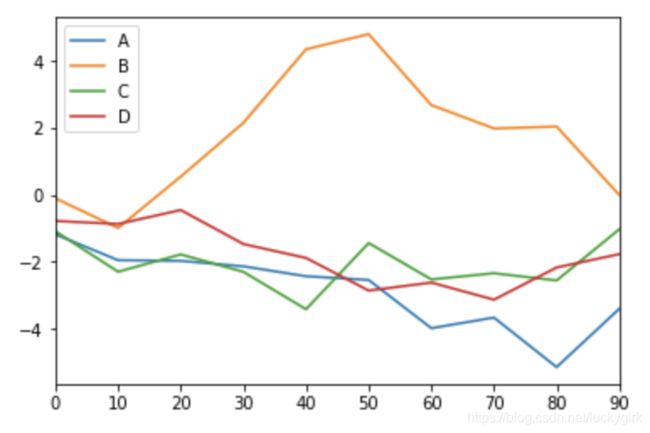
# DataFrame 的 plot 方法会在一个 subplot 中为各列绘制一条线,并自动创建图 例
df = pd.DataFrame(np.random.randn(10, 4).cumsum(0),columns=['A', 'B', 'C', 'D'],index=np.arange(0, 100, 10))
df.plot()
DataFrame的plot参数

柱状图
plot.bar()和 plot.barh()分别绘制水平和垂直的柱状图,Series 和 DataFrame 的索引将会被用作 X(bar)或 Y(barh)刻度
fig, axes = plt.subplots(2, 1)
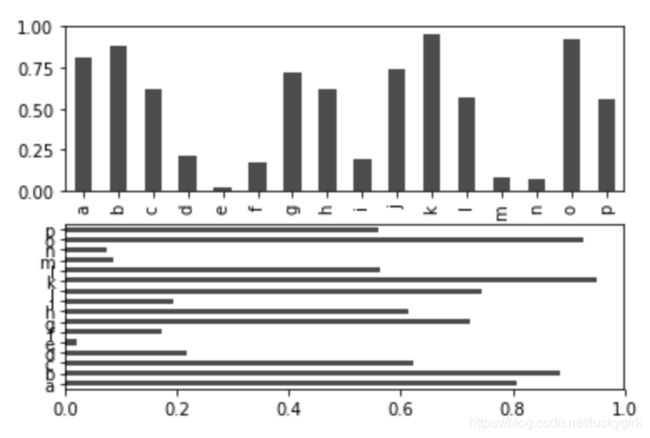
data = pd.Series(np.random.rand(16),index=list('abcdefghijklmnop'))
data.plot.bar(ax=axes[0], color='k', alpha=0.7)
data.plot.barh(ax=axes[1], color='k', alpha=0.7)
# 对于DataFrame,柱状图将每一行的值分为一组
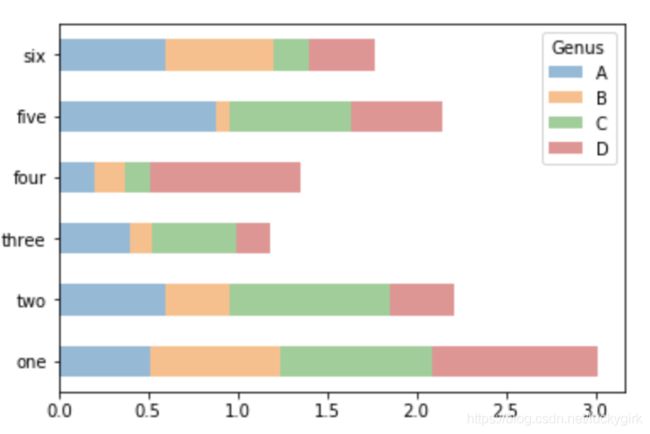
df = pd.DataFrame(np.random.rand(6, 4),index=['one', 'two', 'three', 'four','five', 'six'],columns=pd.Index(['A', 'B', 'C', 'D'],name='Genus'))
df.plot.bar()

# 设置 stacked=True为 DataFrame 生成堆积柱状图
df.plot.barh(stacked=True, alpha=0.5)
