前言
最近在做一个项目,需要对webRTC录制的音频进行处理,包括音频的裁剪、多音频合并,甚至要将某个音频的某一部分替换成另一个音频。
原本笔者打算将这件工作交给服务端去完成,但考虑,其实无论是前端还是后台,所做的工作是差不多的,而且交给服务端还需要再额外走一个上传、下载音频的流程,这不仅增添了服务端的压力,而且还有网络流量的开销,于是萌生出一个想法:为什么音频处理这件事不能让前端来做呢?
于是在笔者的半摸索半实践下,产生出了这篇文章。废话少说,先上仓库地址,这是一个开箱即用的前端音频剪辑sdk(点进去了不如就star一下吧)
ffmpeg
ffmpeg是实现前端音频处理的非常核心的模块,当然,不仅是前端,ffmpge作为一个提供了录制、转换以及流化音视频的业界成熟完整解决方案,它也应用在服务端、APP应用等多种场景下。关于ffmpeg的介绍,大家自行google即可,这里不说太多。
由于ffmpeg在处理过程中需要大量的计算,直接放在前端页面上去运行是不可能的,因为我们需要单独开个web worker,让它自己在worker里面运行,而不至于阻塞页面交互。
可喜的是,万能的github上已经有开发者提供了ffmpge.js,并且提供worker版本,可以拿来直接使用。
于是我们便有了大体的思路:当获取到音频文件后,将其解码后传送给worker,让其进行计算处理,并将处理结果以事件的方式返回,这样我们就可以对音频为所欲为了:)
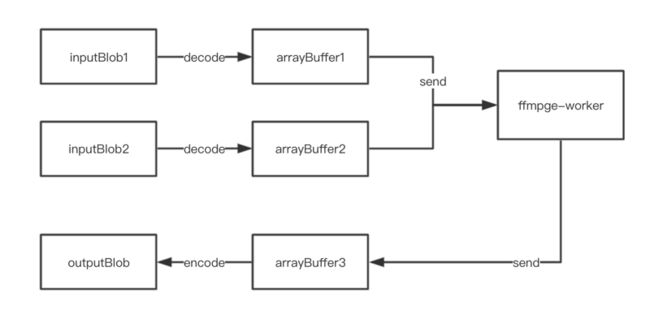
开启美妙之旅前的必要工作
需要提前声明的是,由于笔者的项目需求,是仅需对.mp3格式进行处理的,因此下面的代码示例以及仓库地址里面所涉及的代码,也主要是针对mp3,当然,其实不管是哪种格式,思路是类似的。
创建worker
创建worker的方式非常简单,直接new之,注意的是,由于同源策略的限制,要使worker正常工作,则要与父页面同源,由于这不是重点,所以略过
function createWorker(workerPath: string) {
const worker = new Worker(workerPath);
return worker;
}postMessage转promise
仔细看ffmpeg.js文档的童鞋都会发现,它在处理音频的不同阶段都会发射事件给父页面,比如stdout,start和done等等,如果直接为这些事件添加回调函数,在回调函数里去区分、处理一个又一个音频的结果,是不大好维护的。个人更倾向于将其转成promise:
function pmToPromise(worker, postInfo) {
return new Promise((resolve, reject) => {
// 成功回调
const successHandler = function(event) {
switch (event.data.type) {
case "stdout":
console.log("worker stdout: ", event.data.data);
break;
case "start":
console.log("worker receive your command and start to work:)");
break;
case "done":
worker.removeEventListener("message", successHandler);
resolve(event);
break;
default:
break;
}
};
// 异常捕获
const failHandler = function(error) {
worker.removeEventListener("error", failHandler);
reject(error);
};
worker.addEventListener("message", successHandler);
worker.addEventListener("error", failHandler);
postInfo && worker.postMessage(postInfo);
});
}通过这层转换,我们就可以将一次postMessage请求,转换成了promise的方式来处理,更易于空间上的拓展
audio、blob与arrayBuffer的互相转换
ffmpeg-worker所需要的数据格式是arrayBuffer,而一般我们能直接使用的,要么是音频文件对象blob,或者音频元素对象audio,甚至有可能仅是一条链接url,因此这几种格式的转换是非常有必要的:
audio转arrayBuffer
function audioToBlob(audio) {
const url = audio.src;
if (url) {
return axios({
url,
method: 'get',
responseType: 'arraybuffer',
}).then(res => res.data);
} else {
return Promise.resolve(null);
}
}笔者暂时想到的audio转blob的方式,就是发起一段ajax请求,将请求类型设置为arraybuffer,即可拿到arrayBuffer.