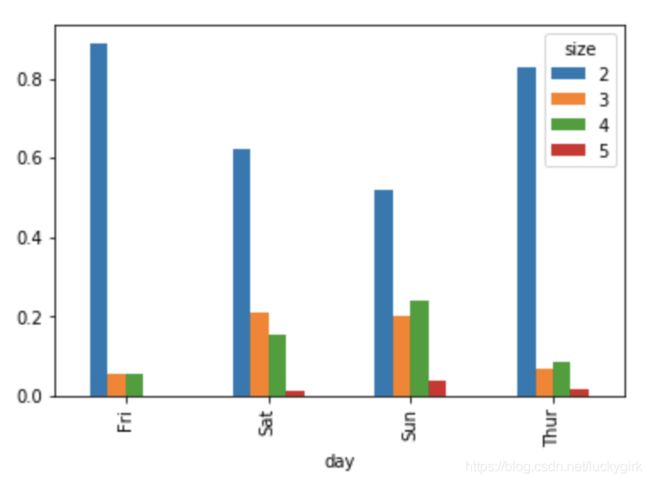
#利用 value_counts 图形化显示 Series中各值的出现频率
tips = pd.read_csv(r'/Users/faye/Desktop/examples/tips.csv')
party_counts = pd.crosstab(tips['day'], tips['size'])
party_counts = party_counts.loc[:, 2:5]
party_pcts = party_counts.div(party_counts.sum(1), axis=0)
party_pcts.plot.bar()
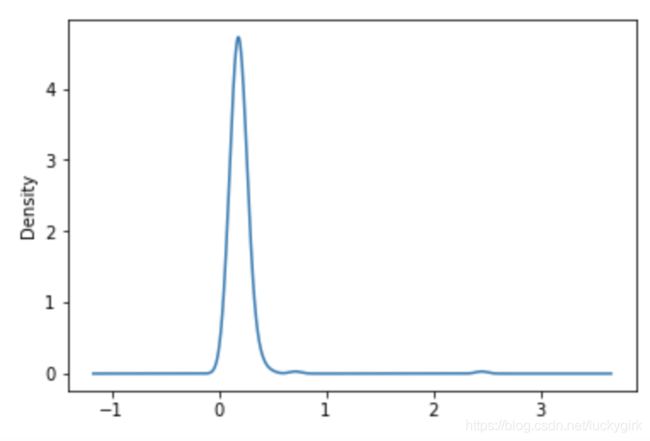
直方图和密度图
import seaborn as sns
tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip'])
tips['tip_pct'].plot.hist(bins=50)

tips['tip_pct'].plot.density()
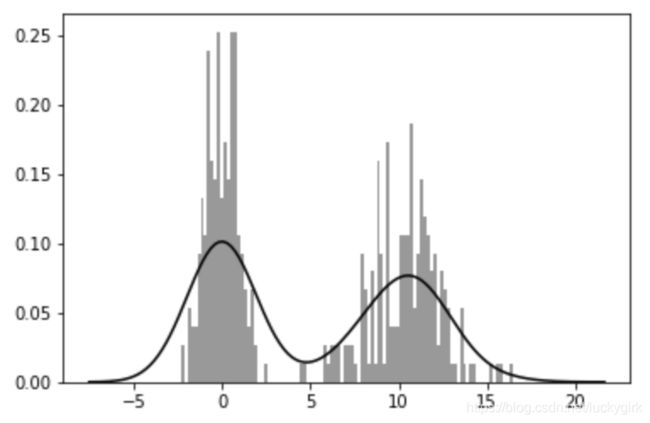
comp1 = np.random.normal(0, 1, size=200)
comp2 = np.random.normal(10, 2, size=200)
values = pd.Series(np.concatenate([comp1, comp2]))
sns.distplot(values, bins=100, color='k')
散布图或点图
macro = pd.read_csv(r'/Users/faye/Desktop/examples/macrodata.csv')
data = macro[['cpi', 'm1', 'tbilrate', 'unemp']]
trans_data = np.log(data).diff().dropna()
trans_data[-5:]
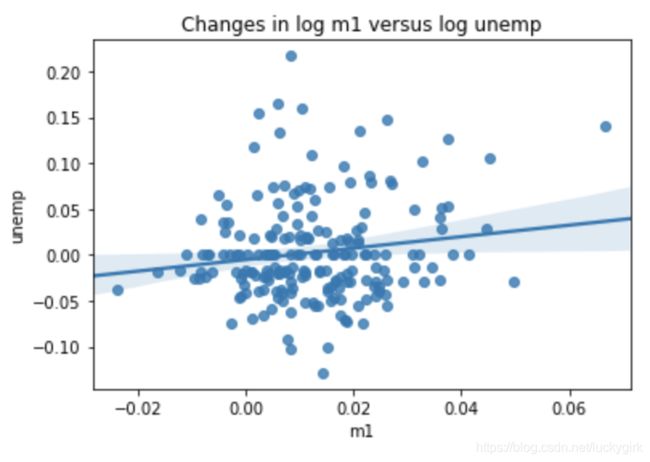
# seaborn的regplot方法做散点图,并加一条线性回归的线
sns.regplot('m1', 'unemp', data=trans_data)
plt.title('Changes in log %s versus log %s' % ('m1','unemp'))
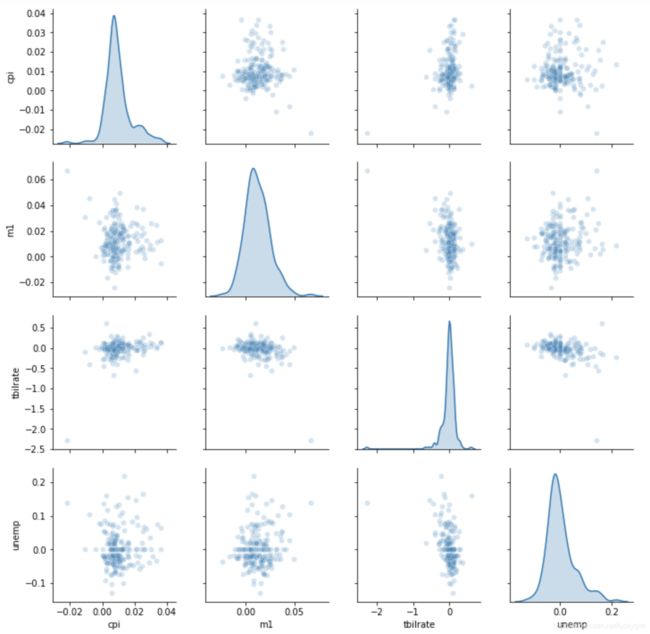
# 散点图矩阵
sns.pairplot(trans_data, diag_kind='kde',plot_kws={'alpha': 0.2})
分面网格(facet grid)和类型数据
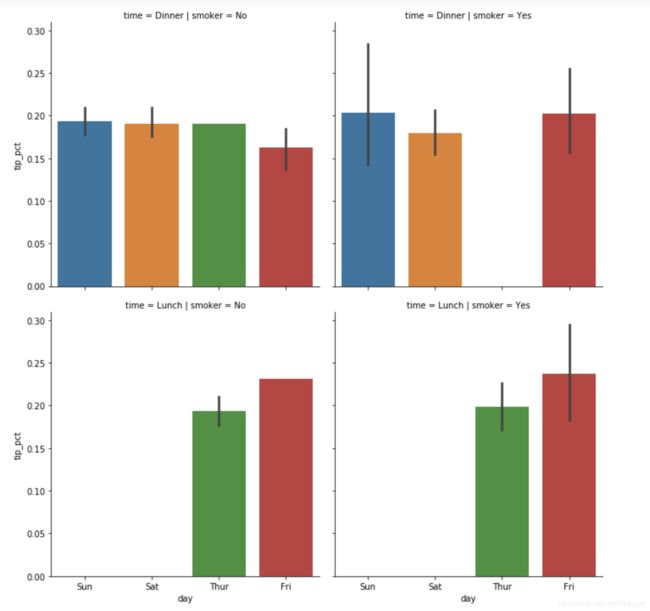
sns.factorplot(x='day', y='tip_pct', hue='time',col='smoker',kind='bar', data=tips[tips.tip_pct < 1])
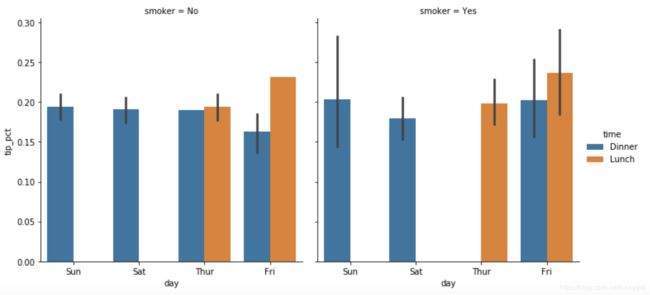
sns.factorplot(x='day', y='tip_pct', hue='time',col='smoker',kind='bar', data=tips[tips.tip_pct < 1])
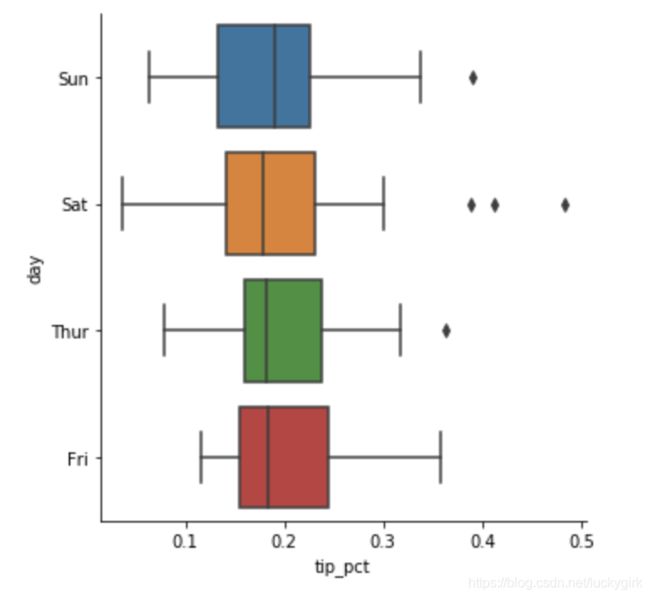
# 盒图
sns.factorplot(x='tip_pct', y='day', kind='box',data=tips[tips.tip_pct < 0.5])