blob转arrayBuffer
这个也很简单,只需要借助FileReader将blob内容提取出来即可
function blobToArrayBuffer(blob) {
return new Promise(resolve => {
const fileReader = new FileReader();
fileReader.onload = function() {
resolve(fileReader.result);
};
fileReader.readAsArrayBuffer(blob);
});
}arrayBuffer转blob
利用File创建出一个blob
function audioBufferToBlob(arrayBuffer) {
const file = new File([arrayBuffer], 'test.mp3', {
type: 'audio/mp3',
});
return file;
}blob转audio
blob转audio是非常简单的,js提供了一个原生API——URL.createObjectURL,借助它我们可以把blob转成本地可访问链接进行播放
function blobToAudio(blob) {
const url = URL.createObjectURL(blob);
return new Audio(url);
}接下来我们进入正题。
音频裁剪——clip
所谓裁剪,即是指将给定的音频,按给定的起始、结束时间点,提取这部分的内容,形成新的音频,先上代码:
class Sdk {
end = "end";
// other code...
/**
* 将传入的一段音频blob,按照指定的时间位置进行裁剪
* @param originBlob 待处理的音频
* @param startSecond 开始裁剪时间点(秒)
* @param endSecond 结束裁剪时间点(秒)
*/
clip = async (originBlob, startSecond, endSecond) => {
const ss = startSecond;
// 获取需要裁剪的时长,若不传endSecond,则默认裁剪到末尾
const d = isNumber(endSecond) ? endSecond - startSecond : this.end;
// 将blob转换成可处理的arrayBuffer
const originAb = await blobToArrayBuffer(originBlob);
let resultArrBuf;
// 获取发送给ffmpge-worker的指令,并发送给worker,等待其裁剪完成
if (d === this.end) {
resultArrBuf = (await pmToPromise(
this.worker,
getClipCommand(originAb, ss)
)).data.data.MEMFS[0].data;
} else {
resultArrBuf = (await pmToPromise(
this.worker,
getClipCommand(originAb, ss, d)
)).data.data.MEMFS[0].data;
}
// 将worker处理过后的arrayBuffer包装成blob,并返回
return audioBufferToBlob(resultArrBuf);
};
}我们定义了该接口的三个参数:需要被剪裁的音频blob,以及裁剪的开始、结束时间点,值得注意的是这里的getClipCommand函数,它负责将传入的arrayBuffer、时间包装成ffmpeg-worker约定的数据格式
/**
* 按ffmpeg文档要求,将带裁剪数据转换成指定格式
* @param arrayBuffer 待处理的音频buffer
* @param st 开始裁剪时间点(秒)
* @param duration 裁剪时长
*/
function getClipCommand(arrayBuffer, st, duration) {
return {
type: "run",
arguments: `-ss ${st} -i input.mp3 ${
duration ? `-t ${duration} ` : ""
}-acodec copy output.mp3`.split(" "),
MEMFS: [
{
data: new Uint8Array(arrayBuffer),
name: "input.mp3"
}
]
};
}多音频合成——concat
多音频合成很好理解,即将多个音频按数组先后顺序合并成一个音频
class Sdk {
// other code...
/**
* 将传入的一段音频blob,按照指定的时间位置进行裁剪
* @param blobs 待处理的音频blob数组
*/
concat = async blobs => {
const arrBufs = [];
for (let i = 0; i < blobs.length; i++) {
arrBufs.push(await blobToArrayBuffer(blobs[i]));
}
const result = await pmToPromise(
this.worker,
await getCombineCommand(arrBufs),
);
return audioBufferToBlob(result.data.data.MEMFS[0].data);
};
}上述代码中,我们是通过for循环来将数组里的blob一个个解码成arrayBuffer,可能有童鞋会好奇:为什么不直接使用数组自带的forEach方法去遍历呢?写for循环未免麻烦了点。其实是有原因的:我们在循环体里使用了await,是期望这些blob一个个解码完成后,才执行后面的代码,for循环是同步执行的,但forEach的每个循环体是分别异步执行的,我们无法通过await的方式等待它们全部执行完成,因此使用forEach并不符合我们的预期。
同样,getCombineCommand函数的职责与上述getClipCommand类似:
async function getCombineCommand(arrayBuffers) {
// 将arrayBuffers分别转成ffmpeg-worker指定的数据格式
const files = arrayBuffers.map((arrayBuffer, index) => ({
data: new Uint8Array(arrayBuffer),
name: `input${index}.mp3`,
}));
// 创建一个txt文本,用于告诉ffmpeg我们所需进行合并的音频文件有哪些(类似这些文件的一个映射表)
const txtContent = [files.map(f => `file '${f.name}'`).join('\n')];
const txtBlob = new Blob(txtContent, { type: 'text/txt' });
const fileArrayBuffer = await blobToArrayBuffer(txtBlob);
// 将txt文件也一并推入到即将发送给ffmpeg-worker的文件列表中
files.push({
data: new Uint8Array(fileArrayBuffer),
name: 'filelist.txt',
});
return {
type: 'run',
arguments: `-f concat -i filelist.txt -c copy output.mp3`.split(' '),
MEMFS: files,
};
}在上面代码中,与裁剪操作不同的是,被操作的音频对象不止一个,而是多个,因此需要创建一个“映射表”去告诉ffmpeg-worker一共需要合并哪些音频以及它们的合并顺序。
音频裁剪替换——splice
它有点类似clip的升级版,我们从指定的位置删除音频A,并在此处插入音频B:
class Sdk {
end = "end";
// other code...
/**
* 将一段音频blob,按指定的位置替换成另一端音频
* @param originBlob 待处理的音频blob
* @param startSecond 起始时间点(秒)
* @param endSecond 结束时间点(秒)
* @param insertBlob 被替换的音频blob
*/
splice = async (originBlob, startSecond, endSecond, insertBlob) => {
const ss = startSecond;
const es = isNumber(endSecond) ? endSecond : this.end;
// 若insertBlob不存在,则仅删除音频的指定内容
insertBlob = insertBlob
? insertBlob
: endSecond && !isNumber(endSecond)
? endSecond
: null;
const originAb = await blobToArrayBuffer(originBlob);
let leftSideArrBuf, rightSideArrBuf;
// 将音频先按指定位置裁剪分割
if (ss === 0 && es === this.end) {
// 裁剪全部
return null;
} else if (ss === 0) {
// 从头开始裁剪
rightSideArrBuf = (await pmToPromise(
this.worker,
getClipCommand(originAb, es)
)).data.data.MEMFS[0].data;
} else if (ss !== 0 && es === this.end) {
// 裁剪至尾部
leftSideArrBuf = (await pmToPromise(
this.worker,
getClipCommand(originAb, 0, ss)
)).data.data.MEMFS[0].data;
} else {
// 局部裁剪
leftSideArrBuf = (await pmToPromise(
this.worker,
getClipCommand(originAb, 0, ss)
)).data.data.MEMFS[0].data;
rightSideArrBuf = (await pmToPromise(
this.worker,
getClipCommand(originAb, es)
)).data.data.MEMFS[0].data;
}
// 将多个音频重新合并
const arrBufs = [];
leftSideArrBuf && arrBufs.push(leftSideArrBuf);
insertBlob && arrBufs.push(await blobToArrayBuffer(insertBlob));
rightSideArrBuf && arrBufs.push(rightSideArrBuf);
const combindResult = await pmToPromise(
this.worker,
await getCombineCommand(arrBufs)
);
return audioBufferToBlob(combindResult.data.data.MEMFS[0].data);
};
}上述代码有点类似clip和concat的复合使用。
到这里,就基本实现了我们的需求,仅需借助worker,前端自己也能处理音频,岂不美哉?
上述这些代码只是为了更好的说明讲解,所以做了些简化,有兴趣的童鞋可直接源码,欢迎交流、拍砖:)